




慢日志主要用来记录在数据库中执行时间超过指定时间的SQL语句。通过慢查询日志,可以查找出哪些语句的执行效率低,以便进行优化。本文简要介绍了MySQL和GoldenDB中的慢日志结构,通过横向对比加深对分布式数据库慢日志结构的理解。
1、MySQL中的慢日志
1.1 MySQL慢日志介绍

一般情况下,我们只需开启慢日志记录,配置下阈值时间,其余参数可按默认配置。在实际生产环境中可以根据需要进行调整,通常设置为long_query_time为100ms。
1.2 慢日志分析工具
1.2.1 开启慢查询
mysql> show variables like 'slow_query%';+---------------------+-----------------------------------------------+| Variable_name | Value |+---------------------+-----------------------------------------------+| slow_query_log | OFF || slow_query_log_file | usr/local/mysql/data/tango-GDB-DB01-slow.log |+---------------------+-----------------------------------------------+2 rows in set (0.11 sec)mysql> show variables like 'long%';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+1 row in set (0.00 sec)#开启slow query并设置阈值为100msmysql> set global slow_query_log=1;Query OK, 0 rows affected (0.10 sec)mysql> set long_query_time=0.1;Query OK, 0 rows affected (0.00 sec)mysql> show variables like 'slow_query%';+---------------------+-----------------------------------------------+| Variable_name | Value |+---------------------+-----------------------------------------------+| slow_query_log | ON || slow_query_log_file | usr/local/mysql/data/tango-GDB-DB01-slow.log |+---------------------+-----------------------------------------------+2 rows in set (0.00 sec)mysql> show variables like 'long%';+-----------------+----------+| Variable_name | Value |+-----------------+----------+| long_query_time | 0.100000 |+-----------------+----------+1 row in set (0.00 sec)
mysql> select count(1) from sbtest.sbtest1 where id between 100 and 10000 ;+----------+| count(1) |+----------+| 9901 |+----------+1 row in set (0.55 sec)[root@tango-GDB-DB01 data]# less tango-GDB-DB01-slow.log # Time: 2021-10-17T00:26:03.079183Z# User@Host: root[root] @ localhost [] Id: 8# Query_time: 0.546503 Lock_time: 0.386796 Rows_sent: 1 Rows_examined: 9901SET timestamp=1634430362;select count(1) from sbtest.sbtest1 where id between 100 and 10000;
