




个人其他博客地址:
简书:https://www.jianshu.com/u/d6960089b087
掘金:https://juejin.cn/user/2963939079225608
小钟同学 | 文 【原创】| QQ:308711822
1:本文相关描述主要是个人的认知和见解,如有不当之处,还望各位大佬指正。 2:关于文章内容,有部分内容参考自互联网,如有链接会声明标注;如没有及时标注备注的链接的,如有侵权请联系,我会立即删除处理哟。
1 前言
上一小节里有说到生成器,但是生成器的应用场景很多,上一小节也没铺开。如:yield from的具体用法.
本节参考了大量网络资料结合自己的实践和思考整理而成。
2 再谈yield
2.1 yield 和 return的有什么区别?
对于函数式生成器来说,细想来有些时候我们的生成器其实也可以理解为一个函数的暂停和继续一个状态切换一样。yield也就是实现这个功能。它是一种使用非常优雅的方式封装好__iter__,__next__的一个关键字。
但是 yield 和 return的有着本质的区别:
yield 返回的只是生成器里面一个结果对象(单纯只是一个对象),如[1,2,3,] 中我只取返回的是一个列表里面的元素, 遇到了yield 返回我就当前的迭代值,然后下一次的时候,取下一个迭代值。 而return 虽然我们也可以只是返回[1,2,3,] 中的一个[1],但是无法进行下一次迭代循环的时候下一个值。
2.2 for循环和使用next()有区别吗?
首先返回生成器本身的时候需要赋值一个变量,才可以返回那个迭代器的对象。
如下示例:
def get_list_02():
yield '1号'
yield '2号'
yield '3号'
print(get_list_02().__next__()) # 输出的 1号
print(get_list_02().__next__()) # 输出的 1号
因为get_list_02()每次返回都是新的迭代器对象。所以每次调用的时候都是从第一个开始。
def get_list_02():
yield '1号'
yield '2号'
yield '3号'
mygen = get_list_02()
print(mygen.__next__()) #输出 1号
print(mygen.__next__()) #输出 2号
或者还有一种方式就是:
def get_list_02():
yield '1号'
yield '2号'
yield '3号'
mygen = get_list_02()
print(mygen.__iter__().__next__())#输出 1号
print(mygen.__iter__().__next__())#输出 2号
或者直接使用next()
def get_list_02():
yield '1号'
yield '2号'
yield '3号'
mygen = get_list_02()
print(next(mygen)) # 输出 1号
print(next(mygen)) # 输出 2号
或者还有一种send方式:
def get_list_02():
yield '1号'
yield '2号'
yield '3号'
mygen = get_list_02()
print(mygen.send(None)) # 输出 1号
print(next(mygen)) # 输出 2号
上面几个方式都说手动的调用一个一个进行迭代,而for循环会自动调用生成器generatr的__next__()方法或和next()一样。
所以也可以修改使用for循环的方式进行生成器的迭代:
def get_list_02():
yield '1号'
yield '2号'
yield '3号'
for i in get_list_02():
print(i)
2.3 怎么判断一个函数是不是生成式的函数?
看函数内部是否有yield 使用代码方式实现判断
判断一个函数是不是函数式生成器的方法代码示例如:
def get_list_02():
for i in (range(100000)):
temp = ['小钟'] * 2000
yield temp
from inspect import isgeneratorfunction
print('判断函数是不是一个函数式生成器,注意不需要加():',isgeneratorfunction(get_list_02))
2.4 怎么判断对象是不是生成器generator对象?
from inspect import isgenerator
print(isgenerator(((x for x in range(10)))))
2.5 如何使用生成器解决大文件的读取问题?
上一小节的也有说过,但是讲的处理大的循环问题,如果涉及本地的文件几个G的读取的时候,该如何优化读取呐?
思路就是:
每次我只读取多少 一次读取完成后,我就丢弃或处理,这样就不会占用内存。
如果要一次性读取进来的,就完蛋了!我之前就是这样干的!原因就是没遇到生成器这货!
