




参数说明
fs.aio-max-nr = 4194304 异步IO
进程多的时候,报ora-27090
fs.file-max = 6815744
kernel.shmall = 4194304 允许的最大共享内存大小*4k
建议物理内存的90%
kernel.shmmax = 16106127360 单个共享内存段支持的最大内存
设置比sga_max_size大一点就可以
kernel.shmmni = 4096 1台机器上可以启动多少个ORACLE实例
kernel.panic_on_oops =1 linux出现内核错误时,重启
kernel.panic =10 等待10秒后重启
net.ipv4.ip_local_port_range = 9000 65500
vm.vfs_cache_pressure=200 操作系统倾向于回收文件内存,用于计算内存
vm.swappiness=10
vm.min_free_kbytes=102400 防止高并发情况下,内存耗尽
echo “NOZEROCONF=yes” >> etc/sysconfig/network Rac环境
systemctl stop avahi-dnsconfd rac环境,linux 7
systemctl stop avahi-daemon
systemctl disable avahi-dnsconfd
systemctl disable avahi-daemon
关闭透明大页,重启
cat etc/default/grub
transparent_hugepage=never numa=off 有问题,没生效
grub2-mkconfig –o boot/grub2/grub.cfg
for disk in ‘ls dev/sd*’
do
echo $disk
/usr/lib/udev/scsi_id –whitelisted –replace-whitespace –device=$disk
done

udevadm control –reload-rules
udevadm trigger
使用memory_target
cat etc/fstab
tmpfs dev/shm tmpfs defaults,size=10g 0 0
mount –o remount dev/shm
grep Huge proc/meminfo
anonhugepages 有值说明开了透明打页
sga=物理内存*0.8*0.8
pga=物理内存*0.8*0.2
asm 磁盘,放数据的用4M,AU SIZE
AIX看不到盘,看下IOCP有没有开
linux7 安装11g ,执行root.sh之前要安装一个补丁
18370031
11.2.0.4没打任何补丁的情况下,修改SCAN_IP,服务不会再监听注册,需要重启crs
网络风暴或网络trunk改变会造成RAC监听进程消失,自动拉起又正常。监听每秒能抗住20个连接。
使用多个监听处理高并发
查询v$archive_gap慢,
很慢,可能是BUG,Doc ID 18411339.8
select USERENV('Instance'), high.thread#, low.lsq, high.hsqfrom(select a.thread#, rcvsq, min(a.sequence#)-1 hsqfrom v$archived_log a,(select lh.thread#, lh.resetlogs_change#, max(lh.sequence#) rcvsqfrom v$log_history lh, v$database_incarnation diwhere lh.resetlogs_time = di.resetlogs_timeand lh.resetlogs_change# = di.resetlogs_change#and di.status = 'CURRENT'and lh.thread# is not nulland lh.resetlogs_change# is not nulland lh.resetlogs_time is not nullgroup by lh.thread#, lh.resetlogs_change#) bwhere a.thread# = b.thread#and a.resetlogs_change# = b.resetlogs_change#and a.sequence# > rcvsqgroup by a.thread#, rcvsq) high,(select srl_lsq.thread#, nvl(lh_lsq.lsq, srl_lsq.lsq) lsqfrom(select thread#, min(sequence#)+1 lsqfromv$log_history lh, x$kccfe fe, v$database_incarnation diwhere to_number(fe.fecps) <= lh.next_change#and to_number(fe.fecps) >= lh.first_change#and fe.fedup!=0 and bitand(fe.festa, 12) = 12and di.resetlogs_time = lh.resetlogs_timeand lh.resetlogs_change# = di.resetlogs_change#and di.status = 'CURRENT'group by thread#) lh_lsq,(select thread#, max(sequence#)+1 lsqfromv$log_historywhere (select min( to_number(fe.fecps))from x$kccfe fewhere fe.fedup!=0 and bitand(fe.festa, 12) = 12)>= next_change#group by thread#) srl_lsqwhere srl_lsq.thread# = lh_lsq.thread#(+)) lowwhere low.thread# = high.thread#and lsq < = hsqand hsq > rcvsq;