mysql> show global status like '%Slow_queries%';+---------------+-------+| Variable_name | Value |+---------------+-------+| Slow_queries | 3 |+---------------+-------+1 row in set (0.49 sec)
1.2.2 日志分析工具mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow。使用很简单,可以跟-h来查看具体的用法
[root@tango-GDB-DB01 data]# ../bin/mysqldumpslow tango-GDB-DB01-slow.logReading mysql slow query log from tango-GDB-DB01-slow.logCount: 1 Time=0.16s (0s) Lock=0.39s (0s) Rows=1.0 (1), root[root]@localhost select count(N) from sbtest.sbtest1 where id between N and N
出现次数(Count),
执行最长时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
1.2.3 开源工具pt-query-digest
pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
1)安装pt-query-digest
# yum install perl-DBI# yum install perl-DBD-MySQL# yum install perl-Time-HiRes# yum install perl-IO-Socket-SSL# yum -y install perl-Digest-MD5cd usr/local/srcwget percona.com/get/percona-toolkit.tar.gztar zxf percona-toolkit.tar.gzcd percona-toolkit-3.3.1perl Makefile.PL PREFIX=/usr/local/percona-toolkitmake && make install
2)pt-query-digest语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析--limit 限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。--host mysql服务器地址--user mysql用户名--password mysql用户密码--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。--until 截止时间,配合—since可以分析一段时间内的慢查询。
3)分析pt-query-digest输出结果
第一部分:总体统计结果
# 该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小# 200ms user time, 130ms system time, 25.73M rss, 220.28M vsz# 工具执行时间# Current date: Sat Oct 24 10:30:19 2021# 运行分析工具的主机名# Hostname: tango-GDB-DB01# 被分析的文件名# Files: usr/local/mysql/data/tango-GDB-DB01-slow.log# 语句总数量,唯一的语句数量,QPS,并发数# Overall: 4 total, 4 unique, 0.01 QPS, 0.11x concurrency________________# 日志记录的时间范围# Time range: 2021-10-17T00:24:42 to 