




前言
纯属个人实践中相关经验之谈,如有纰漏,还希望大佬们多多提点!
小钟同学 | 文 【原创】| QQ:308711822
内存泄漏一直是我们的编写程序代码中遇到的最蛋疼的事,而且有些时候有些泄漏是隐匿的。对于服务端的程序来说,如果存在内存泄漏的会,会引发我们的系统内存资源不足,从而引发一系列的故障。
所以内存泄漏的定位也是非常关键一步,之前我们的已经有介绍了关于python内置模块GC一些方法,不过在对于一些循环引用对象的关系中,似乎还是无法可以得到明确的对象之间相关关系链。
一、标准库trancemalloc 3.4+以上
tracemalloc是用来分析Python程序内存分配的工具,是一个集成到内置库的工具。如果单纯是希望了解内存占用大小的话,使用它是一个不错的选择。
如:获取记录所有跟踪内存块的当前大小和峰值大小
import tracemalloc
import objgraph
import gc
class A():
pass
def __del__(self):
print('Dangerous!')
def funcext():
a = A()
b = A()
a.chifan = b
b.chifan = A
del a
del b
print('垃圾回收哦', gc.collect())
if __name__ == '__main__':
tracemalloc.start(25) # 默认25个片段,这个本质还是多次采样
funcext() # 这是我自己定义的对象成员函数
# 记录所有跟踪内存块的当前大小和峰值大小
size, peak = tracemalloc.get_traced_memory()
# 一个输出到控制台中,一个输出到文件
print('memory blocks:{:>10.4f} KiB'.format(peak / 1024))
输出的结果是:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/ceshgf.py
Dangerous!
Dangerous!
垃圾回收哦 0
memory blocks: 0.4609 KiB
官方示例:
import tracemalloc # from 3.4
tracemalloc.start() # 开始跟踪内存分配
d = [dict(zip('xy', (5, 6))) for i in range(1002)]
t = [tuple(zip('xy', (5, 6))) for i in range(10003)]
snapshot = tracemalloc.take_snapshot() # 快照,当前内存分配
top_stats = snapshot.statistics('lineno') # 快照对象的统计
d = [dict(zip('xy', (5, 6))) for i in range(100223)]
t = [tuple(zip('xy', (5, 6))) for i in range(100033)]
snapshot = tracemalloc.take_snapshot() # 快照,当前内存分配
top_stats = snapshot.statistics('lineno') # 快照对象的统计
for stat in top_stats:
print(stat)
输出的结果为:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/trancemallocshi.py
d:/code/vscode/py/trancemallocshi.py:23: size=14.5 MiB, count=200450, average=76 B
d:/code/vscode/py/trancemallocshi.py:24: size=10.7 MiB, count=300100, average=37 B
d:/code/vscode/py/trancemallocshi.py:17: size=70.3 KiB, count=2000, average=36 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:460: size=468 B, count=1, average=468 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:432: size=432 B, count=3, average=144 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:425: size=408 B, count=3, average=136 B
d:/code/vscode/py/trancemallocshi.py:19: size=400 B, count=1, average=400 B
d:/code/vscode/py/trancemallocshi.py:20: size=376 B, count=1, average=376 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:462: size=352 B, count=1, average=352 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:428: size=348 B, count=1, average=348 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:349: size=84 B, count=3, average=28 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:461: size=56 B, count=2, average=28 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:429: size=36 B, count=2, average=18 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:487: size=32 B, count=1, average=32 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:430: size=28 B, count=2, average=14 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:277: size=16 B, count=1, average=16 B
(.venv) PS D:\code\vscode\py>
两个的快照的对比示例:
import random
import tracemalloc # from 3.4
tracemalloc.start() # 开始跟踪内存分配
class A():
def __init__(self):
super().__init__()
def randomlist(self, n):
lists = []
l = [random.random() for i in range(n)]
l.sort()
for v in l:
lists.append(v)
return lists
def randomlist2(self, n):
lists = []
l = [random.random() for i in range(n)]
l.sort()
for v in l:
lists.append(v)
return lists
A().randomlist(20)
snapshot1 = tracemalloc.take_snapshot() # 快照,当前内存分配
A().randomlist(20000)
snapshot2 = tracemalloc.take_snapshot() # 快照,当前内存分配