补丁介绍
12c 以上的版本补丁集叫RU;RUR是RU的patch
12c以下叫PSU
ONEOFF PATCH 单独推出的小补丁
$ORACLE_HOME/OPatch/opatch lsinv
•Database 11.2.0.4 Proactive Patch Information (Doc ID 2285559.1)
•Database 12.1.0.2 Proactive Patch Information (Doc ID 2285558.1)
•Database 12.2.0.1 Proactive Patch Information (Doc ID 2285557.1)
•Oracle Database 19c Proactive Patch Information (Doc ID 2521164.1)
•上面确认大的补丁集
•Things to Consider to Avoid Poor Performance or Wrong Results
•确认oneoff patch,在MOS搜索关键字Things to Consider to Avoid Poor
•Bug Issues Known to cause Wrong Results(Doc ID 1968095.1)这个要特殊账号才能看。
•建议打次新补丁,不要打最新补丁
•大版本升级业务要做全面的功能测试(如11.2.0.3à11.2.0.4)
•大版本升级前关注下AWR基表占用空间大小,否则执行DBUA时很慢
•安全扫描:登录式,不要探测式,给安全厂商一个用户,登录到数据库检查。
参数
参数 | 参数含义(来自mos) | 建议值 |
vm.nr_hugepages | vm.nr_hugepages = sga_max_size Hugepagesize | 根据SGA、pagesize设定 |
semmsl | maximum number of semaphores in a semaphore set | 250 |
semmns | maximum number of semaphores in the system | 32000 |
semopm | maximum number of operations per semop(P) call | 100 |
semmni | maximum number of semaphore sets in system | 128 |
kernel.shmall | Set SHMALL equal to the sum of all the SGAs on the system, divided by the page size. | |
kernel.shmmax | SHMMAX specifies the maximum bytes in one shared memory segment. | Half the size of physical memory in bytes |
kernel.shmmni |
| 4096 |
kernel.panic_on_oops | he below Kernel Parameter "panic_on_oops=1" is being Introduced and required from 12.1.0.2.0 onwards. | 1 |
fs.file-max | s.file-max defines the maximum number of file descriptors. | 6815744 |
fs.aio-max-nr |
| 1048576 |
net.ipv4.ip_local_port_range |
| Minimum: 9000 Maximum: 65500 |
net.core.rmem_defaul |
| 262144 |
net.core.rmem_max |
| 4194304 |
net.core.wmem_default |
| 262144 |
net.core.wmem_max |
| 1048576 |
net.ipv4.ip_local_port_range |
| 32768 61000 |
oracle/grid soft nproc 2047 (at least) |
v$sga_resize_ops 共享池调整情况,生产环境,shared_pool大小不要减少(视图里shrink)要注意,要避免这种情况,前端表现时快时慢。
可以设置个最小值
alter system set shared_pool_size=200m;
aix系统大量的换页,优先排查PGA
如使用flash卡,rac环境需配置db_flash_cache_file,db_flash_cache_size参数,且db_flash_cache_file对应不同的文件
show parameter cpu
cpu_count
resource_manager_cpu_allocation
配置resource manager,19c可以控制到session级别
begindbms_resource_manager.create_pending_area();dbms_resource_manager.create_plan(plan =>’MAXCAP_PLAN’,COMMENT =>’limit overall database CPU’);DBMS_RESOURCE_MANAGER_PLAN_DIRECTIVE(PLAN =>’MAXCAP_PLAN’,GROUP_OR_SUBPLAN =>’OTHER GROUPS’,COMMENT =>’this group is mandatory’,max_utilization_limit =>90%);dbms_resource_manager.validate_pending_area();dbms_resource_manager.submit_pending_area();end;/alter system set cpu_count=cpu数量。
2262 ,4194 错误处理 查文档??????
