






导读
NLP(natural language processing, 自然语言处理) 是人工智能领域的一个重要方向。NLP是通过计算机来模拟、延伸及拓展人类语言能力的理论、技术及方法。NLP使得计算机具备人类的听、说、读、写能力,是人工智能技术实现认知能力关键核心之一。
目前,NLP技术已经广泛应用于智能搜索、机器翻译、对话系统、智能写作、深度问答等领域,为广大用户提供更智能的体验,满足用户对信息和服务的需求。同时,在互联网、金融、服务、医疗、教育等诸多行业发挥作用,提升产业智能化水平。
光大银行人工智能平台搭载了面向NLP的数据标注、模型训练及服务应用功能,帮助银行快速建设并使用NLP能力。本文从分析NLP的技术难点及研究热点为思考,基于人工智能平台优化『违禁识别』应用场景NLP模型为例,探索在人工智能平台实战NLP技术。
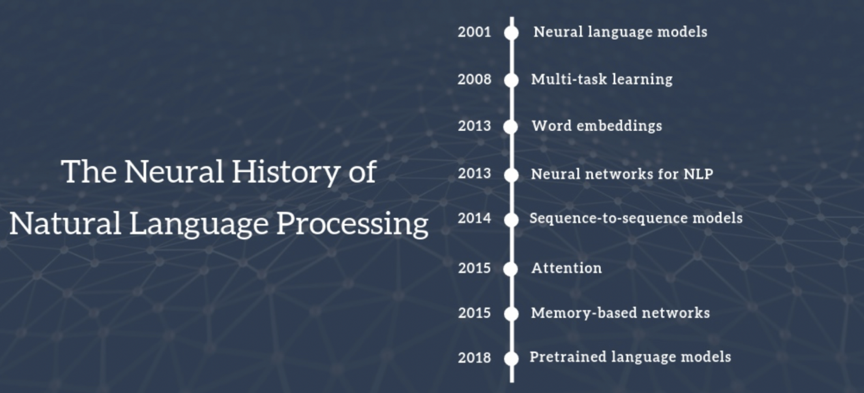

自然语言处理的技术难点
1
内容的有效界定
日常生活中句子间的词汇通常是不会孤立存在的,需要将话语中的所有词语进行相互关联才能够表达出相应的含义,一旦形成特定的句子,词语间就会形成相应的界定关系。如果缺少有效的界定,内容就会变得模棱两可,无法进行有效的理解。
2
消歧和模糊性
词语和句子在不同情况下的运用往往具备多个含义,很容易产生模糊的概念或者是不同的想法,例如高山流水这个词具备多重含义,既可以表示自然环境,也能表达两者间的关系,甚至是形容乐曲的美妙,所以自然语言处理需要根据前后的内容进行界定,从中消除歧义和模糊性,表达出真正的意义。
3
有瑕疵的或不规范的输入
例如语音处理时遇到外国口音或地方口音,或者在文本的处理中处理拼写,语法或者光学字符识别(OCR)的错误。
4
语言行为与计划
句子常常并不只是字面上的意思;例如,“你能把盐递过来吗”,一个好的回答应当是把盐递过去;在大多数上下文环境中,“能”将是糟糕的回答,虽说回答“不”或者“太远了我拿不到”也是可以接受的。再者,如果一门课程上一年没开设,对于提问“这门课程去年有多少学生没通过?”回答“去年没开这门课”要比回答“没人没通过”好。

自然语言处理的研究热点
1
预训练技术
预训练思想的本质是模型参数不再随机初始化,而是通过语言模型进行训练。目前NLP 各项任务的解决思路是预训练加微调。预训练对于NLP任务有着巨大的提升帮助,而预训练语言模型也越来越多,从最初的Word2vec、Glove到通用语言文本分类模型ULMFiT以及EMLo等。而当前最优秀的预训练语言模型是基于Transformer 模型构建。
当前影响最大的预训练语言模型是基于Transformer 的双向深度语言模型—BERT。BERT 是由多层双向Transformer 解码器构成,目前BERT 在机器翻译、文本分类、文本相似性、阅读理解等多个任务中都有优异的表现。BERT在英文语料中表现很优异,但在中文语料中效果一般。ERNIE则是以中文语料训练得出一种语言模型。ERNIE 是一种知识增强语义表示模型,其在语言推断、语义相似度、命名实体识别、文本分类等多个NLP 中文任务上都有优异表现。ERNIE 在处理中文语料时,通过对预测汉字进行建模,可以学习到更大语义单元的完整语义表示。

