




点击上方 云原生CTO,选择设为星标
优质文章,每日送达

----------------------------------------------
「【只做懂你de云原生干货知识共享】」

(逆向理解)-没有kube-proxy组件的Kubernetes集群会怎么样?
Kubernetes是一个复杂的平台,其中各个运动部件协同工作。Kubernetes网络是最关键的(如果不是最关键的话)之一。kubernetes网络有很多层,即Pod网络,服务IP,外部IP集群IP等。在此过程中,kube-proxy发挥着重要作用。在这里,我们尝试通过一些不同的CNI选项将Kubernetes与kube-proxy一起使用,我们将看到它是否具有任何好处,或者kube-proxy是否具有任何特定的限制。
快速理解kube-proxy
在各种kubernetes网络组件中,让我们看两个特别的组件-pod网络和service网络。每当我们设置Kubernetes时,我们总是会指定不重叠的Pod CIDR和Service CIDR。创建Pod时,它具有自己的IP,例如,下面的演示,我将现在的集群当前节点的master的pod ip列出来,因为你要知道路由表是当前节点,所以我将master节点的pod ip列出来
[root@master ~]# kubectl get po -A -owide |grep master |egrep -v "192"
kube-system calico-kube-controllers-6b94766748-nx4b6 1/1 Running 1 12d 10.244.219.83 master <none> <none>
kube-system coredns-9d85f5447-w9mg4 1/1 Running 1 12d 10.244.219.84 master <none> <none>
kube-system coredns-9d85f5447-xll29 1/1 Running 1 12d 10.244.219.81 master <none> <none>
容器IP是来自容器CIDR的虚拟网络的一部分,它充当每个节点上的网桥。我们可以通过登录主节点之一并打印路由表来查看 可以使用route -n
[root@master ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 100 0 0 ens160
10.244.104.0 192.168.2.13 255.255.255.192 UG 0 0 0 tunl0
10.244.167.128 192.168.2.11 255.255.255.192 UG 0 0 0 tunl0
10.244.219.64 0.0.0.0 255.255.255.192 U 0 0 0 *
10.244.219.81 0.0.0.0 255.255.255.255 UH 0 0 0 caliaf3f4a2a80f
10.244.219.83 0.0.0.0 255.255.255.255 UH 0 0 0 cali9bef2516196
10.244.219.84 0.0.0.0 255.255.255.255 UH 0 0 0 cali9d477edda73
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.0.0 0.0.0.0 255.255.252.0 U 100 0 0 ens160
我们可以在上面看到子网10.244.219.64中的所有Ip都路由到工作程序节点0.0.0.0。如果我们登录到该工作节点列表,则将看到该特定节点上的网络接口,我们将看到预期的虚拟接口来自tunl0,另外每个pod都对应网络接口名称cali
4: caliaf3f4a2a80f@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
6: cali9bef2516196@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
7: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.244.219.64/32 brd 10.244.219.64 scope global tunl0
valid_lft forever preferred_lft forever
8: cali9d477edda73@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
由于篇幅过长这篇文章不会深入calico网络的内容,如果你对网络更有兴趣,关注公众号,并设为星标,后面将能看到更多云原生干货知识。
回到正题。现在,让我们深入理解一下iptbales在kube-proxy流量是如何转发的,以及出现了哪些瓶颈,后续我们将大胆做个性能测试来验证没有kube-proxy是否会提升性能,为了更清晰熟悉iptables的在kube-proxy当中的使用的原理,我单独在master节点创建一个pod以及svc转通过nodeport转发出去,看一下实际流量的走向
