





本文将介绍一个主流而简洁的对比学习(ContrastiveLearning)框架,对于对比学习的基本组件噪声对比估计(Noise Contrastive Estimation)和余弦相似度作出一些简要分析,然后分享一个基于此框架的自然语言处理中的应用。
什么是对比学习?
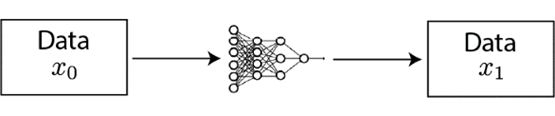
通常来说,自监督学习可以大致被分为两类:生成式和对比式。生成式方法以自编码器为代表,在视觉中关注像素级别的重建。BERT采用的就是生成式方法,通过掩盖预测任务学习自然语言的特征。但在视觉领域,由于像素级别重建任务难度较高,生成式方法的效果不够理想。对比式方法则是通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。相比起生成式方法需要对像素细节进行重构来学习到样本特征,对比式方法只需要在特征空间上学习到区分性,因此不会过分关注像素细节,而能够关注抽象的语义信息,并且相比于像素级别的重构,优化也变得更加简单。
具体而言,对比学习的目标是学习编码器f,使得




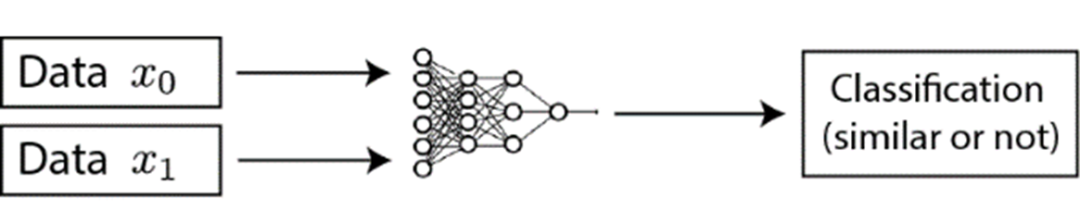
首先,如何通过无标注数据构造正负样本呢?本篇文章提出的解决方案是,利用数据增强的手段,构造正样本,并简单地将训练过程中同一批(batch)的其余数据视为负样本。其中的数据增强操作,作者采用了随机裁剪(random cropping)、随机色彩扭曲(random color distortion)和随机高斯模糊(random Gaussian blur)。
其次,训练框架是怎么构建的呢?此处作者采用了常见的双塔结构(branch)进行相似度计算,如图所示。对于采样得到的图片数据,先用编码器f进行编码,再用2层神经感知机g进行投影,最后进行相似度的计算。
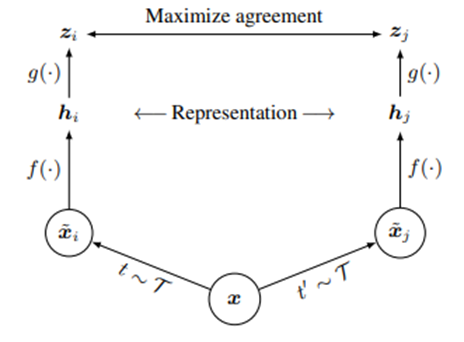
具体而言,对于批大小为N的原始图片数据,对于每张图片,从这些数据增强操作中采样两种对原始图片进行变换,得到2N个数据,其中,由同一张原始图片变换得到的作为正样本,不同图片变换得到的作为负样本。在经过上述编码、投影过程后,使用InfoNCE损失函数计算损失并优化:
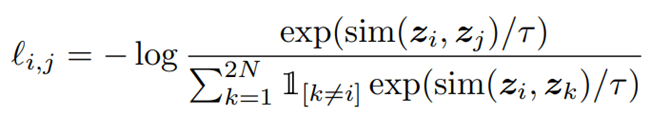
其中,sim(·, ·)采用余弦相似度作为衡量指标。