# 对比两个内存的快照
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
# top_stats = snapshot.statistics('lineno') # 快照对象的统计
for stat in top_stats[:10]:
print(stat)
输出的结果:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/neicuntongji.py
d:/code/vscode/py/neicuntongji.py:24: size=1600 B (+1360 B), count=100 (+85), average=16 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:349: size=468 B (+468 B), count=5 (+5), average=94 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:487: size=424 B (+424 B), count=3 (+3), average=141 B
d:/code/vscode/py/neicuntongji.py:41: size=400 B (+400 B), count=1 (+1), average=400 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:275: size=32 B (+32 B), count=1 (+1), average=32 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\tracemalloc.py:277: size=16 B (+16 B), count=1 (+1), average=16 B
d:/code/vscode/py/neicuntongji.py:18: size=908 B (+0 B), count=8 (+0), average=114 B
d:/code/vscode/py/neicuntongji.py:30: size=72 B (+0 B), count=1 (+0), average=72 B
d:/code/vscode/py/neicuntongji.py:22: size=72 B (+0 B), count=1 (+0), average=72 B
d:/code/vscode/py/neicuntongji.py:19: size=72 B (+0 B), count=1 (+0), average=72 B
(.venv) PS D:\code\vscode\py>
引入到我们的Flask框架中进行分析:
'''
Author: 小钟同学
objectDescription: 项目描述
Date: 2021-03-07 21:48:40
LastEditors: 308711822@qq.com
LastEditTime: 2021-03-09 17:06:57
FilePath: \py\flaskmain.py
Version: 1.0
'''
from flask import Flask, jsonify
import time
import tracemalloc
app = Flask(__name__)
@app.route('/')
def line_test():
for item in range(5):
print(item)
time.sleep(0.2)
snapshot2 = tracemalloc.take_snapshot()
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
for stat in top_stats[:10]:
print(stat)
return jsonify({'code': 200})
if __name__ == '__main__':
tracemalloc.start()
snapshot1 = tracemalloc.take_snapshot()
app.run()
请求访问我们的接口地址:http://127.0.0.1:5000/ 查看输出结果:
0
1
2
3
4
<frozen importlib._bootstrap_external>:508: size=29.4 KiB (+29.4 KiB), count=1082 (+1082), average=28 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\socket.py:240: size=16.7 KiB (+16.7 KiB), count=7 (+7), average=2439 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\stringprep.py:187: size=12.1 KiB (+12.1 KiB), count=2 (+2), average=6170 B
D:\code\vscode\py\.venv\lib\site-packages\click\_winconsole.py:282: size=9092 B (+9092 B), count=6 (+6), average=1515 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\stringprep.py:262: size=5784 B (+5784 B), count=99 (+99), average=58 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\encodings\idna.py:292: size=1896 B (+1896 B), count=11 (+11), average=172 B
D:\code\vscode\py\.venv\lib\site-packages\click\_compat.py:71: size=1694 B (+1694 B), count=9 (+9), average=188 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\stringprep.py:220: size=1616 B (+1616 B), count=28 (+28), average=58 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\stringprep.py:19: size=1432 B (+1432 B), count=19 (+19), average=75 B
C:\Users\mayn\AppData\Local\Programs\Python\Python35-32\lib\encodings\utf_16_le.py:18: size=1392 B (+1392 B), count=9 (+9), average=155 B
127.0.0.1 - - [09/Mar/2021 17:07:11] "GET / HTTP/1.1" 200 -
二 第三方库-objgraph
本节我自己尝试引入objgraph实践一下,objgraph它可以很好帮助我们的进行分析对象之前的引用关系,就是所谓对象关系图。借助于xdot 还可以进行可视化对象关系。
官网地址:
https://mg.pov.lt/objgraph/
1. objgraph安装
pip install objgrap
可视化依赖库xdot:
官网地址:https://github.com/jrfonseca/xdot.py
pip install xdot
windows上运行的时候提示缺少gi模块:但是安装这个gi模块也无法安装!