[root@master ~]# kubectl create deploy nginx --image=nginx -o yaml --dry-run > nginx-test.yaml
[root@master ~]# kubectl create service nodeport nginx --tcp=5678:80 --dry-run -o yaml > nginx-svc.yaml
运行之后我们会发现service关联上了对应的pod ip,当然如果你注意的话,我们会在宿主机多出一个新的cali的网络接口,当然你要知道这个pod并不是在master节点的,而serive它就充当了这么一个负载均衡器
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d
nginx NodePort 10.96.62.137 <none> 5678:30965/TCP 4s
[root@master ~]# kubectl get ep
NAME ENDPOINTS AGE
fuseim.pri-ifs <none> 10d
kubernetes 192.168.2.10:6443 12d
nginx 10.244.167.174:80 9s
当kube-proxy在iptables的模式下使用(因为它是在kubernetes dafault默认的,除非你使用ipvs规则),将请求路由到服务继续为现有的服务工作,即使kube-proxy pod部署, Kube-proxy也会监听所有的K8S节点
在正常情况下,kube-proxy 绑定并侦听所有NodePorts端口,因此,如果你具有服务NodePort,则不必手动配置iptables规则。
如果你熟悉iptables,那么我们可以看到KUBE-SERVICES目标中有一个由创建的链kube-proxy。现在列出该链中的规则,请参见下面的示例:
[root@master ~]# iptables -t nat -L KUBE-SERVICES -n | column -t
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.96.62.137 /* default/nginx:5678-80 cluster IP */ tcp dpt:5678
KUBE-SVC-VXA2I2E2TLP6KZO2 tcp -- 0.0.0.0/0 10.96.62.137 /* default/nginx:5678-80 cluster IP */ tcp dpt:5678
KUBE-MARK-MASQ udp -- !10.244.0.0/16 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
KUBE-SVC-TCOU7JCQXEZGVUNU udp -- 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:53
KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:53
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.96.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-SVC-JD5MR3NA4I4DYORP tcp -- 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- 0.0.0.0/0 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
KUBE-NODEPORTS all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
如您所见,KUBE-SERVICES链中的一个目标是KUBE-NODEPORTS链。这会列出所有cluster ip的流量地址并关联对应的svc,刚才我们部署的nginx,正在iptables当中处理了流量
由于我们创建的服务的类型为NodePort,因此让我们在KUBE-NODEPORTS链中列出规则。
[root@master ~]# iptables -t nat -L KUBE-NODEPORTS -n | column -t
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx:5678-80 */ tcp dpt:30965
KUBE-SVC-VXA2I2E2TLP6KZO2 tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx:5678-80 */ tcp dpt:30965