https://www.eygle.com/archives/2005/12/oracle_diagnostics_howto_deal_2662_error.html
27000的错,ASM很 吃光衰,链路要稳定
adrci>show problem 快速查找alert日志错误
lgwr trace文件尽量不要删除
rman 恢复后,要重建临时表空间
巡检时备份下控制文件;alter database backup controlfile to trace as /tmp/mousectl.ora';
备库切换到主库,注意看下是否有临时表空间。rman 恢复后要重建临时表空间
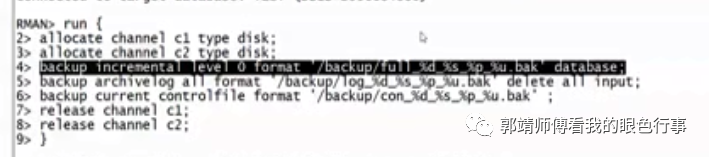
操作系统删归档日志文件后:
RMAN>crosscheck archivelog all;delete expired archivelog all;rman>run {allocate channel c1 type disk;allocate channel c2 type disk;backup incremental level 0 format ‘/backup/full_%d_%s_%p_%u.bak’ database;backup archivelog all format ‘/backup/log_%d_%s_%p_%u.bak’ delete all input;backup current controlfile format ‘/backup/con_%d_%s_%p_%u.bak’;release channel c1;release channel c2;}alter system set log_archive_dest_1=’location=/arch’;
AU size 放数据的磁盘选择4M
AIX没扫到盘,看IOCP有没有开
redhat7 安装oracle11g grid软件时,执行root.sh脚本前,打补丁18370031,还有19404309
rac 用netca重新配置,修改scan ip,实例无法注册,11.2.0.4 bug,要重启crs,未发布bug,监听没秒能扛住的连接数是20个,网络风暴会造成监听连接问题
windows上监听日志不要超过4G,
使用FGA可以对对象做审计,做细粒度审计,对性能影响不大。
安装数据库后的操作选项:
查看隐藏参数:
SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describFROM SYS.x$ksppi x, SYS.x$ksppcv yWHERE x.inst_id = USERENV('Instance')AND y.inst_id = USERENV('Instance')AND x.indx = y.indxAND (x.ksppinm = '_small_table_threshold' orx.ksppinm = '_serial_direct_read');
ASM
create pfile='/tmp/asm.ora' from spfile;
alter system set memory_max_target=4096m scope=spfile; 加大内存,避免4031错误
alter system set memory_target=1536m scope=spfile;
巡检时备份控制文件:
alter database backup controlfile to trace as ‘/tmp/ctl.ora’;
net.ipv4.conf.all_rp_filter sysctl.conf 需屏蔽这个参数或设置为0,(回包检测)会造成前端连接时快时慢,SUSE LINUX系统有这个。
打补丁之前,先重启CRS,确认以后打补丁和这个没关系。备份数据库,tar 备份软件目录
迁移流程,迁移前做SPA,对比性能
每秒连接数控制在20以下
死之前,查看diag日志,system state level=10 那段,还有resource manager那段信息
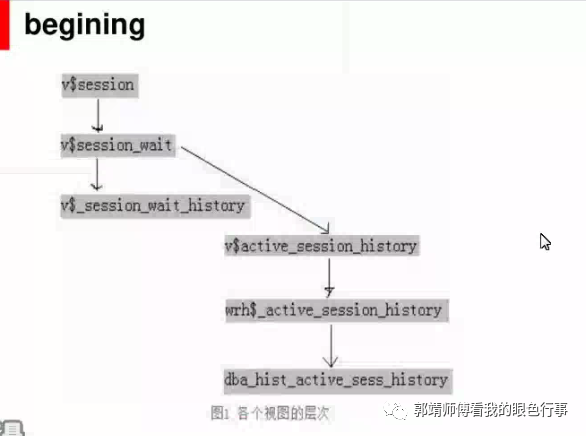
异常宕机,到dba_hist_active_sess_history
关注lgwr进程的trc文件,在trace目录下
Log file sync事件:
1.检查AWR log file parallel write并行写的时间,默认10ms以下
2.检查CPU负载