# 读取大文件
def read_big_file_fun(fpath):
#读取的字节数
BLOCK_SIZE = 30
# 打开文件读取
with open(fpath, 'rb') as f:
print(f)
while True:
# 读取多个读取BLOCK_SIZE字节的数据
block = f.read(BLOCK_SIZE)
if block:
# 每次都只是返回BLOCK_SIZE字节的数据
yield block
else:
# 读取完成后,则直接的退出
return
myfilegen =read_big_file_fun('ceshi2.py')
print(myfilegen)
# 每一次的迭代的时候返回部分的字节数据,分段读取和处理:
print(str(next(myfilegen),'utf-8'))
print(str(next(myfilegen),'utf-8'))
2.6 查看生成器的执行状态:
def curr_generator():
for i in range(5):
if i == 2:
return '中断迭代'
yield i
from inspect import getgeneratorstate
wrap_g = curr_generator()
print(getgeneratorstate(wrap_g))
for i in wrap_g:
print(i)
print(getgeneratorstate(wrap_g))
输出结果为:
GEN_CREATED
0
GEN_SUSPENDED
1
GEN_SUSPENDED
执行状态说明:
GEN_CREATED 表示 等待开始执行
GEN_RUNNING 表示 解释器正在执行(仅在多线程应用中才看得到这状态)
GEN_SUSPENDED 表示 在yield表达式处暂停
GEN_CLOSED 表示 执行结束
2.7 如何使用单线程之下实现类型协程异步效果?
关于协程这里,暂时不展开,后面我的会再并发编程的系列,铺开。
首先我们的需要了解几个协程的特性:
只在一个单线程里实现并发 修改共享数据不需加锁 用户程序里自己保存多个控制流的上下文栈 一个协程遇到IO操作自动切换到其它协程
从上面几个特性感觉其实和我们的yield类似,而事实上,在Python3中没有新增asyncio库之前,我们的协程也是基于yield而来的,在以前的tornado框架中尤为明显。
使用yield模拟一个单线程下的遇到IO切换的示例:
import time
def fun_1():
while 1:
n = yield 'FUN_1 执行完毕,切换到FUN_2'
# 函数运行到yield会暂停函数执行,存储这个值。并且有next():调用这个值,与send():外部传入一个值
if not n:
return
time.sleep(0.5)
print('FUN_1 函数开始执行')
def fun_2(t):
next(t)
while 1:
print('-' * 20)
print('FUN_2 函数开始执行')
time.sleep(0.5)
ret = t.send('over')
print(ret)
if __name__ == '__main__':
n = fun_1()
fun_2(n)
输出的结果为:
--------------------
FUN_2 函数开始执行
FUN_1 函数开始执行
FUN_1 执行完毕,切换到FUN_2
--------------------
FUN_2 函数开始执行
FUN_1 函数开始执行
FUN_1 执行完毕,切换到FUN_2
--------------------
FUN_2 函数开始执行
FUN_1 函数开始执行
FUN_1 执行完毕,切换到FUN_2
--------------------
FUN_2 函数开始执行
FUN_1 函数开始执行
FUN_1 执行完毕,切换到FUN_2
--------------------
FUN_2 函数开始执行
FUN_1 函数开始执行
FUN_1 执行完毕,切换到FUN_2
从结果看,在单进程单线程之下我们实现两个函数的相互的切换执行!
2.8 使用yield来定义我们的一个生产者和消费者的模型:
首先思路:
1.生产者,负责不断的生产产品,生产好产品后就分发给消费者 2.消费者接收到产品,这进行产品消费
import time
def consumer(name):
r = None
while True:
packecode = yield r # 执行的中断点
if not packecode:
print("返回")
return
print("[%s] 产品消费进行中 %s" % (name, packecode))
def producer(make_time=3, listsconsumer=[]):
# 给所有的生产者分配一个生成器对象
for con in listsconsumer:
con.__next__()
import uuid
curr_make_time = 0
while curr_make_time < make_time:
curr_make_time += 1
packecode = str(uuid.uuid4())
print("\033[32;1m[生产者]\033[0m 开始生产产品,产品编号为: %s" % packecode)
# 给所有的生产者分配一个生成器对象
for con in listsconsumer:
con.send(packecode)
time.sleep(1)
print("\033[32;1m[生产者]\033[0m 开始停止营业!")
