




点击上方 云原生CTO,选择 设为星标
优质文章,每日送达


「【只做懂你de云原生干货知识共享】」
深入探讨:为 Java 开发人员构建 Kubernetes Operator SDK
最近 Container Solutions 发布了java-operator-sdk 1.0.0 版本,它允许开发人员以简单方便的方式实现 Kubernetes 操作符。在这篇文章中,我想深入了解我们的团队必须应对的挑战以及我们为解决这些挑战而采取的方法。希望我能阐明构建操作符和使用 Kubernetes API 的一些有趣方面。

简而言之,operator
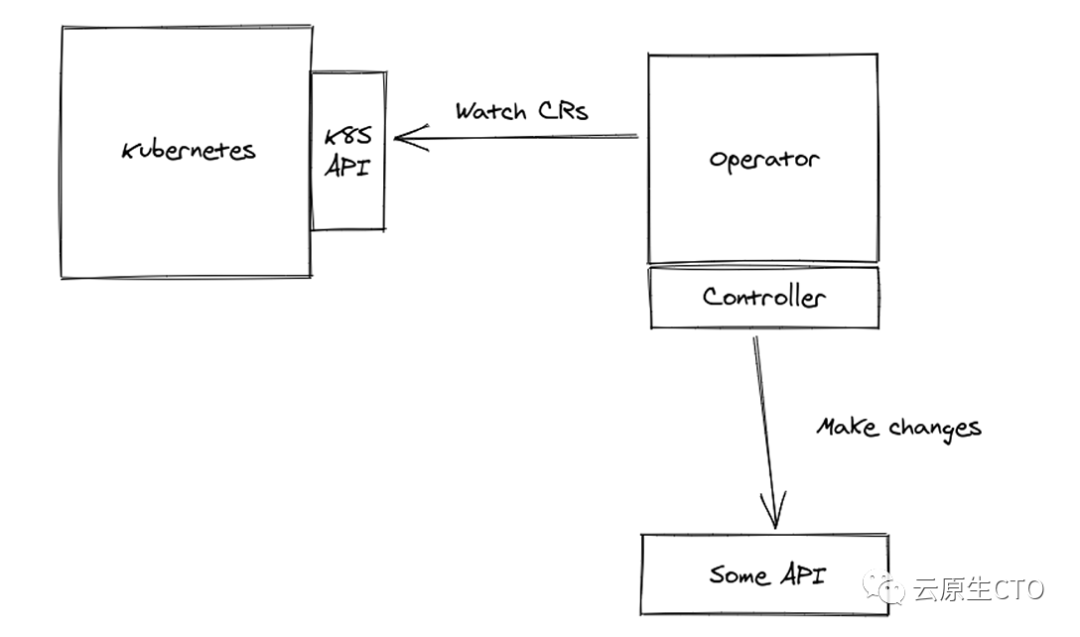
Kubernetes 提供了一种扩展机制,允许我们定义自己的资源类型,称为自定义资源。在集群上运行一个 pod 来监控某种类型的自定义资源并基于它管理其他资源,这就是 Operator模式。
正如官方 Kubernetes 文档所说,“Operators 是 Kubernetes API 的客户端,充当自定义资源的控制器”。
这是一个示例自定义资源:
apiVersion: "sample.javaoperatorsdk/v1"
kind: WebPage
metadata:
name: hello-world-page
spec:
html: |
<html>
<head>
<title>Hello Operator World</title>
</head>
<body>
Hellooooo Operators!!