3.存储慢,控制器问题,光衰
4.检查异步IO,内存故障会影响异步io。
实例重启,看diag日志 pmon进程是在做死进程恢复吗
dba_hist_active_sess_history 查找对应的等待时间对应的进程,看看当时在做什么
巡检:
rda 收集信息 安装报告模板
12.1.0.2 for aix 平台不能用 RDA收集asm,会导致节点重启,禁止采集ASM模块
./rda.sh -vCRP ADBA ASM BEGIN CRS CUST DB DBA DBM END INST IPS IREQ LOG ONET OS PERF PROF NET
rda 巡检报告
负载重的环境中,oracheck没问题
rda 选择空闲时段跑,跑之前清除listener.log
oracheck,需要bash环境
巡检时执行:select name,path from v$asm_disk;
gpnptool get
rda 规范:
1) 检查监听器日志大小,如果过大(超过200M),重命名保存后进行清理,否则导致RDA结果集过大;
2) 检查$ORACLE_BASE/admin/$ORACLE_SID/adump/目录,文件超过1w个进行清理,否则RDA可能异常终止;
3) 在AIX7使用ASM的RAC环境里,请不要用RDA收集ASM部分
关注 600,7445 报错
select name,path from v$asm_disk; 这个体现在巡检报告里
create pfile=/tmp/asm.ora from spfile;
grid>gpnptool get
tfa 日志收集
/tfa/oracle.ahf/bin/tfactl diagcollect -all -from "Dec/7/2020 10:00:00" -to "Dec/7/2020 21:00:00"
tfactl>oratop 19c自带
快速查找TX源头sql>oradebug setmypidoradebug unlimitoradebug hanganalyze 3(oradebug tracefile_name)sqlplus -prelim as sysdba数据库HANG住,重启前操作:sql>oradebug setmypidoradebug unlimitoradebug dump systemstate 10(266 最好,但时间有点久,大概15分钟)oradebug dump systemstate 10oradebug tracefile_nameRAC环境HANG:oradebug setorapname recooradebug unlimitoradebug -g all hanganalyze 3oradebug -g all hanganalyze 3oradebug -g all dump systemstate 10oradebug -g all dump systemstate 10exit
如果连不上SQLPLUS:
•ps -ef |grep sqlplus(找外部连接sqlplus,jdbc java,不要找内部进程如pmon)
•ps -ef |grep PID
•dbx -a PID (AIX)
• gdb $ORACLE_HOME/bin/oracle PID LINUX
•print ksudss(10)
•Detach
没安装TFA情况下,收集日志
•
•每个节点的Alert.log
•每个节点的LMS[0|9] trace file.
•每个节点的LCK trace file
•每个节点的LMON trace文件
•每个节点的LMD0 trace文件
•每个节点的DIAGA trace 文件
•Alert log中提到的Trace 文件
•每个节点的LGWR trace file
DUMP 某个进程
•conn as sysdba
•SQL> oradebug setospid
•SQL> oradebug unlimit
•SQL> oradebug dump processstate 10
•等待3分钟左右
•SQL> oradebug dump processstate 10
•等待3分钟左右
•SQL> oradebug tracefile_name
RAC节点自动重启:
•需要搜集的信息(所有节点):
•l CRS Logs信息搜集
•l OS 信息搜集
•l OSW 信息搜集
•l Vendor cluster log 如果有的话
•l 其它OS 性能数据(如果没有OS 数据) 包含好的时间段和不好的时间段.