2021-10-17T00:29:33# 属性 总计 最小 最大 平均 95% 标准 中等# Attribute total min max avg 95% stddev median# ============ ======= ======= ======= ======= ======= ======= =======# 语句执行时间# Exec time 33s 398ms 32s 8s 32s 14s 16s# 锁占用时间# Lock time 390ms 147us 387ms 97ms 374ms 162ms 188ms# 发送到客户端的行数# Rows sent 4 1 1 1 1 0 1# select语句扫描行数# Rows examine 9.67k 0 9.67k 2.42k 9.33k 4.04k 4.67k# 查询的字符数# Query size 208 28 74 52 72.65 18.73 69.27
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
第二部分:查询分组统计结果
# Profile# Rank Query ID Response time Calls R/Call V/M# ==== =================================== ============= ===== ======= ===# 1 0x028E79DCDB99AC4C8AE06173AA02BA16 31.9112 95.7% 1 31.9112 0.00 SELECT sbtest?# MISC 0xMISC 1.4378 4.3% 3 0.4793 0.0 <3 ITEMS>
Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
第三部分:每一种查询的详细统计结果
# Query 1: 0 QPS, 0x concurrency, ID 0x028E79DCDB99AC4C8AE06173AA02BA16 at byte 382# This item is included in the report because it matches --limit.# Scores: V/M = 0.00# Time range: all events occurred at 2021-10-17T00:24:42# Attribute pct total min max avg 95% stddev median# ============ === ======= ======= ======= ======= ======= ======= =======# Count 25 1# Exec time 95 32s 32s 32s 32s 32s 0 32s# Lock time 0 2ms 2ms 2ms 2ms 2ms 0 2ms# Rows sent 25 1 1 1 1 1 0 1# Rows examine 0 0 0 0 0 0 0 0# Query size 13 28 28 28 28 28 0 28# String:# Hosts localhost# Users root# Query_time distribution# 1us# 10us# 100us# 1ms# 10ms# 100ms# 1s# 10s+ ################################################################# Tables# SHOW TABLE STATUS LIKE 'sbtest1'\G# SHOW CREATE TABLE `sbtest1`\G# EXPLAIN /*!50100 PARTITIONS*/select count(1) from sbtest1\G
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables:查询中涉及到的表
Explain:SQL语句
2、GoldenDB中的慢日志
2.1 DBProxy慢查询日志
下面是计算节点慢日志示例:
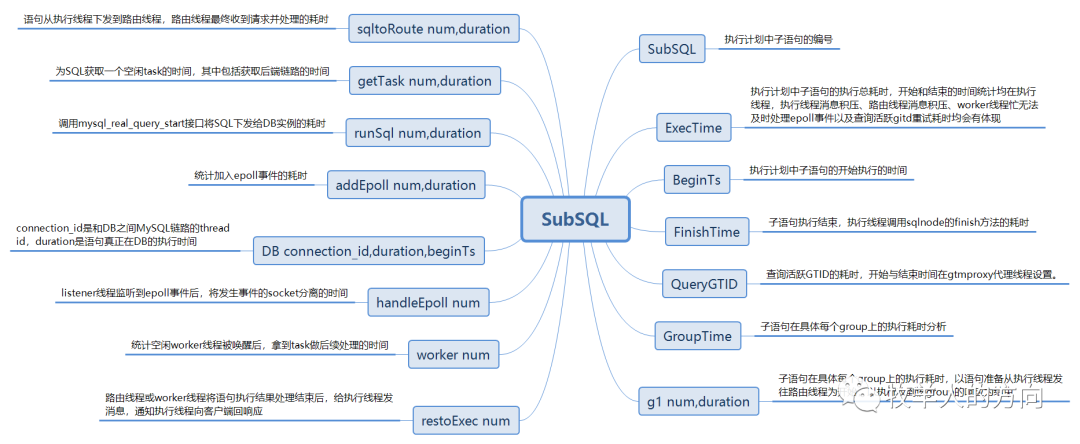
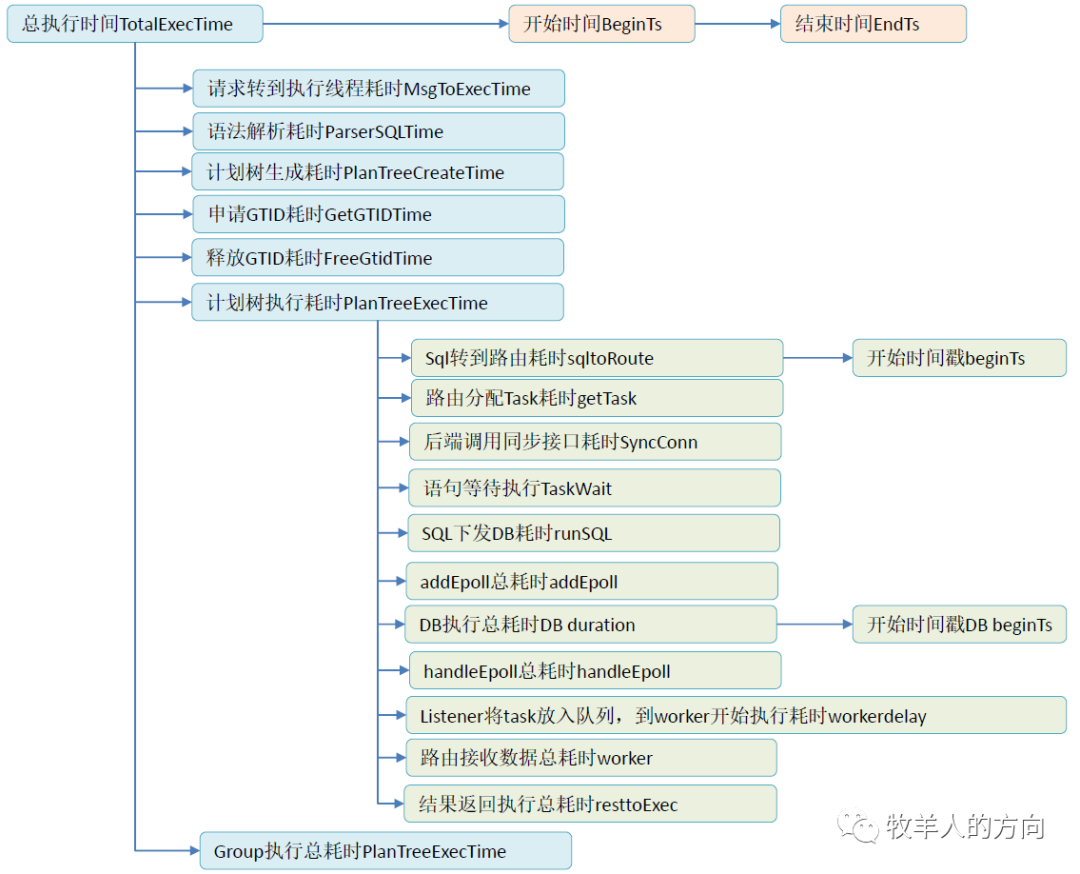
