




本文源自对菜鸟教程中MongoDB学习的总结,仅为个人笔记,不做商业用途。
一、概念及简单语法
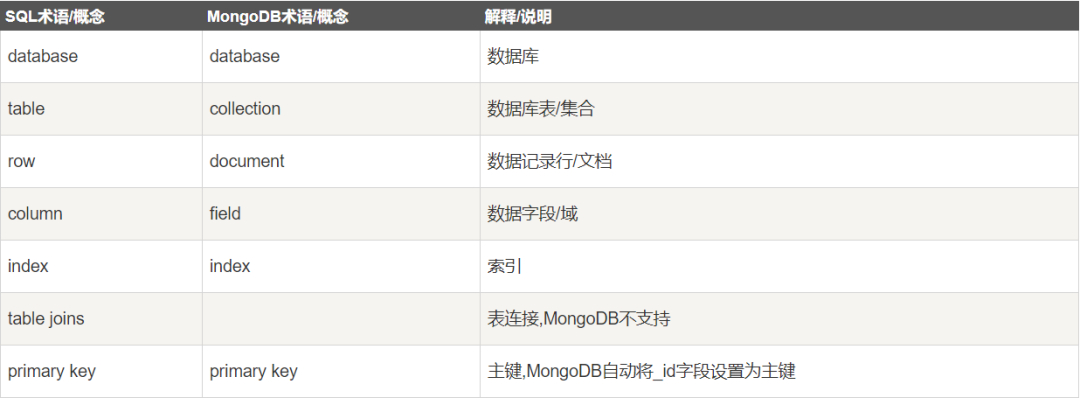
1.对比
我们平时用的关系型数据库比如Oracle与MonogoDB 的一些对比:
2.数据库
一个MongoDB中可以建立多个数据库。
MongoDB的默认数据库为"db",该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
不能是空字符串("")。
不得含有' '(空格)、.、$、/、\和\0 (空字符)。
应全部小写。
最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
3.文档(Document)
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
下表列出了 RDBMS 与 MongoDB 对应的术语:
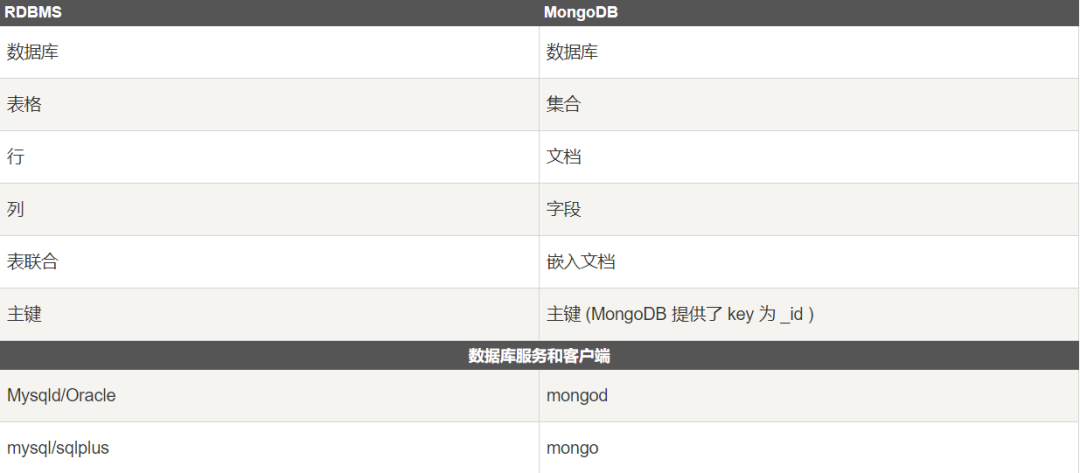
需要注意的是:
文档中的键/值对是有序的。
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
MongoDB区分类型和大小写。
MongoDB的文档不能有重复的键。
文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
键不能含有\0 (空字符)。这个字符用来表示键的结尾。
.和$有特别的意义,只有在特定环境下才能使用。
以下划线"_"开头的键是保留的(不是严格要求的)。
4.集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
我们可以将不同数据结构的文档插入到集合中,当第一个文档插入时,集合就会被创建。
合法的集合名命名规则:
集合名不能是空字符串""。
集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
集合名不能以"system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
capped collections
Capped collections 就是固定大小的collection,集合的一种。
它有很高的性能以及队列过期的特性 (过期按照插入的顺序) 有点和 "RRD" 概念类似。
Capped collections 是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。
Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息,如:
db.createCollection("mycoll", {capped:true, size:100000})
在 capped collection 中:
能添加新的对象。
能进行更新,然而,对象不能增加存储空间。如果增加,更新就会失败 。
使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
删除之后,你必须显式的重新创建这个 collection。
在32bit机器中,capped collection 最大存储为 1e9( 1X109)个字节。
5.元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:
dbname.system.*
在MongoDB数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合(Collection),如下:
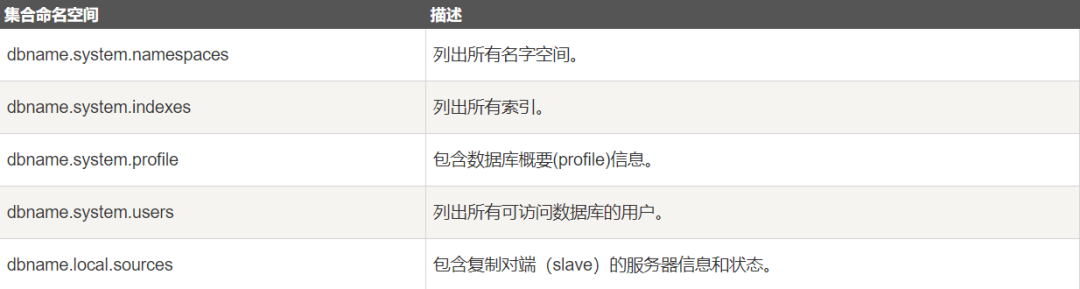
对于修改系统集合中的对象有如下限制:
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。
{{system.profile}}是可删除的。
6.MongoDB 数据类型
下表为MongoDB中常用的几种数据类型。

下面说明下几种重要的数据类型。
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
接下来的 3 个字节是机器标识码
紧接的两个字节由进程 id 组成 PID
最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象。
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()> newObject.getTimestamp()ISODate("2017-11-25T07:21:10Z")## ObjectId 转为字符串> newObject.str5a1919e63df83ce79df8b38f
字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的日期类型不相关。 时间戳值是一个 64 位的值。其中:
前32位是一个 time_t 值(与Unix新纪元相差的秒数)
后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