绘图依赖:
pip install graphviz
2、官网示例应用实践
2.1 引用对象图
c_profile_text_run.py
import objgraph
x = []
y = [x, [x], dict(x=x)]
# 分析我们的Y列表对象生产它的对象关系引用图
objgraph.show_refs([y], filename='sample-graph.png')
# Graph written to ....dot (... nodes)
# Image generated as sample-graph.png
然后右键运行或命令运行我们的上面的py文件:
(.venv) PS D:\code\vscode\py> python .\c_profile_text_run.py
Graph written to C:\Users\mayn\AppData\Local\Temp\objgraph-y03ago35.dot (4 nodes)
Image generated as sample-graph.png
(.venv) PS D:\code\vscode\py>
查看生成的图片文件sample-graph.png:
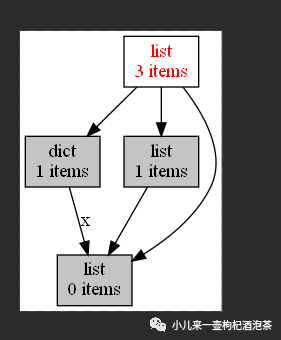
从图我们我可以看到Y 里面有三个对象,
一个是字典类型的对象 一个只列表类似的对象 指向X对象的对象
使用xdot进行可视化数据分析(不合适windows上运行)
xdot.py可以用作命令中的独立应用程序 行,或作为嵌入到python应用程序中的库。如果想使用xdot进行可视化数据分析,去除生成的图片文件参数名即可:
# 性能分析装饰器定义
import objgraph
x = []
y = [x, [x], dict(x=x)]
objgraph.show_refs([y])
然后执行我们的分析:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/c_profile_text_run.py
Graph written to C:\Users\mayn\AppData\Local\Temp\objgraph-97c1zm6s.dot (4 nodes)
Spawning graph viewer (xdot)
(.venv) PS D:\code\vscode\py>
生产了一个临时的文件C:\Users\mayn\AppData\Local\Temp\objgraph-97c1zm6s.dot
2.2 反向引用对象图
# 性能分析装饰器定义
import objgraph
# import pdb
# pdb.set_trace()
x = []
y = [x, [x], dict(x=x)]
objgraph.show_backrefs([x], filename='sample-backref-graph.png')
#objgraph.show_backrefs(objgraph.by_type('OBJ')[0], max_depth = 10, filename = 'obj.dot')
PS:max_depth一般建议设置一下,大小要适宜,太小,看不到完整的引用链,太大,运行耗时长。

2.3 常用几个方法:
快速了解内存中的对象,查看最常用的类型,limit限制查看最前面的多少个。
objgraph.show_most_common_types(limit=20)
查看增长最快的类型,通过进行快照对象对比来分析。
objgraph.show_growth(limit=10)
使用场景:间隔某些时间段调用这方法,查看哪些对象类型增加比较快。t它统计自上次调用以来增加得最多的对象,这个函数非常有利于发现潜在的内存泄露。函数内部调用了gc.collect(),因此即使有循环引用也不会对判断造成影响。
objgraph.show_growth使用示例1:
import objgraph
x = []
y = [x, [x], dict(x=x)]
objgraph.show_growth(limit=10)
print("===========")
y23 = [x, [x], dict(x=x)]
del x
objgraph.show_growth(limit=10)
print("===========")
输出结果:
function 2215 +2215
dict 1169 +1169
wrapper_descriptor 1020 +1020
tuple 950 +950
weakref 849 +849
method_descriptor 721 +721
builtin_function_or_method 656 +656
getset_descriptor 387 +387
set 384 +384
list 338 +338
===========
list 340 +2
dict 1170 +1
===========
(.venv) PS D:\code\vscode\py>
objgraph.show_growth使用示例2:
import os
import gc
import objgraph
# 开始强制进行垃圾回收
gc.collect()
print('第1次调用show_growth时,上打印出来的是当前所有对象的总数====================================')
# 第一次统计我们的对象使用情况
objgraph.show_growth()
# 新建一个列表的对象
xiaozhong = []