您应该看到输出显示目标是针对发往您的的数据包NodePort 30965。
然后验证kube-proxy正在侦听NodePort。
在正常情况下,kube-proxy绑定并侦听所有NodePorts端口以确保保留这些端口,并且其他任何进程都不能使用它们。您可以在上面的kubernetes节点上对此进行验证:
[root@master ~]# lsof -i:30965
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
kube-prox 10122 root 8u IPv6 90163732 0t0 TCP *:30965 (LISTEN)
[root@master ~]# ps -aef |grep -v grep |grep 10122
root 10122 10089 0 1月12 ? 00:09:11 /usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=master
或者通过netstat查看监听的端口
[root@master ~]# netstat -anpt |grep 30965
tcp6 0 0 :::30965 :::* LISTEN 10122/kube-proxy
[root@master ~]# netstat -anpt |grep LISTEN
tcp 0 0 0.0.0.0:2049 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:33830 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 2402/kubelet
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 10122/kube-proxy
tcp 0 0 127.0.0.1:9099 0.0.0.0:* LISTEN 12624/calico-node
tcp 0 0 192.168.2.10:2379 0.0.0.0:* LISTEN 8364/etcd
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 8364/etcd
tcp 0 0 192.168.2.10:2380 0.0.0.0:* LISTEN 8364/etcd
tcp 0 0 127.0.0.1:2381 0.0.0.0:* LISTEN 8364/etcd
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 705/rpcbind
tcp 0 0 0.0.0.0:20048 0.0.0.0:* LISTEN 4530/rpc.mountd
tcp 0 0 127.0.0.1:10257 0.0.0.0:* LISTEN 8325/kube-controlle
tcp 0 0 0.0.0.0:179 0.0.0.0:* LISTEN 12809/bird
tcp 0 0 127.0.0.1:10259 0.0.0.0:* LISTEN 8281/kube-scheduler
tcp 0 0 0.0.0.0:51348 0.0.0.0:* LISTEN 28856/rpc.statd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 954/sshd
tcp 0 0 127.0.0.1:44024 0.0.0.0:* LISTEN 2402/kubelet
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1371/master
tcp6 0 0 :::2049 :::* LISTEN -
tcp6 0 0 :::10250 :::* LISTEN 2402/kubelet
tcp6 0 0 :::6443 :::* LISTEN 8338/kube-apiserver
tcp6 0 0 :::10251 :::* LISTEN 8281/kube-scheduler
tcp6 0 0 :::10252 :::* LISTEN 8325/kube-controlle
tcp6 0 0 :::54703 :::* LISTEN 28856/rpc.statd
tcp6 0 0 :::111 :::* LISTEN 705/rpcbind
tcp6 0 0 :::20048 :::* LISTEN 4530/rpc.mountd
tcp6 0 0 :::10256 :::* LISTEN 10122/kube-proxy
tcp6 0 0 :::37075 :::* LISTEN -
tcp6 0 0 :::30965 :::* LISTEN 10122/kube-proxy