常见用法:
> var mydate1 = new Date()> mydate1ISODate("2019-10-24T05:43:36.687Z")> typeof mydate1object
注意:区分大小写
> var mydatestr = mydate1.tostring()2019-10-23T22:46:09.477-0700 E QUERY TypeError: Object Wed Oct 23 2019 22:43:36 GMT-0700 (PDT) has no method 'tostring'at (shell):1:25> var mydatestr = mydate1.toString()> mydatestrWed Oct 23 2019 22:43:36 GMT-0700 (PDT)> typeof mydatestrstring
或者使用Date(),Date是一个function
> Date()Wed Oct 23 2019 22:47:57 GMT-0700 (PDT)
感觉有点像JS的用法,还有点像Java的用法
二、MongoDB 创建数据库
语法:
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
> use ljingswitched to db ljing> dbljing
如果你想查看所有数据库,可以使用 show dbs 命令:
> show dbslocal 0.078GB
可以看到我们新建的数据库ljing不在,需要我们插入一些数据
> db.ljing.insert({"name":"ljing"})WriteResult({ "nInserted" : 1 })> show dbsljing 0.078GBlocal 0.078GB
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
三、MongoDB 删除数据库
例:删除数据库 ljing
首先,查看所有数据库:
> show dbsljing 0.078GBlocal 0.078GB
切换到ljing数据库
> use ljingswitched to db ljing
删除当前数据库
> db.dropDatabase(){ "dropped" : "ljing", "ok" : 1 }
这里很奇怪,我查看当前在那个数据库的时候,还是显示ljing,但是刚刚明明已经删掉了
> dbljing
再看下当前有哪些数据库,确实删掉了
> show dbslocal 0.078GB
四、MongoDB 创建集合
MongoDB 中使用 createCollection() 方法来创建集合。
语法格式:
db.createCollection(name, options)
参数说明:
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
其中options 可以是如下参数:

实例:在 test 数据库中创建 ljing 集合:
切换到test
> use testswitched to db test
查看当前位置
> dbtest
创建集合ljing
> db.createCollection("ljing"){ "ok" : 1 }
查看当前所有集合
> show tablesljingsystem.indexes## 或者> show collectionsljingsystem.indexes
下面是带有几个关键参数的 createCollection() 的用法:
创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection("mycol",{capped:true,autiIndexId:true,size:6142800,max:10000}){ "ok" : 1 }// 重复创建会报错> db.createCollection("mycol",{capped:true,autiIndexId:true,size:6142800,max:10000}){ "ok" : 0, "errmsg" : "collection already exists", "code" : 48 }
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({"name":"ljing"})WriteResult({ "nInserted" : 1 })## 查看集合> show collectionsljingmycolmycol2system.indexes
五、删除集合
集合删除语法格式如下:
db.collection.drop()
例:删除了 ljing 数据库中的集合 ljing:
> use ljingswitched to db ljing
先创建一个集合,类似表
> db.createCollection("ljing"){ "ok" : 1 }
查看当前集合
> show tablesljingsystem.indexes
删掉ljing集合
> db.ljing.drop()true
查看当前集合,确认已经删除成功
> show tablessystem.indexes
六、MongoDB 插入文档