[2020-03-18 04:36:03:370]|DEBUG||311-1-4091-1584477361372642|LRT1133282889123678368|49417|49900|dbp_proxytool.cc:3723||#EXECUTE:Port[7788]Session[4091]TransSerial[LRT1133282889123678368]LinkIP[10.46.182.58]LinkPort[16570]UserName[dbproxy]ProxyName[proxy1]ClusterName[cluster1]TotalExecTime[2003025us]BeginTs[04:36:01:375315]EndTs[04:36:03:378340]SQL[select * from test.user_card_info_hash where card_number=527244 for update]MsgToExecTime[6us]ParserSQLTime[26us]PlanTreeCreateTime[65us]GetGTIDTime[0us]FreeGtidTime[0us]PlanTreeExecTime[2002865us]SubSQL[1]:TaskID[1]ExecTime[2002860us]BeginTs[04:36:01:375455]FinishTime[2us]QueryGTID[303us]GroupTime[g1 num:1, duration:2002497us sqltoRoute num:1,duration:130us getTask num:1,duration:3us runSql num:1,duration:9us addEpoll num:1,duration:2us DB connection_id:47546,duration:2002276us,beginTs:04:36:01:375948 handleEpoll num:1,duration:0us worker num:1,duration:17us restoExec num:1,duration:48us]SQL[SELECT `test`.`user_card_info_hash`.`card_number`,`test`.`user_card_info_hash`.`account_id`,`test`.`user_card_info_hash`.`card_balance`,`test`.`user_card_info_hash`.`updatebalance_time`,`test`.`user_card_info_hash`.`makecard_bank_id`,`test`.`user_card_info_hash`.`makecard_time`,`test`.`user_card_info_hash`.`gtid` as `gtid1` FROM `test`.`user_card_info_hash` where (`card_number` = 527244) FOR UPDATE]
DBProxy中字段结构

DBProxy中SubSQL字段结构
DBProxy中慢日志时间关系
2.2 DN数据节点慢查询日志
以下是DN数据节点的慢日志示例:
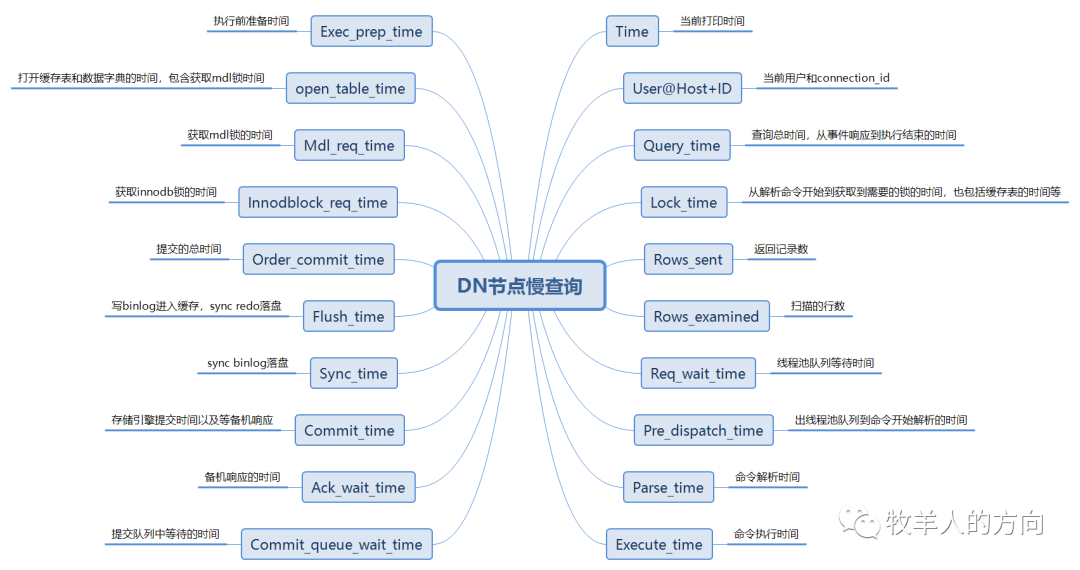
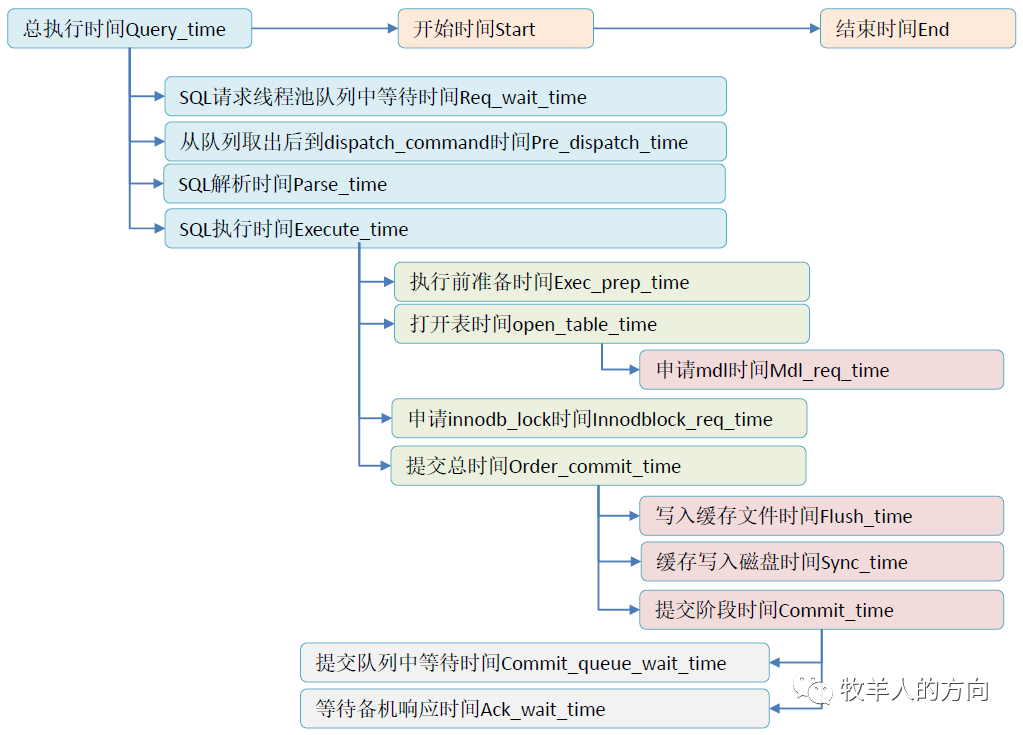
# Time: 2020-03-18T13:01:40.860959+08:00# User@Host: root[root] @ [10.46.182.53] Id: 90354# Query_time: 3.485023 Lock_time: 0.000719 Rows_sent: 0 Rows_examined: 333008# Req_wait_time: 0.000000 Pre_dispatch_time: 0.000011 Parse_time: 0.000025 Execute_time: 3.484998# Exec_prep_time: 0.000001 Open_table_time: 0.000669 Mdl_req_time: 0.000002 Innodblock_req_time: 0.000000
# Order_commit_time: 0.280414 Flush_time: 0.027070 Sync_time: 0.011554 Commit_time: 0.241790 Ack_wait_time: 0.241554 Commit_queue_wait_time: 0.000015
SET timestamp=1584507700;