</body>
</html>
换句话说,operator只是连接到 Kubernetes API,以监视与自定义资源相关的事件。基于这些事件,我们执行控制器。控制器提供确保我们与目标域协调的实现。请注意,通过观察事件,我们会收到整个资源作为事件负载。因此,我们收到了一个声明性描述,它定义了我们的目标域对象应该是什么样子。在控制器中,我们获取整个自定义资源,更准确地说是其中的.spec 一部分,我们将声明性描述转换为命令式操作,通常是目标系统的 API 调用(可以是 Kubernetes API 或任何其他)。
构建 SDK
我们决定创建 java-operator-sdk 来解决每个用 Java 编写的operator都需要解决的某些常见问题。当我们开始研究第一个 operator 时,它实际上只是围绕fabric8 Kubernetes API 客户端的一个包装器。
我们稍后解决的两个主要主题是:如何有效地处理事件以及如何管理一致性。这些类别中的问题(并非不相关)并非无关紧要,而是可以通过框架解决。这意味着开发人员不必再担心这些问题,创建一个operator就意味着只需要实现一个简单的接口。
活动安排
当我们在 Kubernetes 中观察事件时,我们会在单个线程上连续接收它们。更准确地说,自定义资源类型的所有事件——或 Kubernetes 术语中的“观察”。我们需要一种高效的多线程方式来处理这些事件。最后,我们为事件调度算法定义了这三个基本要求:
1.并发处理不同资源的事件。
控制器执行可能需要很长时间。例如,由于来自远程 API 的响应缓慢,我们的控制器实际上需要几分钟,而不同资源(相同类型)的传入事件是不相关的。这就是为什么我们不想以串行方式一个一个地处理它们。当我们接收到一个新事件时,我们使用具有给定线程池的执行程序服务来调度它,并使处理并发。
2. 单个自定义资源的串行事件处理。
另一方面,我们不想同时为同一资源执行事件。想象一下这种情况:当我们更改自定义资源时,我们开始执行事件的控制器,但突然有人再次更改资源。这将导致新事件和新控制器执行。尽管这不会导致线程之间共享内存方面的经典竞争条件,但会有两个线程以任意顺序调用各种 API。在极端情况下,甚至可能发生后一个事件的处理速度比第一个更快,从而导致状态不一致的情况。
我们在这里想要的是相同资源的事件连续执行——一个接一个。因此,只有在前一个事件处理完成后,我们才应该开始新的事件处理。请注意,如果我们开始处理事件,我们可以为同一资源接收任意数量的新事件(同时,可以对自定义资源应用任意数量的更改)。然而,由于事件的有效载荷是整个资源,我们可以丢弃所有它们,除了最后一个,这将是最新的。
3. 重试失败的控制器执行
在这种情况下,我们可能想重试。更具体地说,当协调逻辑失败时,框架可以重试对控制器的调用。在网络错误的情况下,它通常可以至少重试一次调用。为了实现这一点,我们维护了一个内存状态——已经为特定事件执行的重试次数。重试限制、回退周期或时间限制都是可配置的。这使调度有点复杂,因为我们有许多额外的场景。
例如:假设我们在控制器中有异常时收到新事件。在这种情况下,我们不想重试;只需丢弃失败的事件,并处理新的事件。
幸运的是,不同的场景可以在代码中很好地处理,我们很高兴最后调度算法变得足够简单。
“生成”元数据属性
Kubernetes 对象具有称为“生成”的元数据属性。这是一个在每次更改时递增的数字,不包括对资源.metadata和.status子资源的更改。如果我们收到一个新事件,但生成没有增加,我们可以忽略该事件并且不应该执行控制器。请记住,在控制器实现中,我们主要关注的应该是.spec零件。
为了实现知道生成的调度,我们可以使用我们在事件中处理和/或接收的最高代来维护一个简单的内存状态。如果新事件的产生不高,我们可以丢弃它。
这是一个很好的优化,但仍然可能发生控制器实现依赖于元数据或状态字段的情况。请注意,这是一个框架,因此通过应用YAGNI原则,我们可能会错过一些实际用例。因此,我们遵循了“某些人可能需要它”的原则,在控制器级别引入了一个标志,该标志可以关闭基于生成的事件过滤。因此,控制器将接收所有更改的所有事件。
一致性