•l For pre-11.2, zip of var/opt/oracle/oprocd/* or etc/oracle/oprocd/*
•l For 11gR2+, zip of etc/oracle/lastgasp/* or var/opt/oracle/lastgasp/*
temp表空间异常增长事后分析:
依赖dba_hist_active_sess_history(误操作跟踪)
temp_allocated 抓取故障时间段每个会话
审计sys的操作
alter system set audit_sys_operation=true scope=spfile;
――禁止本地操作系统认证
修改sqlnet.ora,修改为
SQLNET.AUTHENTICATION_SERVICES=(NONE),
用户以后连接数据库需要输入用户名和密码
――tns登录IP限制
sqlnet.ora netca invalid_load ?? RAC 内联网络添加进去
select table_namefrom dba_tab_privswhere grantee = 'PUBLIC'and privilege = 'EXECUTE'AND table_name in ('UTL_FILE','UTL_TCP','UTL_HTTP','UTL_SMTP','DBMS_LOB','DBMS_SYS_SQL','DBMS_JOB','DBMS_SCHEDULER');
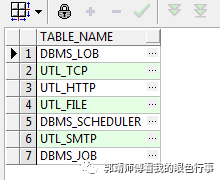
回收这些public权限:
例如:revoke execute on dbms_lob from public;
flashback drop 后,需要:
索引要改名,物化视图重新建立,外键的影响
如果误杀了回滚进程,SMON有可能会HANG住,这时可以使用oradebug wakeup pid(smon 进程号)重新唤醒
asm盘权限660,,,改777,会直接挂掉
AIX:
lsdev –Ccdisk
lsattr –El hdisk17 查看磁盘属性
注意policy属性,要修改
rebalance power 5 一般4,5 不要太大,除非没业务
如何修改数据库的归档模式?
•解决
Ø情况1:非RAC数据库
•Sqlplus “/ as sysdba”
•alter system set log_archive_format=‘
•alter system set log_archive_format=‘
•Alter system set log_archive_dest_1=‘location=/xx/xxx/xxx’ scope=spfile;
•Shutdown immediate
•Startup mount
•Alter database archivelog;
•Alter database open
发现某个会话占用资源很大,怎么杀掉该会话?
Ø解决
Ø方法一:
•查询出会话的sid,serial#
•select sid,serial# from v$session where …;
•Alter system kill session ‘sid,serial# ’immediate;
Ø方法二:
•查询出会话的paddr
•Select paddr from v$session where ….;
•进而找出spid
•Select spid from v$process where addr=‘上面查询的paddr’
•在操作系统上kill掉该进程
•kill -9
磁盘头损坏
•cd $ORACLE_HOME/rdbms/lib
• make -f ins_rdbms.mk ikfed
•kfed read dev/raw/raw20 AUNUM=1 BLKNUM=254 ausz=1048576 | more
•kfed read dev/raw/raw20 aun=0 blkn=0
•kfed repair dev/raw/raw20 aus=1048576
AU SIZE 4m,则是1022块有备份
1m,第254块
(加盘,导致监听挂掉)Network interface going down when dynamically adding disks to storage using udev in RHEL 6
•Add HOTPLUG="no" to the ifcfg-eth0 (public), ifcfg-eth1 (private) and ifcfg-eth2 (backup) network config files in etc/sysconfig/network-scripts directory
•udevadm control --reload-rules
•udevadm trigger --type=devices --action=change