insert into user_card_info_check1 select * from user_card_info_check;
DN慢日志结构
DN数据节点慢日志时间关系
2.3 慢日志分析
1)Time: 当前打印的时间
该时间是当前打印的时间,使用该时间减去Query_time,可近似得到收到该sql的时间;
2)Id: connection_id
该id就是mysql的thread_id,也就是链接id,可以通过该id在锁等待日志,binlog二进制日志,系统表如innodb_trx等中,根据该id查找相关时刻的信息。如可以根据该id在锁等待日志innodb_lock_wait.log日志中搜索当前时刻同一个id的锁等待日志,根据锁等待日志再做具体分析;
3)Rows_sent:
实际业务就是需要扫描这么多记录,那么无法优化;
实际业务可能不需要扫描过多记录,那么可以通过查询条件优化或者增加索引等,进行优化,避免过多的全表扫描;
4)Req_wait_time:
线程池配置thread_pool_size*thread_pool_oversubscribe过小,导致大量并发来不及处理。该问题需要及时调整线程池大小;
线程池配置能够满足99%以上的业务场景,但是某一批异常的业务中每一个sql执行耗时非常长,导致线程池资源被长时间占用,来不及处理新的sql。该问题可能是业务上的sql很慢,具体可以分析该时刻的其余慢sql
5)open_table_time:
打开缓存表和数据字典的时间,包含获取mdl锁时间。该阶段时间慢,可能在Mdl_req_time没有打印出长时间,但是在这个open_table阶段打印出了长时间。具体原因可能是mdl锁时间消耗,也可能是打开缓存表的时间消耗。目前遇到过的open_table_time阶段慢的问题,主要是由于truncate table 和 copy table引起的,可以通过一键诊断或者慢查询日志分析该时刻是否同步有以上2个操作;
6)Mdl_req_time: 获取mdl锁的时间
这个锁很明确就是mdl锁产生的时间间隔。
7)Innodblock_req_time: 获取innodb锁的时间
这个阶段慢,主要就是innodb的行锁产生了所等待冲突,可以进一步根据锁等待日志innodb_lock_wait.log排查请求事务和阻塞事务。如果请求事务和阻塞事务都有gtm_gtid,那么可以根据gtm_gtid在相应的binlog中找到DML记录,进而对比请求的sql和阻塞的sql是否真的产生的行锁冲突,冲突在什么哪一个主键记录、或者唯一索引记录上。当然如果没有gtm_gtid,也可以根据事务的thd_id在binlog中查找,只不过要对时间点进行严格的校验,确保是同一个事务。
8)Flush_time: 写binlog进入缓存,sync redo落盘
flush阶段慢的原因,基本上就是磁盘的IO较高导致的,可以查看该时刻是否IO较高,是否存在copy table命令等。
9)Sync_time: sync binlog落盘
该阶段慢,主要原因是sync binlog落盘较慢,一种可能性是sync的binlog很大,导致sync时间过长,另一个可能性是binlog所在磁盘的IO产生了毛刺,导致sync动作较慢。
10)Commit_time:
存储引擎提交时间以及等备机响应 这阶段时间慢,很大可能是等待备机响应慢,具体原因可能有:大的binlog事务,网络存在抖动;等待备机响应慢,其Ack_wait_time时间可能较大,也可能不大。
2.4 常见慢查询
2.4.1 大事务引起的慢查询
通过proxy可以查看到链路报错的thread_id号,该thread_id号就是慢查询第二行的Id:号,再根据thread_id找到出问题对应的慢查询日志;
查看慢查询日志,如果Commit_time时间较长,则继续查看同一个时间前后是否存在Ack_wait_time时间较长的慢查询,如果存在,则一定是主机等待备机时间较长导致的;