tcp6 0 0 :::22 :::* LISTEN 954/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1371/master
您应该看到30965被kube-proxy正在监听。在iptables模式下,为kubernetes服务创建iptables规则,以确保对get的请求 被路由(并负载均衡)到适当的pod。
只要这些iptables规则存在,即使节点上的kube-proxy进程死亡,对服务的请求也将被路由到适当的pods。但是,新service的端点不能从这个节点工作,因为kube-proxy进程不会为它创建iptables规则。
如果你还对它疑惑🤔,好吧,这次我不会对它做其他的解释了,后面如果有新文章还会产出,另外我找到推特上来自一名Kubernetes, GKE, &谷歌云首席软件工程师发的帖子,他详细描述了 Kubernetes kube-proxy iptables规则流程图,希望它可以帮助到你,如果想获取的话,可以到公众号输入iptables即可获取
为什么要更换kube-proxy?
那么,为什么要替换kube-proxy呢?好吧,第一个原因只是为了一些个人实验:)。kube-proxy组件已被广泛使用,就像事实上的部署一样,因此没有真正的理由无故删除它。上面与iptables相关的入门文章中也暗示了另一个原因。让我们做一个简单的实验。
现在让我们做一个“愚蠢的”测试。我们将使用相同的选择器添加100个服务,这些服务指向我们当前使用不同服务名称的nginx部署
我们需要单独安装一个yq的解析yaml可以改动yaml文件的工具
如果你想学习可以参考这个开源工具并安装上 https://github.com/mikefarah/yq
[root@master ~]# for i in {1..100}; do yq w nginx-svc.yaml "metadata.name" "nginx-"$i | kubectl apply -n default -f -; done
service/nginx-1 created
service/nginx-2 created
service/nginx-3 created
service/nginx-4 created
...
100
现在,我们有100个service都指向同一个Pod。如果我们现在看一下iptables
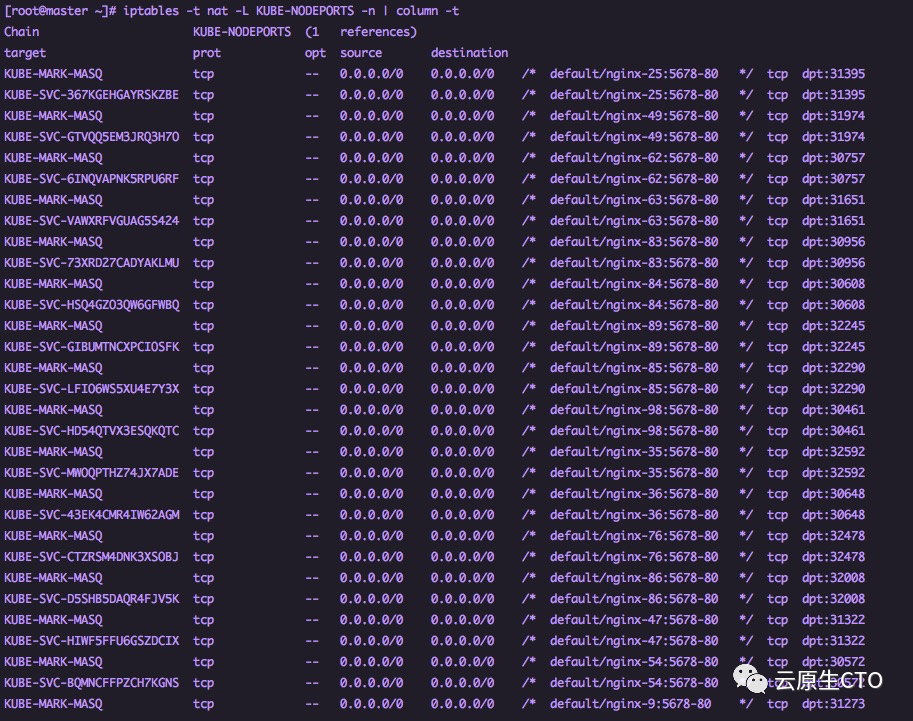
如我们所见,kube-proxy为定义的每个新服务添加了iptables规则集。随着服务数量的增加,此列表将变得非常庞大,并且可能会影响性能,因为iptables处理是顺序的。规则在链中越向下,处理所需的时间就越长。
哈哈,甚至面试当中会问到这些,希望这次的演示可以帮你深刻的理解它。
回归正题,那么我们可以删除kube-proxy,不使用iptable换成其它的替换它吗?是,可以的。解决方案(或潜在解决方案之一)在于使用eBPF(扩展的Berkeley数据包过滤器)。
什么是eBPF?
全面而深入的技术理解超出了本实验的范围,甚至超出了我自己的技能范围,但以简单的术语来说,eBPF(扩展的Berkeley Packet Filter)是在Linux机器的内核中运行的虚拟机。它能够运行本地实时编译的“ bpf程序”,这些程序可以访问某些内核功能。换句话说,用户可以在运行时按需注入这些程序以在内核中运行。这些程序遵循bpf提供的特定指令集,并具有某些需要遵循的规则,并且将仅运行可以安全运行的程序。这与Linux模块不同,后者也在内核中运行,但是如果编写不正确,可能会导致内核出现问题。
我将把这些细节推送到有关BPF的大量文章上。但是,该虚拟机可以连接到诸如网络设备之类的任何内核子系统,并且BPF程序会响应这些子系统上的事件而执行。最古老,最受欢迎的Linux工具之一-tcpdump使用BPF。我很想说像智能nics等新技术都利用了BPF,但对我而言这只是一个疯狂的猜测。
使用eBPF用CNI驱动程序替换kube-proxy cilium项目利用eBPF实施其网络策略,还提供了kube-proxy替代产品。Calico项目还具有使用eBPF的技术预览,但是对于本实验,我们将仅使用Cilium。
Cilium kube-proxy免费安装
这实际上非常简单。关于内核版本,存在某些先决条件。内核版本至少应为4.19,但建议版本> v5.3。我们只需要遵循此处概述的步骤 https://docs.cilium.io/zh/v1.7/gettingstarted/kubeproxy-free/
如果你的版本过低会产生下面的报错

对于1.15和更低版本的K8S,我们首先在主机上删除kube-proxy的守护程序集并清空iptables,然后再添加其他节点
#kubectl -n kube-system delete ds kube-proxy
#iptables-restore <(iptables-save | grep -v KUBE)
对于1.16及更高版本,我们可以完全跳过kube-proxy