if __name__ == '__main__':
p = producer(listsconsumer=[consumer("c1"), consumer("c2")])
输出的结果为:
[生产者] 开始生产产品,产品编号为:1b3d8eb5-3cbf-429e-b759-91c8cbbfdcd3
[c1] 产品消费进行中 1b3d8eb5-3cbf-429e-b759-91c8cbbfdcd3
[c2] 产品消费进行中 1b3d8eb5-3cbf-429e-b759-91c8cbbfdcd3
[生产者] 开始生产产品,产品编号为:e06afa24-2b54-4c0b-8b21-2d0b2f50be0a
[c1] 产品消费进行中 e06afa24-2b54-4c0b-8b21-2d0b2f50be0a
[c2] 产品消费进行中 e06afa24-2b54-4c0b-8b21-2d0b2f50be0a
[生产者] 开始生产产品,产品编号为:d7b37b10-8e90-4a85-a793-aed22ee73cd9
[c1] 产品消费进行中 d7b37b10-8e90-4a85-a793-aed22ee73cd9
[c2] 产品消费进行中 d7b37b10-8e90-4a85-a793-aed22ee73cd9
[生产者] 开始停止营业!
2.9 补充使用 con.send(Ogj) 给 生成器 发送值信息说明
在上面的生产者和消费者示例中,用到了一个con.send(Ogj)进行迭代的一个调用。那这个con.send()里面的参数是啥东西呐?
使用最简单的示例再来演示:
def get_list_02():
temp = None
print('第1次迭代开始', temp)
temp = yield '1号'
print('第2次迭代开始', temp)
temp = yield '2号'
print('第3次迭代开始', temp)
temp = yield '3号'
print('迭代结束', temp)
mygen = get_list_02()
print(next(mygen))
print(mygen.send("我要点5号"))
print(next(mygen))
输出结果分析:
第1次迭代开始 None
1号
第2次迭代开始 我要点5号
2号
第3次迭代开始 None
3号
第一次迭代:输出了 1号 此时temp = Node 第二次迭代:输出了 我要点5号 此时temp = 我们的传入的值 第三次次迭代:输出了 3号 此时temp = Node
总结:
yield 是一个表达式 ,可以进行给某个变量赋值
使用send()方法传进去的值,实际上就是yield表达式结果返回的值
3 了解 yield from的使用
以下的总结大部分资料参考自:
https://blog.csdn.net/qq_27825451/article/details/85244237
自己基于上面的说法进行实践再结合自己的理解说明
3.1 别人的定义:
yield 惰性计算每次返回一个对象值 而,yield from就是“从什么(生成器)里面返回”:yield from generator
PS:yield from 是在Python3.3才出现的语法
以上是别人的一种说法,但是感觉说法又不对:
如果:yield from generator 那:
def gene():
yield from '小钟'
if __name__ == "__main__":
for i in gene():
print(i)
但是我们的'小钟',它不是一个生成器啊!
from inspect import isgeneratorfunction,isgenerator
print(isgenerator('小钟')) #False
按理应该是:yield from iterable(可迭代的对象: 生成器 、元组、 列表,字符串等·)
示例如:
def gene():
yield from '小钟'
def gene2():
for item in '小钟':
yield item
if __name__ == "__main__":
for i in gene():
print(i)
# 等价
for i in gene2():
print(i)
输出结果为:
小
钟
小
钟
如果是返回的是一个生成器呐?