expdp•expdp \"/ as sysdba\" directory=dumpdir schemas=scott dumpfile=scott_dump.dmp parallel=2 trace=480300•慢,用480300•impdp \"/ as sysdba\" directory=dumpdir dumpfile=scott_dump.dmp remap_schema=scott:test trace=480301 parallel=2•expdp system/**** PARALLEL=2 JOB_NAME=full_bak_job schemas=mouse dumpfile=exptest:back_%U.dmp logfile=exptest:back.log•impdp system/*** PARALLEL=2 EXCLUDE=STATISTICS JOB_NAME=full_imp cluster=no schemas=mouse dumpfile=test:back_%U.dmp logfile=test:back_imp.log;
•并行要加U%
查询恢复所需时间:
•
SELECT sid, serial#, context,sofar,totalwork,round(sofar/totalwork*100,2)"% Complete" FROM v$session_longops WHERE opname LIKE 'RMAN:%'AND opname NOT LIKE 'RMAN: aggregate%';rman>configure snapshot controlfile name to ‘+fra/hdprodb/controlfile/snap1.ctl’;crosscheck controlfilecopy ‘+fra/ddd/snap.ctl’;delete expired controlfilecopy ‘+fra/…/snap.ctl’;
ora-01653,01652 临时表空间满,
v$temp_space_header/v$sort_usage(查这个,不是前面那个试图)
•select TUNED_UNDORETENTION from V$UNDOSTAT group by TUNED_UNDORETENTION;
更换undo表空间文件时不要马上删除,保留几天,
aud$清理
•导出sys.aud$
•Truncate table sys.aud$
•BEGINDBMS_AUDIT_MGMT.SET_AUDIT_TRAIL_LOCATION(audit_trail_type => DBMS_AUDIT_MGMT.AUDIT_TRAIL_DB_STD,audit_trail_location_value => 'aud');END;/•BEGINDBMS_AUDIT_MGMT.SET_AUDIT_TRAIL_LOCATION(audit_trail_type => DBMS_AUDIT_MGMT.AUDIT_TRAIL_FGA_STD,audit_trail_location_value => 'aud');END;/
SYSAUX 清理
•@?/rdbms/admin/awrinfo.sql
•exec DBMS_STATS.PURGE_STATS(DBMS_STATS.PURGE_ALL) 清除统计信息,大版本升级时,清空下,否则DBUA,很慢,改语句适合11.2.0.3.8以上的系统,以下的用上面的SQL查询,然后单独truncate
•CREATE TABLE WRH$_ACTIVE_SESSION_HISTORY_B AS SELECT * FROM WRH$_ACTIVE_SESSION_HISTORY WHERE SNAP_ID>37679 可以先保留3天
•TRUNCATE TABLE WRH$_ACTIVE_SESSION_HISTORY;
select count(*) from t2 as of timestamp to_timestamp(‘2020-12-09 12:13:06’,’YYYY-MM-DD HH24:MI:SS’)
rac
内联网络建议配置多块网卡,配置多个网络,比如192.168.1.0;2.0;3.0 但真正走的还是169.254网络。
如甲方对169.254ip敏感,可设置db和asm的cluster_interconnects 参数修改IP,让内联网络用私有IP传输数据
OLTP系统上跨节点传输关掉:
parallel_force_local 设置true
关闭ora.crf资源,会导致单个cpu异常升高,11g关闭,12C可以不关闭
crsctl stop res ora.crf –init
[root@rac1 rac1]# /u01/app/11.2.0/grid/bin/crsctl modify res ora.crf -attr ENABLED=0 –init
temp是共享的,blocking change file 放在共享存储上
oracle19c rac
ora.rhpserver
ora.crs.ghchkpt.advm
ora.crs.ghchkpt.acfs
ora.helper
ora.proxy_advm
上面这几个进程是用来构建golden image的
#ocrconfig –showbakup 19c放在共享存储上,不能放在本地磁盘上
1.crsctl query css votedisk
2.gpnptool get
3.ocrconfig –showbackup
4.select name,path from v$asm_disk;
5.create pfile=’/tmp/asm.ora’ from spfile;
节点重启
1./etc/oracle/lastgasp/目录下日志cssagent ,可以区分是crs引起的主动重启还是主机硬件造成的重启
2.alert
3.ocssd.log
4.crsd.log
5.evmd.log
6.