kubeadm init --pod-network-cidr=10.217.0.0/16 --skip-phases=addon/kube-proxy
直接使用helm,这将安装Cilium作为CNI插件,替换为BPF kube-proxy,以实现处理ClusterIP,NodePort,ExternalIPs和LoadBalancer类型的Kubernetes服务。
helm repo add cilium https://helm.cilium.io/
helm install cilium cilium/cilium --version 1.7.12 \
--namespace kube-system \
--set global.kubeProxyReplacement=strict \
--set global.k8sServiceHost=API_SERVER_IP \
--set global.k8sServicePort=API_SERVER_PORT
最后,作为最后一步,请验证Cilium是否已在所有节点上正确启动并准备就绪
如我们所见,没有kube-proxy pod。现在,我们可以像上面一样创建nginx部署和单个服务,并检查iptables。
#kubectl get pods -n benchmark -o wide
NAME READY STATUS RESTARTS AGE IP
nginx-8694799779-f8h82 1/1 Running 0 2d19h 101.96.1.18
#kubectl get service nginx-svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx-svc ClusterIP 101.67.9.101 <none> 80/TCP 2d19h app=nginx
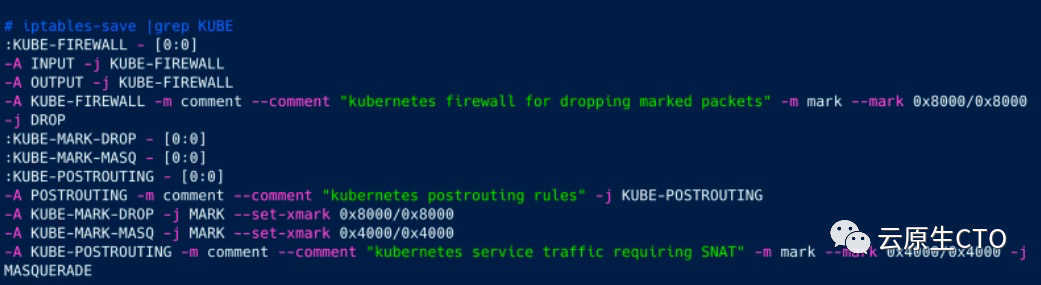
如我们所见,它为KUBE添加了一些基本规则,但没有KUBE-SERVICES存在。让我们像上面的测试一样添加100个服务,然后再次检查iptables。
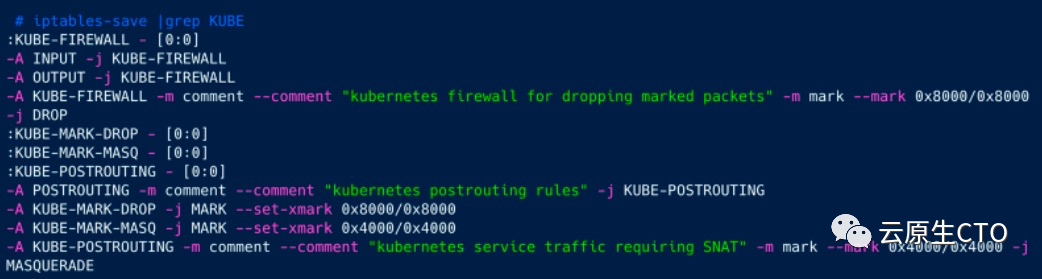
完全一样。因此,我们摆脱了庞大的iptables规则,但是性能呢?让我们做一些测试。
简单的性能测试
为了测试这两个设置的性能,我们在两个设置上部署了一个运行ubuntu和apache bench的简单pod。我们确保apache工作台上的nodeSelector与运行nginx的节点不同,以便我们可以跨节点进行网络延迟。
此设置绝不是完全优化的生产设置,因此这里的结果是要注意的是,在不同的环境中情况可能有所不同,但是仍然可以在相同的基础上进行比较。部署如下所示
apiVersion: apps/v1
kind: Deployment
metadata:
name: apachebench
spec:
selector:
matchLabels:
app: apachebench
template:
metadata:
labels:
app: apachebench
spec:
nodeSelector:
apptype: apachebench
containers:
- name: ubuntu
image: ubuntu
command: ["/bin/sleep", "3650d"]
部署完成后,我们将得到以下内容

我们可以看到两个pod都在不同的节点上。现在,我们只需在ubuntu pod上安装apache bench,然后运行一个简单的ab测试,即可从单个连接发送100000个请求。
#kubectl exec -it apachebench-7db7b745c6-9cf9z /bin/bash -n benchmark
root@apachebench-7db7b745c6-9cf9z:/# ab -n 100000 -c 1 http://nginx-svc/
This is ApacheBench, Version 2.3 <$Revision: 1807734 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking nginx-svc (be patient)
Completed 10000 requests
Completed 20000 requests
Completed 30000 requests
Completed 40000 requests
Completed 50000 requests
Completed 60000 requests
Completed 70000 requests
Completed 80000 requests
Completed 90000 requests
Completed 100000 requests
Finished 100000 requests
Server Software: nginx/1.17.10