继续查看A时刻binlog文件的大小,查看A时刻前后binlog文件有没有超过200M大小的文件,如果有,则一定是大事务导致的慢查询;
最后解析binlog文件,根据每一个事务的pos信息,查看该binlog中的大事务binlog多大,是什么样类型的事务,此处有可能是insert/update/delete事务,再确认操作的库表名,联系业务侧解决大事务的问题。
2.4.2 select查询记录过大引起的慢查询
扫描记录过大的主要原因有2个,一个是无索引或者索引失效,导致的全表扫描等;
另一个是查询出的结果集行数本身就很大,确实需要扫描很多行。
2.4.3 等待备机响应过长(非大事务)引起的慢查询
通过proxy可以查看到链路报错的thread_id号,该thread_id号就是慢查询第二行的Id:号,再根据thread_id找到出问题对应的慢查询日志;
查看慢查询日志,如果Commit_time时间较长,则继续查看同一个时间前后是否存在Ack_wait_time时间较长的慢查询,如果存在,则一定是主机等待备机时间较长导致的;
继续查看A时刻binlog文件的大小,查看A时刻前后binlog文件有没有超过200M大小的文件,如果没有,则一定不是大事务导致的慢查询;
继续查看mysqld1.log错误日志,查看A时刻是否有semi_sync插件超时或者高低水位切换的日志,如果有,则可能存在备机异常,导致等待备机响应时间较长。
如果mysqld1.log错误日志在A时刻没有异常日志,则可能是网络丢包导致的,继续查看网络包是否异常。
2.4.4 Open table时间过长引起的慢查询
慢查询日志中,如果发现Open_table_time时间过长,达到总时间的50%以上,则此处很有可能是table_cache的移除和重新打开有关系,一般遇到该问题时,有可能同时存在相关的DDL语句,如truncate table 或者copy table语句,这些语句都会导致mysql内部table_cache的移除。
2.4.5 线程池积压引起的慢查询
发现如果Req_wait_time时间较长,达到总时间的50%以上,则有可能是DB线程池消息积压引起的慢查询;
继续查看DB节点下的tool/db/threadpool.log监控记录,查看A时刻前后线程池的低优先级队列(Low_queue_events)是否存在积压,等待时间(Wait_time)是否较长;
确认如果是线程池积压,则查看DB上的线程池配置,如果是配置不足,则可以动态修改调整大小,确保生效;
确认如果非线程池配置问题,则查看A时刻是否存在大量时间较长的慢查询日志,比如存在大量的select大结果集的查询语句,则可能是由于大量的select查询语句占用了较多的线程池资源,导致线程池存在积压。此时可以捞出执行较长的sql语句交由相应的业务进行分析,一般可能都是由于没有索引或者索引失效引起的问题。
2.4.6 行锁等待引起的慢查询
慢查询日志中,如果是行锁等待时间过长的,则Innodblock_req_time值比较大,占比超过50%以上;
同时需要查看锁等待日志,锁等待日志在中,可以查看问题时刻,在锁等待日志中有没有出现相应thread_id的锁等待记录。
锁等待记录中req_trx_id表示请求锁事务的thread_id,blk_trx_id表示阻塞锁事务的thread_id;
如果是锁等待引起的慢查询,则需要具体分析为何事务会长时间持有锁记录,可能是业务逻辑,也可能是IO原因导致的sql执行慢。
2.4.7 其它未知原因引起的慢查询
可能还存在部分不确定原因的慢查询现象,如果遇到未能解释的慢查询,可以联系现场DBA以及数据库负责人,在复现时刻采用pstack抓取堆栈,再交由DB开发分析具体原因。
以上是GoldenDB数据库慢日志分析有关内容,实际上原生innodb存储引擎的慢日志分析指标就比较粗放,像同步IO和异步IO等性能指标数据都没有涉及,这就给实际性能分析和优化过程带来一定的难度。
参考资料:
https://blog.csdn.net/enweitech/article/details/80239189
https://www.cnblogs.com/luyucheng/p/6265873.html
https://www.cnblogs.com/mysqljs/p/14779645.html
《GoldenDB分布式数据库性能分析》