print('第2次调用show_growth====================================')
# 对所有活着的对象进行快照
objgraph.show_growth()
# 向列表里面添加数据对象
xiaozhong.append(["sdasda", "sfsdfdf", 3, {"还是的还是兑换"}])
print('第3次调用show_growth====================================')
# 对所有活着的对象进行快照
objgraph.show_growth()
# 新建一个列表
k = {"sdas": 3}
b = ['a', 'b', 'c']
# 对所有活着的对象进行快照
print('第4次调用show_growth====================================')
objgraph.show_growth()
del b
# 对所有活着的对象进行快照
del k
print('第5次调用show_growth====================================')
objgraph.show_growth()
输出结果为:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/xielou2.py
第1次调用show_growth时,上打印出来的是当前所有对象的总数====================================
function 2215 +2215
dict 1168 +1168
wrapper_descriptor 1020 +1020
tuple 950 +950
weakref 849 +849
method_descriptor 721 +721
builtin_function_or_method 656 +656
getset_descriptor 387 +387
set 384 +384
list 335 +335
第2次调用show_growth====================================
list 336 +1 (因为xiaozhong = [])
第3次调用show_growth====================================
list 337 +1 (因为xiaozhong.append(["sdasda", "sfsdfdf", 3, {"还是的还是兑换"}]))
set 385 +1 (因为{"还是的还是兑换"})
第4次调用show_growth====================================
list 338 +1 因为(b = ['a', 'b', 'c'])
第5次调用show_growth====================================
(.venv) PS D:\code\vscode\py>
查看某个类型对象
objgraph.by_type('list')
使用场景:间隔某些时间段调用这方法,查看哪些对象类型增加比较快。
查看垃圾回收器的个数
objgraph.count()
使用场景:间隔某些时间段调用这方法,查看垃圾回收的情况。
本质其实就是通过gc.get_objects()拿到所用的对象,然后统计指定类型的数目。
示例如:
import objgraph
class PAPA(object):
pass
class MAMA(object):
pass
# 创建两个对象
baba = PAPA()
mama = MAMA()
# 查看当前垃圾回收期的个数
print("PAPA的垃圾个数有", objgraph.count('PAPA'))
print("MAMA的垃圾个数有", objgraph.count('MAMA'))
print("=========================")
del baba
del mama
print("PAPA的垃圾个数有", objgraph.count('PAPA'))
print("MAMA的垃圾个数有", objgraph.count('MAMA'))
输出结果:
PAPA的垃圾个数有 1
MAMA的垃圾个数有 1
=========================
PAPA的垃圾个数有 0
MAMA的垃圾个数有 0
引入循环引用的示例:
import objgraph
class PAPA(object):
pass
class MAMA(object):
pass
# 创建两个对象
baba = PAPA()
mama = MAMA()
# 查看当前垃圾回收期的个数
print("PAPA的垃圾个数有", objgraph.count('PAPA'))
print("MAMA的垃圾个数有", objgraph.count('MAMA'))
# 引入循环引用的示例
baba.laopo = mama
mama.laogong = baba
print("=========================")
del baba
del mama
print("PAPA的垃圾个数有", objgraph.count('PAPA'))
print("MAMA的垃圾个数有", objgraph.count('MAMA'))
输出结果为:
PAPA的垃圾个数有 1
MAMA的垃圾个数有 1
=========================
PAPA的垃圾个数有 1
MAMA的垃圾个数有 1
1
生产一张有关objs的引用图,[反向引用对象图],