Server Hostname: nginx-svc
Server Port: 80
Document Path: /
Document Length: 612 bytes
Concurrency Level: 1
Time taken for tests: 78.948 seconds
Complete requests: 100000
Failed requests: 0
Total transferred: 84600000 bytes
HTML transferred: 61200000 bytes
Requests per second: 1266.65 [#/sec] (mean)
Time per request: 0.789 [ms] (mean)
Time per request: 0.789 [ms] (mean, across all concurrent requests)
Transfer rate: 1046.47 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 6
Processing: 0 0 0.1 0 4
Waiting: 0 0 0.1 0 4
Total: 0 1 0.1 1 7
Percentage of the requests served within a certain time (ms)
50% 1
66% 1
75% 1
80% 1
90% 1
95% 1
98% 1
99% 1
100% 7 (longest request)
root@apachebench-7db7b745c6-9cf9z:/#
如果我们通过将集群中nginx服务的数量从1,100,1000,2000,3000,4000,5000增加到两个设置来运行此测试,并绘制比较图表,我们可以看到
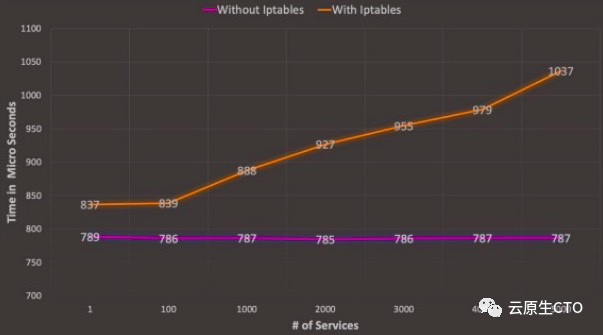
正如我们看到的iptables(kube-proxy)和bpf设置开始时相对接近800微秒,但是随着服务数量的增加,iptables设置性能开始下降.bpf设置趋于或多或少保持恒定。现在很明显,当我们添加更多不同类型的负载时,这些负载甚至可能进一步不同,但是该图至少显示了在这种特定情况下,iptables的顺序处理如何在定义的大量规则上导致性能下降。
最终观察
我们已经看到了如何使用基于bpf的规则集摆脱基于kube-proxy和iptables的规则集。但是,这种性能下降在多大程度上真正影响了生产系统,这真的是必须做的吗?与往常一样,此类问题的答案是-这取决于:)。如果它是一个很小或中等的集群,并且没有很多服务或网络策略,那么kube-proxy版本可能会正常工作。实际上,它对许多kubernetes用户来说都是透明的。
但是,请想象一个大型集群,该集群在运行大量服务的多租户系统中具有100个租户。加上运行istio之类的副车代理的应用程序,其本身大量使用iptables。如果遇到iptables瓶颈,这种情况下所有租户的性能都会下降。因此,这种替代方法是一个有趣的探索途径。kube-proxy很有可能在某个时候开始在内部使用eBPF,并且所有这些更改都变得透明。
基于BPF的CNI驱动程序仍然相对较新,它们在等待时可能会有自己的优化,因此很难说是否已经准备好开箱即用,但这是值得期待的令人兴奋的领域。
参考文献
观看来自Facebook的精彩会议,了解他们在iptables上使用bpf防火墙的情况-http: vger.kernel.org/lpc_net2018_talks/ebpf-firewall-LPC.pdf和此处的视频https://www.youtube.com/watch ?v = XpBzEq1MwI8
为什么内核社区用BPF代替iptables?https://cilium.io/blog/2018/04/17/why-is-the-kernel-community-replacing-iptables
全面介绍eBPF 了解kubernetes网络 https://lwn.net/Articles/740157/
https://sysdig.com/blog/sysdig-and-falco-now-powered-by-ebpf/
https://medium.com/faun/kubernetes-without-kube-proxy-1c5d25786e18#3444
https://docs.cilium.io/en/v1.7/gettingstarted/kubeproxy-free/
https://serverfault.com/questions/1042705/kubernetes-and-iptables-forward-external-traffic-to-specific-nodeport
我等的船还不来
我等的人还不明白
寂寞默默沉没 沉入海 未来不再我还在「——任贤齐 伤心太平洋」。
【一个懂你的云原生知识共享平台】
「欢迎扫描下方二维码关注」