def gene():
yield from '小钟'
def gene2():
for item in '小钟':
yield item
def gene3():
yield from (x for x in '小钟')
if __name__ == "__main__":
for i in gene():
print(i)
# 等价
for i in gene2():
print(i)
# 等价
for i in gene3():
print(i)
输出结果为:
小
钟
小
钟
小
钟
所以总结的话其实:
yield from generator yield from iterable for item in iterable: yield item
三者的关系是等价的。
3.2 yield 存在的弊端:
yield 在使用的过程也不是万能,也有瑕疵。如 for i in XX 和 next()方式的区别:
for 方式循环:
def curr_generator():
for index in range(10):
if index == 5:
return '中断迭代'
yield index
for i in curr_generator():
print(i)
输出结果为:
0
1
2
3
4
bext()方式:
def curr_generator():
for index in range(10):
if index == 5:
return '中断迭代'
yield index
mygen = curr_generator()
print(next(mygen))
print(next(mygen))
print(next(mygen))
print(next(mygen))
print(next(mygen))
print(next(mygen))
print(next(mygen))
print(next(mygen))
输出的结果为:
Traceback (most recent call last):
0
1
2
3
4
File "D:/code/python/local_python/AntFlask/dssf.py", line 39, in <module>
print(next(mygen))
StopIteration: 中断迭代
for 形式 中断迭代的时候不会主动的触发StopIteration,它的触发是隐式触发,而且无法获取到生成器的return的值。
next 形式终端迭代的时候会显示的触发StopIteration,但是也无法获取return的值
如果此时我们的有必要的知道获取某的return的值的话,怎么处理呐?且上面两个方法都可以获取到。那么这种情况下可以使用yield from来解决:
解决for循环的:
def curr_generator():
for i in range(5):
if i == 2:
return '中断迭代'
yield i
# 定义一个包装“生成器”的生成器,它的本质还是生成器
def wrap_my_generator(generator):
# 自动触发StopIteration,且将return的返回值赋值给yield from表达式的结果,即result
result = yield from generator
print(result)
return result
wrap_g = wrap_my_generator(curr_generator())
for i in wrap_g:
print(i)
输出为:
0
1
中断迭代
解决next的:
def curr_generator():
for i in range(5):
if i == 2:
return '中断迭代'
yield i
def wrap_my_generator(generator): # 定义一个包装“生成器”的生成器,它的本质还是生成器
result = yield from generator # 自动触发StopIteration异常,并且将return的返回值赋值给yield from表达式的结果,即result
print(result)
return result
wrap_g = wrap_my_generator(curr_generator())
try:
print(next(wrap_g))
print(next(wrap_g))
print(next(wrap_g))
print(next(wrap_g))
except StopIteration as exc:
print(exc.value) # 获取返回的值
输出为:
0
1
中断迭代
中断迭代
比较单纯使用 yield 和 使用 yield form:
yield 仅仅是对使用了yield的函数返回的迭代器对象,进行迭代。 yield form 对返回来的迭代器对象,又包装了新的一层生成器函数。 yield from 函数内部会捕获 StopIteration 异常,且会把return返回的值或者是StopIteration的value 属性的值变成 yield from 表达式的值,即上面的result。
4 yield from 之数据传输管道
4.1 来自流畅python的示例:
from collections import namedtuple
Result = namedtuple('Result', 'count average')
# the subgenerator
def averager(): # <1>
total = 0.0
count = 0
average = None
while True:
term = yield # <2>
if term is None: # <3>
break
total += term
count += 1
average = total/count
return Result(count, average) # <4>
# the delegating generator
def grouper(results, key): # <5>
while True: # <6>
results[key] = yield from averager() # <7>
# the client code, a.k.a. the caller
def main(data): # <8>
results = {}
for key, values in data.items():
group = grouper(results, key) # <9>
next(group) # <10>
for value in values:
group.send(value) # <11>
group.send(None) # important! <12>
# print(results) # uncomment to debug
report(results)
# output report
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(
result.count, group, result.average, unit))
data = {
'girls;kg':
[40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m':
[1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg':
[39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m':