这篇文章的结论有几个值得注意的观点。第一是,较大的批大小能够促进训练在更短的步数和周期数内收敛(批大小从256到8192不等,在TPU集群上进行训练)。这是由于,较大的批大小提供了更多的负样本对,并且能促进模型收敛。第二是,不同于原始的批正则化(batch normalization)在各自计算结点上单独进行,但由于正样本的稀疏性,往往一个计算结点上不会包含太多正样本,因此作者采用了全局正则化(global normalization)的技巧,统一计算均值和方差以正则化。同时,对于视觉任务,作者发现,1)选取合适的数据增强手段的组合对表现影响很大;2)非线性投影g的引入使得表征质量有所提高。
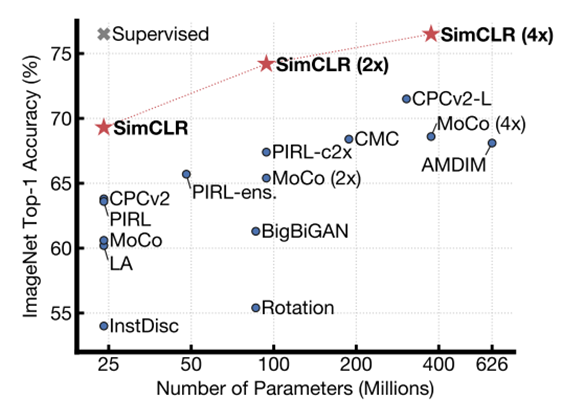
实验方面,作者采用ImageNet作为实验的数据集。作者在两种设置下对于表征学习的效果进行了验证。第一种叫做线性验证(linear evaluation),保持编码器参数固定不变,训练线性分类器并检查分类效果。可以看到,SimCLR方法取得了比其余自监督学习方法更好的效果,并在参数数量较大的情况下(4x)可以比肩监督学习的基线模型;
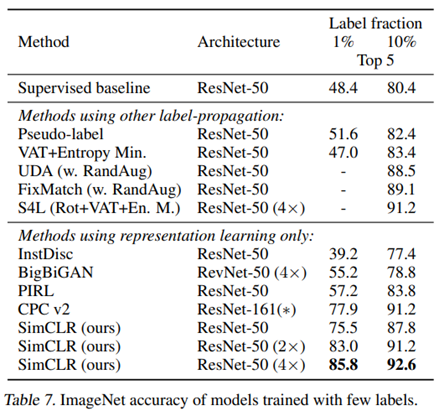
第二种叫做半监督学习(semi-supervised learning),即在对比学习后,使用少量数据进行精调(finetune)进一步优化模型。可以看出,在这种类似于小样本学习(few-shot)的场景下,模型取得了不错的泛化效果,作者在进一步的实验中也证明,即使使用全量样本进行精调,预先进行的对比学习也能使模型效果有约2%的提升。

在这部分中,我们将介绍上述两篇论文中的一些理论分析。
在之前的框架中,使用了余弦相似度作为度量函数。即,在点积运算的基础上,对计算结果进行归一化。事实上,这步归一化可以看作将表征向量映射到一个单位超球体上的过程,这种做法可以使得训练过程更稳定,防止表征出现消失或爆炸的情况,同时超球体也使得应用表征的线性分类器分类更为容易。
在表征学习中,我们希望学到的表征具有什么样的性质呢?作者提出了两种性质:对齐性(alignment)和一致性(uniformity)。前者指的是,具有相似特征或语义的数据,应该有相似的表征;后者指的是,从整体数据分布上看,编码得到的表征应该均匀的分布在超球体上,而不是聚集在某个特定的狭窄区域。这两个性质很符合直觉。对于具体评价的数学计算公式,可以参照第一篇论文。