lmon trace

是不是DRM引起
推荐 swingbench做压力测试
监听日志,,,过了每秒30就抗不住了
https://www.modb.pro/db/8630
分析监听日志IP信息
grep "HOST=.*establish.*\* 0" listener.log | awk -F'*' '{match($3,/[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+/); ip = substr($3,RSTART,RLENGTH);cnt[ip]+=1;last[ip]=$1;}END {for (i in cnt) printf "%-16s %9s %19s\n",i,cnt[i],last[i];}' | sort -k 1
如果监听掉了,手工拉又能起来,可以考虑是否网络攻击,检查crsd.log日志,看那个时间的监听日志,网络组排查那个时间段的情况,trunk变化。
试验,做了这个,造成gipcd报错,集群无法启动
crsctl modify res ora.cluster_interconnect.haip –attr “ENABLED=1” –init
rac 序列加大到800-1500
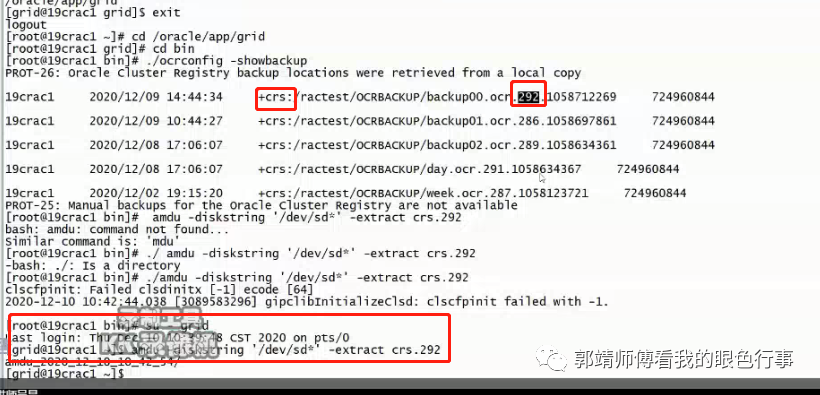
amdu抽取ASM 磁盘组中的数据,12.2以后,OCR备份文件要放到ASM磁盘中。巡检时拷贝出来
select count(*),event from v$session_wait group by event;
多输入几次,看下变化
awr
exec dbms_workload_repository.create_snapshot();手工创建快照
addm
sql>@?/rdbms/admin/addmrpt.sql
适合之前经历过大量行锁,然后用户已经重启过机器了,用户没有提供任何数据。可以生成ADDM报告,报告会给出当时的行锁情况
ps aux|head –1;ps aux|grep –v PID|sort –rn –k +3|head 按CPU排序
alter system set "_cursor_features_enabled" = 34 scope=spfile; AWR解析失败事件,临时
direct path read 排查流程
隐藏参数有没有关,表和索引是否开了并行
select degree from dba_tables group by degree;
SQL*NET message from client 排查网络通信问题
sql*net message break from client sql解析错误,找出语句找应用优化或设置参数临时规避
alter system set “_cursor_features_enabled”=34 scope=spfile;
1. Library cache lock
•排除密码错误问题(用户登录卡死),然后使用oradebug hanganalyze 3
2.Row cache lock