objgraph.show_backrefs
通过引用我们可以分析对象为什么不释放,后面会利用这个API来查内存泄露。
找到一条指向obj对象的最短路径,且路径的头部节点需要满足predicate函数 (返回值为True)
objgraph.find_backref_chain(obj, predicate, max_depth=20, extra_ignore=())
可以快捷、清晰指出 对象的被引用的情况
3. 官方内存泄漏案例
不会产生泄漏示例:
import random
import objgraph
class MyBigFatObject(object):
pass
def computate_something(_cache={}):
x = MyBigFatObject() # 不会产生内泄漏
sdfd333 = MyBigFatObject() # this one doesn't leak
# 在调用函数之前,我们对所有活着的对象进行快照
objgraph.show_growth(limit=3)
# 开始调用函数
computate_something()
# 再执行一次快照建立
objgraph.show_growth()
输出结果:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/c_profile_text_run.py
function 2216 +2216
dict 1169 +1169
wrapper_descriptor 1020 +1020
(.venv) PS D:\code\vscode\py>
产生内存泄漏示例:
import random
import objgraph
class MyBigFatObject(object):
pass
def computate_something(_cache={}):
# 很明细的产生的泄漏的地址
_cache[42] = dict(foo=MyBigFatObject(),
bar=MyBigFatObject())
x = MyBigFatObject() # 不会产生内泄漏
sdfd333 = MyBigFatObject() # 不会产生内泄漏
# 在调用函数之前,我们对所有活着的对象进行快照
objgraph.show_growth(limit=3)
# 开始调用函数
computate_something()
# 再执行一次快照建立
objgraph.show_growth()
输出结果:
(.venv) PS D:\code\vscode\py> & d:/code/vscode/py/.venv/Scripts/python.exe d:/code/vscode/py/c_profile_text_run.py
function 2216 +2216
dict 1169 +1169
wrapper_descriptor 1020 +1020
MyBigFatObject 2 +2
dict 1171 +2
(.venv) PS D:\code\vscode\py>
最明显的地方就是:
MyBigFatObject 2 +2
dict 1171 +2
追踪MyBigFatObject在垃圾回收器的情况:完整代码:
import random
import objgraph
class MyBigFatObject(object):
pass
def computate_something(_cache={}):
# 很明细的产生的泄漏的地址
_cache[42] = dict(foo=MyBigFatObject(),
bar=MyBigFatObject())
x = MyBigFatObject() # 不会产生内泄漏
sdfd333 = MyBigFatObject() # 不会产生内泄漏
# 在调用函数之前,我们对所有活着的对象进行快照
objgraph.show_growth(limit=3)
# 开始调用函数
computate_something()
# 再执行一次快照建立
objgraph.show_growth()
# 显示所有的根模块示例
objgraph.show_chain(
objgraph.find_backref_chain(
random.choice(objgraph.by_type('MyBigFatObject')),
objgraph.is_proper_module),
filename='chain.png')
运行脚本结果输出查看相关的图片chain.png:

从上图看到我们的
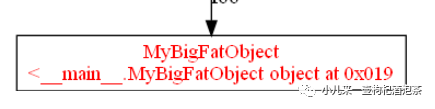
是产生内存泄漏的对象(不可达对象),
上图说明的是:
__main__模块下包含有了dict对象 里面包含you了computate_something computate_something里面创建了一个元组 computate_something里面创建了一个元组里有存在两个字典
非官方示例分析步骤
参考地址:https://blog.csdn.net/ybn6775/article/details/81676801 泄漏示例:
1. 分析第1步:定位泄漏对象
import objgraph
_cache = []
class A():
pass
def funcext():
a = A()
_cache.append(a)
if True:
return
_cache.remove(a)
if __name__ == '__main__':