[1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
查看文档介绍:
在PEP 380文档中:https://docs.python.org/3/whatsnew/3.3.html#pep-380关于yield from使用的专门术语说明:
委派生成器:包含 yield from
表达式的生成器函数;即上面的grouper生成器函数 子生成器:从 yield from 表达式
后面加的生成器函数;即上面的averager生成器函数 调用方:调用委派生成器的客户端代码;即上面的main函数
双向通道: 调用方main可以通过send()直接发送消息给子生成器averager,而averager子生成器yield的值,也是直接返回给main调用方。
上面的示例的调用路线为:
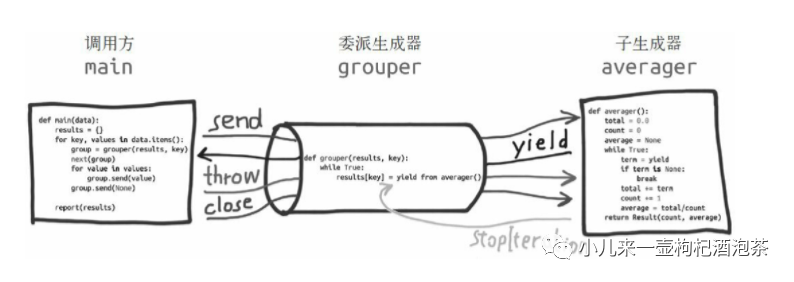
“调用方——>生成器包装函数——>生成器函数(协程函数)”;
总结的话:
(1)yield from主要设计用来向子生成器委派操作任务,但yield from可以向任意的可迭代对象委派操作;
(2)委派生成器(group)相当于管道,在调用方与子生成器之间建立一个双向通道,所以可以把任意数量的委派生成器连接在一起---一个委派生成器使用yield from 调用一个averager子生成器,而averager子生成器本身也是委派生成器,使用yield from调用另一个生成器。
参考资料来源原文链接:https://blog.csdn.net/qq_27825451/article/details/85244237
4.2 yield from表达式 思路解决线上大文件日志查询的实践案例:
PS:代码转载自:知乎 :https://zhuanlan.zhihu.com/p/51327900
PS:代码转载自:知乎 :https://zhuanlan.zhihu.com/p/51327900
PS:代码转载自:知乎 :https://zhuanlan.zhihu.com/p/51327900
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __author__ = 'liao gao xiang'
import os
import fnmatch
import gzip
import bz2
import re
# 问题,你想以数据管道 (类似 Unix 管道) 的方式迭代处理数据。比如,你有个大量的数据
# 需要处理,但是不能将它们一次性放入内存中。可以使用生成器实现数据处理管道
""" 文件格式如下
foo/
access-log-012007.gz
access-log-022007.gz
access-log-032007.gz
...
access-log-012008
bar/
access-log-092007.bz2
...
access-log-022008
"""
def gen_find(filepat, top):
"""
查找符合Shell正则匹配的目录树下的所有文件名
:param filepat: shell正则
:param top: 目录路径
:return: 文件绝对路径生成器
"""
for path, _, filenames in os.walk(top):
for file in fnmatch.filter(filenames, filepat):
yield os.path.join(path, file)
def gen_opener(filenames):
"""
每打开一个文件生成就生成一个文件对象,调用下一个迭代前关闭文件
:param filenames: 多个文件绝对路径组成的可迭代对象
:return: 文件对象生成器
"""
for filename in filenames:
if filename.endswith('.gz'):
f = gzip.open(filename, 'r', encoding='utf-8')
elif filename.endswith('.bz2'):
f = bz2.open(filename, 'r', encoding='utf-8')
else:
f = open(filename, 'r', encoding='utf-8')
yield f
f.close()
def gen_concatenate(iterators):
"""
将输入序列拼接成一个很长的行序列。
:param iterators:
:return: 返回生成器所产生的所有值
"""
for it in iterators:
yield from it
def gen_grep(pattern, lines):
"""
使用正则匹配行
:param pattern: 正则匹配
:param lines: 多行
:return: 结果生成器
"""
pat = re.compile(pattern)
for n, line in enumerate(lines, start=1):
if pat.search(line):
yield n, line
if __name__ == "__main__":
filenames = gen_find('*.log', '/home/ncms/ncms/logs')
files = gen_opener(filenames)
lines = gen_concatenate(files)
user_action = gen_grep('(?i)liaogaoxiang_kd', lines)
for n, line in user_action:
print(line)
示例代码输出:
[views:post]:2018-11-07 18:13:09.841490 -users- liaogaoxiang_kd登录成功!
[views:get]:2018-11-07 18:16:04.681519 -users- liaogaoxiang_kd访问了用户信息列表
[views:post]:2018-11-07 18:16:23.866700 -users- liaogaoxiang_kd编辑了用户的信息
[views:get]:2018-11-07 18:16:23.878949 -users- liaogaoxiang_kd访问了用户信息列表
[views:get]:2018-11-07 18:16:25.641090 -users- liaogaoxiang_kd访问了用户信息列表
[views:post]:2018-11-07 18:16:42.671377 -users- liaogaoxiang_kd编辑了用户的信息
[views:get]:2018-11-07 18:16:42.719873 -users- liaogaoxiang_kd访问了用户信息列表
[views:post]:2018-11-08 11:17:42.627693 -users- liaogaoxiang_kd登录成功!
参考资料:
https://zhuanlan.zhihu.com/p/51327900
https://blog.csdn.net/qq_27825451/article/details/85244237
Pythonbin编程时光:
https://www.cnblogs.com/wongbingming/p/9060989.html https://www.cnblogs.com/wongbingming/p/9085268.html