我们正在处理一个事件驱动的分布式系统。Kubernetes API 提供的特性和保证已经对我们的事件处理有很大帮助,我们上面讨论的事件调度解决了很多问题。我们仍然需要处理一些额外的问题来管理一致性:
“至少一次”和幂等性
控制器实现应该是幂等的( f(x)=f(f(x)))。原因是我们不能保证事件的处理一次——即使重试被关闭。换句话说,我们在这里处理“至少一次”保证。
在许多情况下,我们会多次处理一个事件——通常,当operator在控制器执行期间崩溃时,可能会发生这种情况。因此,控制器正在处理事件;在处理结束之前,进程/pod 被杀死。重新启动后,它只会再次处理最后一个事件。通过使控制器实现幂等,问题以优雅的方式解决。
删除资源和终结器
Kubernetes终结器帮助我们确保不会丢失删除事件。想象一下在自定义资源被删除时操作员崩溃或未运行的情况。当我们开始观察事件时,我们不会得到之前删除的资源的删除事件。所以operator启动后,我们不会收到delete事件。我们最终会处于不一致的状态。
为了避免这个问题,当我们第一次收到自定义资源的事件时,我们会自动添加终结器。这将确保在我们移除终结器之前不会删除资源——因此,在我们执行删除处理方法之前。我们在所有情况下都添加终结器,即使控制器没有指示我们更新资源。换句话说,在控制器执行之后,我们检查自定义资源是否具有目标终结器;如果没有,我们添加它并更新资源。这似乎是一种固执己见的方法,但是,如果没有终结器,就无法保证与删除相关的一致性。
有一个极端情况,即使这还不够:我们收到一个“创建事件”,执行控制器,但由于某种原因我们无法添加终结器(这是第一次运行),或者operator崩溃在我们添加终结器之前。这时有人删除了资源。在这个场景结束时,所有资源都将由控制器创建,但由于没有终结器,自定义资源不再存在。幸运的是,这在实践中很少发生。
丢失更新问题和乐观锁
可以随时使用 Kubernetes API 更新自定义资源。除此之外,在事件处理结束时,我们可能希望将一些更改写回自定义资源——这意味着操作员也将进行更新。
因此,想象一个场景,当我们处理一个事件时,我们想要对自定义资源应用更新(比如添加一些由控制器定义的注释)。但是,就在此之前,API 用户也会更改自定义资源。因为通过进行更新我们替换了整个资源,这可能会导致 API 用户所做的更新丢失。这是“丢失更新问题”的经典场景。
解决方案是使用乐观锁定,这意味着我们只在处理结束时对资源进行条件更新,从而检查以确保在我们开始处理资源后资源没有更改。如果是,我们不更新资源;更准确地说,我们将收到来自 Kubernetes API 的“冲突”错误。这不是问题,因为无论如何我们都会从控制器执行时发生的更新接收和处理事件。
出于这个原因,如果我们对来自控制器的资源应用更改,自然会发生冲突。这可能有点奇怪,但这是处理这些场景的有效方法。
运行单个实例
我们应该始终运行operator的单个实例(想想 pod)。如果同一operator的多个实例正在运行(并侦听来自同一组资源的事件),我们会遇到类似的问题,就像我们在事件调度部分的第2 点中已经讨论过的那样。两个进程将接收相同的事件,因此将有两个独立的进程根据相同的自定义资源规范以任意顺序进行更改。
请注意,有一些方法可以解决此问题,例如悲观锁定。对于 Kubernetes 的当前设置,这些都不是微不足道的。所以这里的实用解决方案是只运行一个实例。
停机时间怎么样?
如果operator的pod崩溃了怎么办?Kubernetes 将重新启动它,当我们注册 watch 时,我们会再次收到所有资源的最新事件。通过这种方式,我们还可以处理在operator未运行时完成的更改事件。
请注意,这不是最佳的。当operator停机时,我们可能只想处理我们错过的事件。不幸的是,如果没有持久化状态,这是不可能的——为每个资源保存最后处理的 resourceVersion。这可能很好,但这不是一个微不足道的优化,现在我们决定不实施它。
结论
希望您现在对框架必须处理的核心问题有所了解。
参考:
https://blog.container-solutions.com/a-deep-dive-into-the-java-operator-sdk

更多好文推荐阅读
Kubernetes 模式:InitContainers模式
嘿,你在看吗?