# 第一步定位泄露的对象
objgraph.show_growth()
try:
funcext()
except:
pass
print("调用函数后")
objgraph.show_growth()
2. 分析对象引用链
import objgraph
_cache = []
class A():
pass
def funcext():
a = A()
_cache.append(a)
if True:
return
_cache.remove(a)
if __name__ == '__main__':
# 第1步定位泄露的对象
objgraph.show_growth()
try:
funcext()
except:
pass
print("")
objgraph.show_growth()
# 第2:定位了哪个对象发生了内存泄露,那么接下来就是分析怎么泄露的,引用链是怎么样的
objgraph.show_backrefs(objgraph.by_type(
'A')[0], max_depth=10, filename='obj.png')
# objgraph.show_refs([y], filename='sample-graph.png')
objgraph.show_backrefs(objgraph.by_type(
'A')[0], max_depth=10, filename='obj.png')
查看我们的图:

可以看到泄露的对象(红框表示),是被一个叫_cache的list所引用,而_cache又是被__main__这个module所引用。
使用show_chain找到最短路径:
import objgraph
_cache = []
class A():
pass
def funcext():
a = A()
_cache.append(a)
if True:
return
_cache.remove(a)
if __name__ == '__main__':
# 第一步定位泄露的对象
objgraph.show_growth()
try:
funcext()
except:
pass
print("")
objgraph.show_growth()
# 第二部:定位了哪个对象发生了内存泄露,那么接下来就是分析怎么泄露的,引用链是怎么样的
objgraph.show_backrefs(objgraph.by_type(
'A')[0], max_depth=10, filename='obj.png')
# objgraph.show_refs([y], filename='sample-graph.png')
# 第三部最短的路径
import random
objgraph.show_chain(
objgraph.find_backref_chain(
random.choice(objgraph.by_type('A')),
objgraph.is_proper_module),
filename='short_obj.png')
查看最短路径图short_obj.png:

三、 第三方库 -pympler
pympler工具特别适合给当前所有的 objects 的内存占用情况做简单统计 tracker对象初始化的时候会创建一个summary,每次调用tracker.print_diff。
安装
pip install pympler
()的时候又会创建一个summary,当前的summary与上次的summary做比较,并打印两者之间的不同。如:
from pympler import tracker
tr = tracker.SummaryTracker()
# 建立快照一样对比不同
tr.print_diff()
x = []
y = [x, [x], dict(x=x)]
# 建立快照一样对比不同
tr.print_diff()
y23 = [x, [x], dict(x=x)]
del x
# 建立快照一样对比不同
tr.print_diff()
输出的结果:
types | # objects | total size
======================= | =========== | ============
list | 4509 | 229.99 KB
str | 4460 | 206.81 KB
int | 331 | 4.56 KB
dict | 2 | 200 B
function (store_info) | 1 | 72 B
cell | 2 | 56 B
weakref | 1 | 44 B
method | -1 | -36 B
code | -2 | -160 B
tuple | -18 | -992 B
types | # objects | total size
======= | =========== | ============
dict | 1 | 388 B
list | 4 | 172 B
type | 0 | 144 B
str | 1 | 46 B
types | # objects | total size
======= | =========== | ============
dict | 1 | 148 B
list | 2 |
说明
部分的图或资料来互联网收集整理,如有侵权,烦请联系,我会立即进行删除。
End
纯属个人实践中相关经验之谈,如有纰漏,还希望大佬们多多提点!小钟同学 | 文 【原创】| QQ:308711822
如果文章对您有所帮助,不如四连击一下:点在看+分享+收藏+关注呗 !哈哈
如有错误之处也希望能帮忙指出。非常感谢!