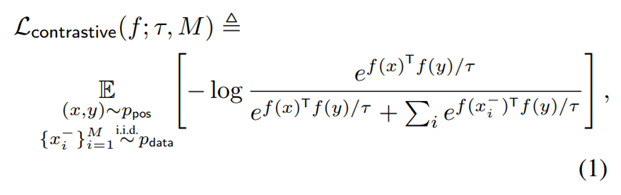
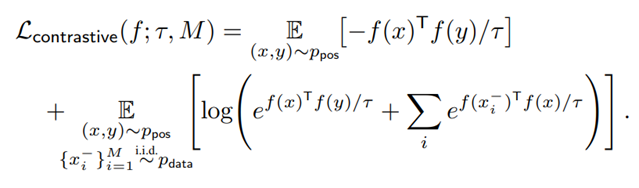
那么,InfoNCE损失函数有什么作用呢?简化原公式可以得到上述形式。可以看出,优化损失函数,对于第一项,鼓励正样本在单位超球面上的距离越近越好,对于第二项,鼓励任意两对负例,在单位超球面上,两两距离越远越好,这种实例两两之间的推力,会尽量让特征均匀得分布在单位超球面上,保留了尽可能多的有用信息。所以,InfoNCE损失函数相当于同时从这两方面入手进行表征学习。
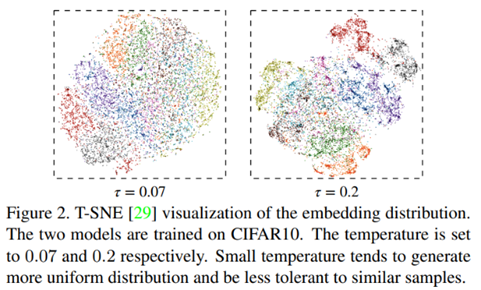
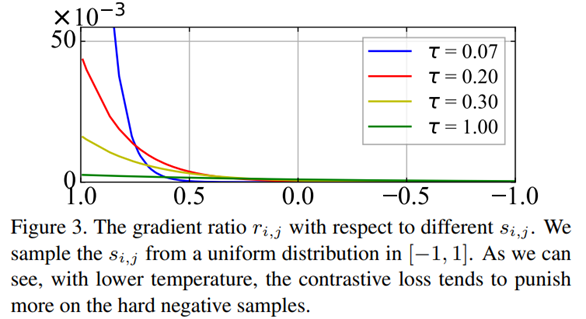
公式中的τ被称作温度超参(temperature hyperparameter),它负责保持对齐性和一致性之间的平衡。温度参数会将模型参数更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与x距离越近,则分配到的惩罚越多。所谓惩罚,就是在模型优化过程中,将这些负例从 x身边推开,是一种斥力。也就是说,距离 x越近的负例,温度超参会赋予更多的排斥力,将它从 x推远。而如果温度超参数设置得越小,则InfoNCE分配惩罚项的范围越窄,更聚焦在距离比较近的较小范围内的负例里。同时,这些被覆盖到的负例,因为数量减少了,所以,每个负例,会承担更大的斥力。极端情况下,假设温度系数趋近于0,那么InfoNCE基本退化为聚焦在距离 最近的一到两个最难的实例。

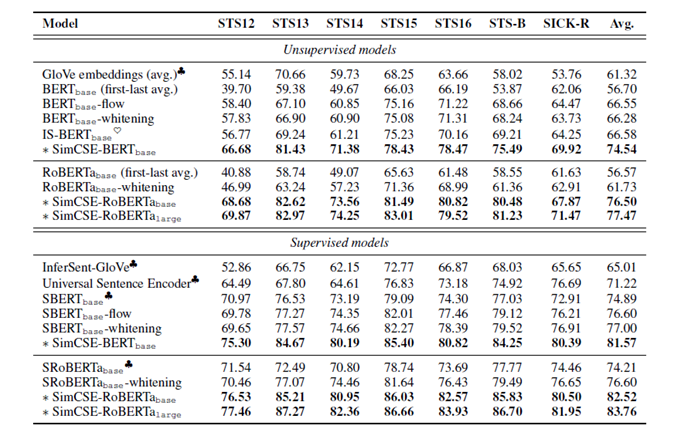
从视觉领域对比学习的成功可以看出,对比学习在表征学习,尤其是无监督的环境下,能起到不错的效果。一个自然的想法是,在NLP的句表示学习任务中,加以应用。在本文中,作者在监督学习和无监督学习的环境下都进行了尝试。由于应用的框架与SimCLR类似,我们在此就不再做额外介绍,而主要讨论样本构建问题。
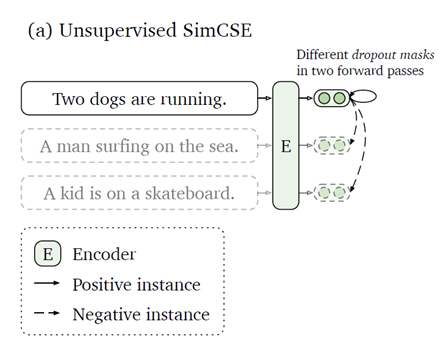
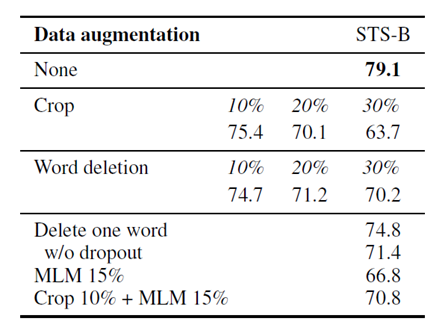