文档的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
BSON简介:BSON是由10gen开发的一个数据格式,目前主要用于MongoDB中,是MongoDB的数据存储格式。BSON基于JSON格式,选择JSON进行改造的原因主要是JSON的通用性及JSON的schemaless的特性。
BSON主要会实现以下三点目标:更快的遍历速度;操作更简易;增加了额外的数据类型
插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
实例
以下文档可以存储在 MongoDB 的 test 数据库 的 col 集合中:
>db.col.insert({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '简书_ljing',url: 'https://www.jianshu.com/u/0bf03bc04b07',tags: ['mongodb', 'database', 'NoSQL'],likes: 100})WriteResult({ "nInserted" : 1 })
以上实例中 col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
查看已插入文档:
> db.col.find(){ "_id" : ObjectId("5db2afe105cb23a6ee2504b3"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "简书_ljing", "url" : "https://www.jianshu.com/u/0bf03bc04b07", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
我们也可以将数据定义为一个变量,如下所示:
> document=({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '简书_ljing',url: 'https://www.jianshu.com/u/0bf03bc04b07',tags: ['mongodb', 'database', 'NoSQL'],likes: 100});// 执行后显示结果如下:{"title" : "MongoDB 教程","description" : "MongoDB 是一个 Nosql 数据库","by" : "简书_ljing","url" : "https://www.jianshu.com/u/0bf03bc04b07","tags" : ["mongodb","database","NoSQL"],"likes" : 100}
执行插入操作:
> db.col.insert(document)WriteResult({ "nInserted" : 1 })
插入文档你也可以使用 db.col.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
七、MongoDB 更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
(一)update() 方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(<query>,<update>,{upsert: <boolean>,multi: <boolean>,writeConcern: <document>})
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern : 可选,抛出异常的级别。
实例
我们先查看下 col 中已经插入的数据:
> db.col.find(){ "_id" : ObjectId("5db2afe105cb23a6ee2504b3"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "简书_ljing", "url" : "https://www.jianshu.com/u/0bf03bc04b07", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }{ "_id" : ObjectId("5db2b0a805cb23a6ee2504b6"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "简书_ljing", "url" : "https://www.jianshu.com/u/0bf03bc04b07", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
接着我们通过 update() 方法来更新标题(title):