• (系统层面,CPU很空闲,HANG住) 优先怀疑sequence问题,伴随TX行锁https://www.xifenfei.com/2012/05/row-cache-lock%E7%AD%89%E5%BE%85%E4%BA%8B%E4%BB%B6.html
select sql_hash_value from v$session where event=’row cache lock’;
select sql_text from v$sql where hash_value=…
select sid,serial#,sql_hash_value from v$session where event=’db file scattered read’
3.log file sync 事件,
1.查看_use_adaptive_log_file_sync隐藏参数有没有关
2.跑这个脚本lfsdiag.sql ,看IO
历史统计信息的变更:
dba_tab_stats_history
•DX-contention 分布式事务,到对端机器查
•HW-contention 关注征用的是表还是索引,一般是索引,建HASH索引
5.db file sequential read,db file scatter read
awr报告,平均等待时间应该在10ms内,否则存储性能很差,这种实践优先看SQL
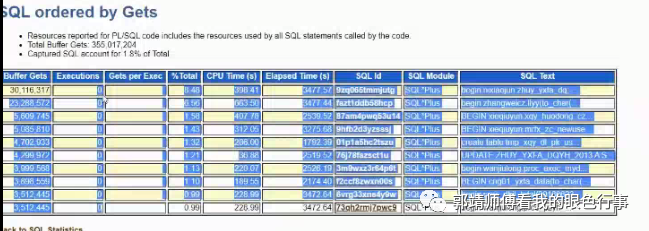
执行次数为0,表示采样时间内,一直在跑
在awr报告,看sql order by gets,sql order by read 找SQL
local write wait 等待事件看lgwr trace
27300错误,,持续性的写入慢,优先存储侧排查
查询执行计划变化
select a.instance_number,a.snap_id,a.plan_hash_value,b.begin_interval_timefrom dba_hist_sqlstat a,dba_hist_snapshot bwhere sql_id='' and a.snap_id=b.snap_id order by instance_number,begin_interval_time desc
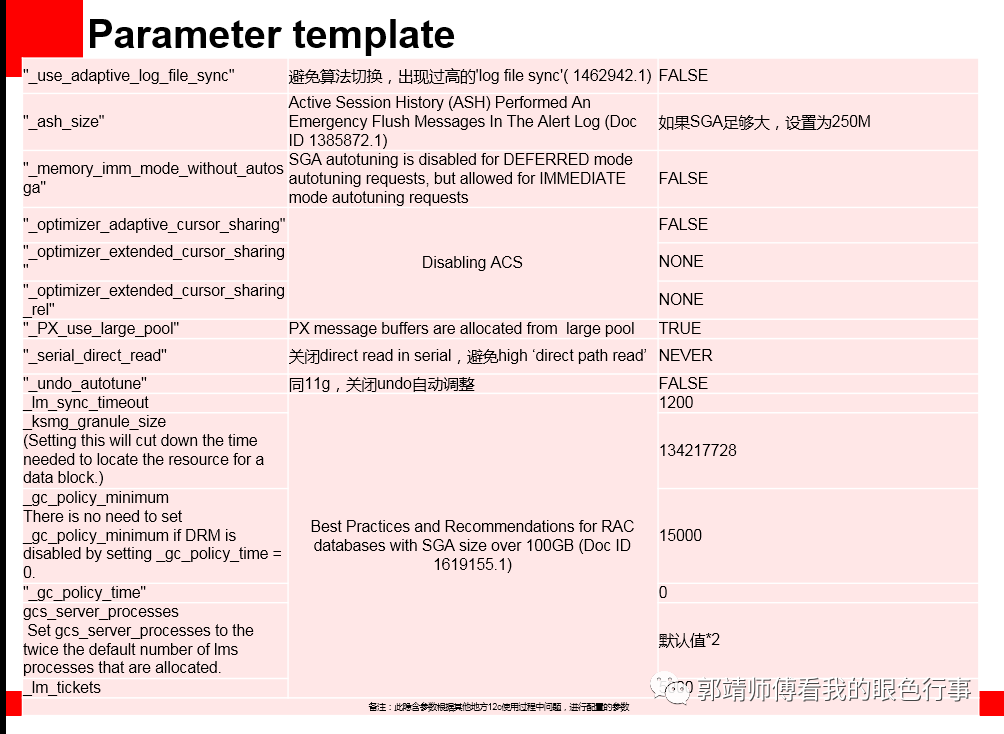
参数模板







权限问题:
•ASM PERMISSION DENIED
./setasmgidwrap o=/u01/app/oracle/product/12.2.0/db_1/bin/oracle
打补丁时,报权限错误,用上面命令修改oracle文件权限
• Directory PERMISSION CHANGED
oracle/app/grid/product/11.2.0/grid_1/crs/install/rootcrs.pl –init
整个目录权限被 修改,先执行这个命令,他会恢复启动grid软件的最新小权限,然后
使用MOS提供的PERMISSION.PL工具提取正常节点的权限
迁移前,先做SPA,到新库重演。