不同于图片像素的近似连续性,自然语言往往以离散的方式呈现。在对抗学习领域中,对于数据增强操作,也做过多种尝试,诸如单词替换、换序、随机删减等方式。在无监督学习的设置下,本文中作者创新地将dropout操作视为一种“最小的”数据增强的方法。对于同一条语句,在训练中使用两次不同的dropout mask,即视为一组互为正例的样本对。在负样本构建中,与SimCLR一致,使用同一批内的其余数据即可。有意思的是,消融实验表明,只用dropout作为数据增强手段反而取得了最好的效果,引入其余手段反而会损害模型的表现。
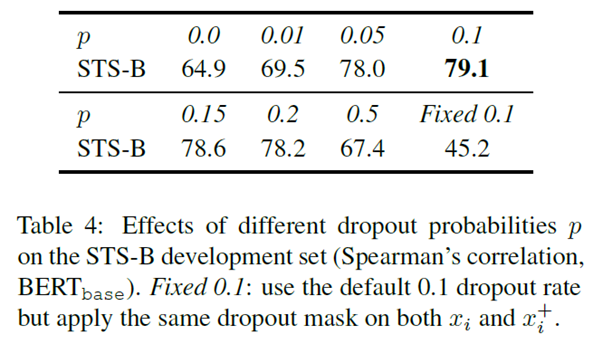
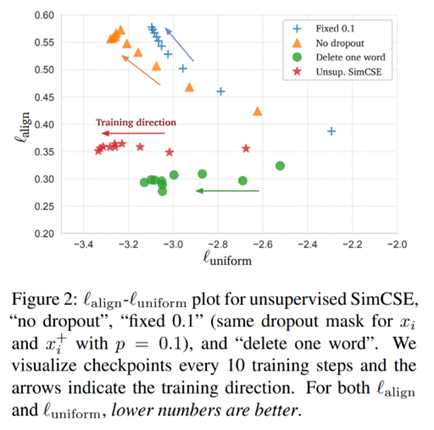
进一步的问题是,dropout真的发挥了数据增强的作用,还是这种表现是一种偶然现象呢?从表4可以看出,当对一对正样本使用固定的dropout mask时,模型的表现出现了显著的下降,从79.1降至45.2。而从图2中可以看出,随着训练进行,dropout策略在表征的一致性加强的同时,维持了良好的对齐性,而在没有使用dropout策略的实验中,对齐性显著随训练进行而降低。这在一定程度上解释了dropout策略的作用,证实了作者的猜想。
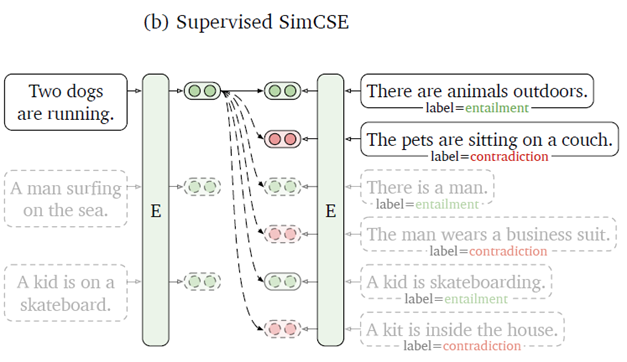
除了无监督的设置以外,作者还尝试了利用有标注数据集中的监督信号,进一步强化表征学习效果。其中,自然语言推理(natural language inference)数据集展示了良好的效果。NLI数据集由句子对构成,每对之间的关系包括体现(entailment)、中性(neutral)以及矛盾(contradiction)。NLI数据集对于模型语言理解有着强化作用,同时数据之间的语法重叠较无标注数据更少。作者尝试将体现关系的样本作为额外的正样本,矛盾关系的样本作为负样本,进行有监督的对比学习,取得了良好的效果。
结语
但现有研究仍有不尽完善之处。其一是,在无监督学习设置下停止策略的选取。由于优化目标InfoNCE的性质,理论上优化过程可以一直进行下去。但这显然会导致过拟合问题的出现。现有工作多依赖模型在验证集上的表现,选取一定的优化步数,但这显然不是彻底的“无监督学习”了。其二是,对比学习的效果,高度依赖于正负样本的构造。如何构造正负样本更类似于一种经验性的工作,缺乏普适的构造标准。这些问题还有待之后的工作进行进一步的探索。
 相 关 链 接
相 关 链 接