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息> db.col.find().pretty(){"_id" : ObjectId("5db2afe105cb23a6ee2504b3"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "简书_ljing","url" : "https://www.jianshu.com/u/0bf03bc04b07","tags" : ["mongodb","database","NoSQL"],"likes" : 100}{"_id" : ObjectId("5db2b0a805cb23a6ee2504b6"),"title" : "MongoDB 教程","description" : "MongoDB 是一个 Nosql 数据库","by" : "简书_ljing","url" : "https://www.jianshu.com/u/0bf03bc04b07","tags" : ["mongodb","database","NoSQL"],"likes" : 100}
可以看到第一个标题(title)由原来的 "MongoDB 教程" 更新为了 "MongoDB",第二个并没有更新。
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
执行如上sql后发现两条都被修改了
(二)save() 方法
save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(<document>,{writeConcern: <document>})
参数说明:
document : 文档数据。
writeConcern :可选,抛出异常的级别。
实例
替换了 _id 为 5db2b0a805cb23a6ee2504b6 的文档数据:
>db.col.save({"_id" : ObjectId("5db2b0a805cb23a6ee2504b6"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "简书_ljing","url" : "https://www.jianshu.com/u/0bf03bc04b07","tags" : ["mongodb","NoSQL"],"likes" : 110})
替换成功后,我们可以通过 find() 命令来查看替换后的数据
>db.col.find().pretty(){"_id" : ObjectId("5db2afe105cb23a6ee2504b3"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "简书_ljing","url" : "https://www.jianshu.com/u/0bf03bc04b07","tags" : ["mongodb","database","NoSQL"],"likes" : 100}{"_id" : ObjectId("5db2b0a805cb23a6ee2504b6"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "简书_ljing","url" : "https://www.jianshu.com/u/0bf03bc04b07","tags" : ["mongodb","NoSQL"],"likes" : 110}
更多实例
只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
全部添加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
八、MongoDB 删除文档
MongoDB remove()函数是用来移除集合中的数据。
MongoDB数据更新可以使用update()函数。
在执行remove()函数前可以先执行find()命令来判断执行的条件是否正确。
remove() 方法的基本语法格式如下所示:
db.collection.remove(<query>,<justOne>)
如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(<query>,{justOne: <boolean>,writeConcern: <document>})
参数说明:
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
writeConcern :(可选)抛出异常的级别。
实例
以下文档我们执行两次插入操作:
> db.col.insert({"name":"ljing"})WriteResult({ "nInserted" : 1 })> db.col.insert({"name":"ljing"})WriteResult({ "nInserted" : 1 })
使用 find() 函数查询数据:
> db.col.find(){ "_id" : ObjectId("5db2be7e05cb23a6ee2504b7"), "name" : "ljing" }{ "_id" : ObjectId("5db2be8605cb23a6ee2504b8"), "name" : "ljing" }
执行删除
> db.col.remove({"name":"ljing"})WriteResult({ "nRemoved" : 2 }) # 删除了两条数据>db.col.find()…… # 没有数据
如果你只想删除第一条找到的记录可以设置 justOne 为 1,如下所示:
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
如果你想删除所有数据,可以使用以下方式(类似常规 SQL 的 truncate 命令):
>db.col.remove({})>db.col.find()
九、MongoDB 查询文档
MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档。
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
以下实例我们查询了集合 col 中的数据:
> db.col.find().pretty(){ "_id" : ObjectId("5db2c01305cb23a6ee2504b9"), "name" : "ljing" }{ "_id" : ObjectId("5db2c01405cb23a6ee2504ba"), "name" : "ljing" }{ "_id" : ObjectId("5db2c02105cb23a6ee2504bb"), "name" : "liang" }
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
> db.col.findOne(){ "_id" : ObjectId("5db2c01305cb23a6ee2504b9"), "name" : "ljing" }
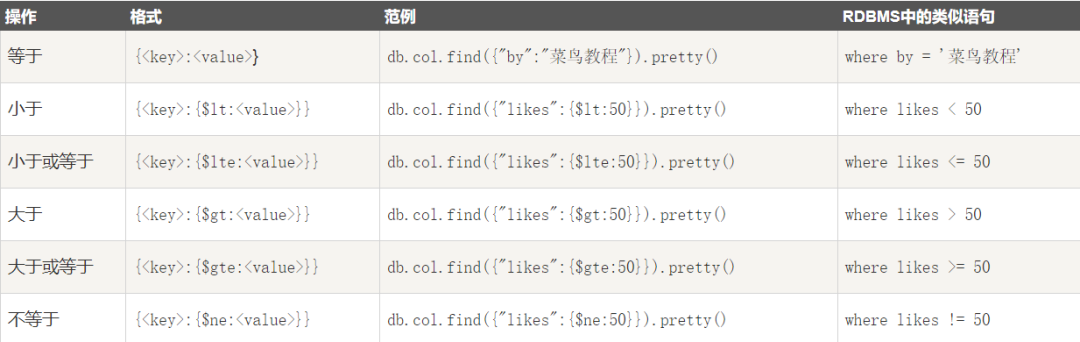
MongoDB 与 RDBMS Where 语句比较
(一)MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
>db.col.find({key1:value1, key2:value2}).pretty()
实例
先查看下所有数据
> db.col.find().pretty(){"_id" : ObjectId("5db2c17905cb23a6ee2504bc"),"name" : "ljing","title" : "mongdb","by" : "cainiao"}{"_id" : ObjectId("5db2c18e05cb23a6ee2504bd"),"name" : "ljing","title" : "oracle","by" : "oracle"}
发现自己把mongodb写错了,update一下啊
> db.col.update({"title":"mongdb"},{$set:{"title":"mongodb"}})WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
按name和title进行查询
> db.col.find({"name":"ljing","title":"mongodb"}).pretty(){"_id" : ObjectId("5db2c17905cb23a6ee2504bc"),"name" : "ljing","title" : "mongodb","by" : "cainiao"}
以上实例中类似于 WHERE 语句:WHERE name = ‘ljing’ and title = 'mongodb'
(二)MongoDB OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find({$or: [{key1: value1}, {key2:value2}]}).pretty()
以下实例中,我们演示了查询 title 值为 mongodb 或键 title 值为 oracle 的文档。
> db.col.find({$or:[{"title":"mongodb"},{"title":"oracle"}]}).pretty(){"_id" : ObjectId("5db2c17905cb23a6ee2504bc"),"name" : "ljing","title" : "mongodb","by" : "cainiao"}{"_id" : ObjectId("5db2c18e05cb23a6ee2504bd"),"name" : "ljing","title" : "oracle","by" : "oracle"}
(三)AND 和 OR 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where name = 'ljing' AND (title = 'mongodb' OR title = 'oracle')'
> db.col.find({"name": "ljing", $or: [{"title": "mongodb"},{"title": "oracle"}]}).pretty(){"_id" : ObjectId("5db2c17905cb23a6ee2504bc"),"name" : "ljing","title" : "mongodb","by" : "cainiao"}{"_id" : ObjectId("5db2c18e05cb23a6ee2504bd"),"name" : "ljing","title" : "oracle","by" : "oracle"}