使用人工智能平台探索自然语
言处理
人工智能平台使用预训练模型 ERNIE提供智能文本产线建模能力,可面向命名实体识别、实体关系、实体属性、情感倾向分析、文本分类、文本多分类、短文本匹配、词性标注等常见NLP场景快速构建模型,并支持对模型的评估与测试,从而更快建立面向场景的AI能力。智能文本产线内置上述几类场景的ERNIE预训练模型,具备优秀的通用中文语料分析能力。在预训练模型基础上,可基于金融垂直领域的标注数据进行模型重训,以进一步提升模型在金融语料环境下的表现。智能文本产线具有快速和高级两种建模方式。在快速模式下,用户仅需配置数据集,即可进行快速建模。在高级模式下,除了可配置数据集之外,用户还可以查看模型DAG图,并对DAG图各节点的部分参数进行配置,以满足部分调参需求。
近年来,互联网技术蓬勃发展,信息传播形态越来越丰富,随之而来的是图片、视频、文本、语音中的违禁、涉政识别需求越来越复杂。类似于智能语音交互这种新型传播方式,也对内容审核技术也提出了新的要求。在语音交互场景下,偶尔出现的一些违禁、涉政及等敏感内容,因此需要一个智能鉴别模型来精准高效地识别与过滤违规信息。
基于人工智能平台提供的多媒体审核服务,正是具备音视频、图片、文本审核能力的AI审核预测服务,覆盖涉政、色情、暴恐、违禁、广告五大审核维度。能在文章评论、用户发帖、媒资库存档图文、长/短视频等场景下为业务方提供AI机审服务,提高业务方的内容审核效率,降低人工审核漏审风险,缩减人力成本。
由于多媒体审核服务提供的是通用场景的审核能力,缺少在行内场景下的历练,因此需要根据行内的数据进行优化增量训练。接下来,本文选择行内文本的『违禁涉政识别子任务优化』做为切入点。介绍如何使用光大银行人工智能平台智能文本功能,针对本次审核能力进行优化过程,来探索自然语言技术的应用。
1
违禁涉政信息识别的技术痛点
传统的违禁、涉政识别模型是基于敏感词进行字符串匹配过滤,该方案技术实现简单,但精确率、召回率相对较低,且模型效果极大依赖于敏感词库的完备性。通用的违禁、涉政识别模型对于识别效果有显著提升,部署起来也相对方便,但对于对话场景的一些典型Case却没有很好的识别效果。
为了解决上述技术痛点,基于智能文本产线进行模型重训,可在通用的违禁、涉政识别模型基础上,借助金融场景语料数据进行模型优化,从而打造一个更加精准的违禁、涉政定制化训练内容识别系统,进一步降低对话场景下敏感内容的错判率和漏判率。
2
问题定位及技术方案定制
1. 分析业务问题
违禁、涉政识别模型的输入特征为对话文本,输出结果为对话是否违禁或是否涉政,是典型的文本分类任务。因此,“判断是否违禁”与“判断是否涉政”可以各自训练一个模型。
2. 明确业务要求
针对不同场景的业务要求,项目过程中总结了以下几个分析业务需求的典型维度:

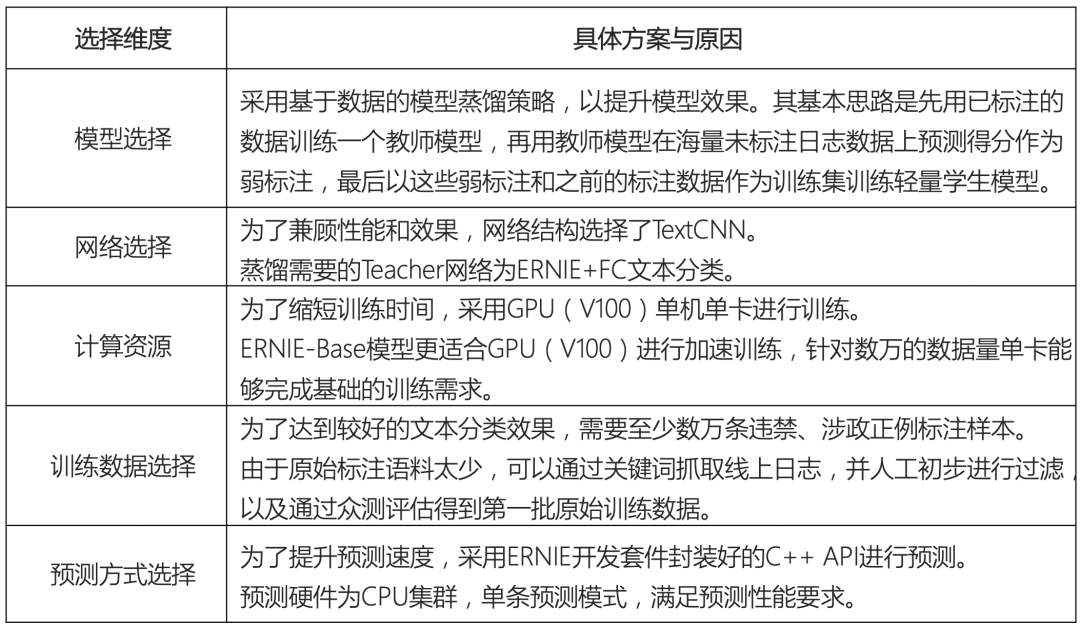
3. 选择技术方案
技术方案的选择对实际应用的效果影响非常大,需考虑维度也比较多。智能产线模块最大限度预设了各维度参数,模型开发人员仅需配置数据集、资源等少量信息,即可对已有模型进行重新训练。
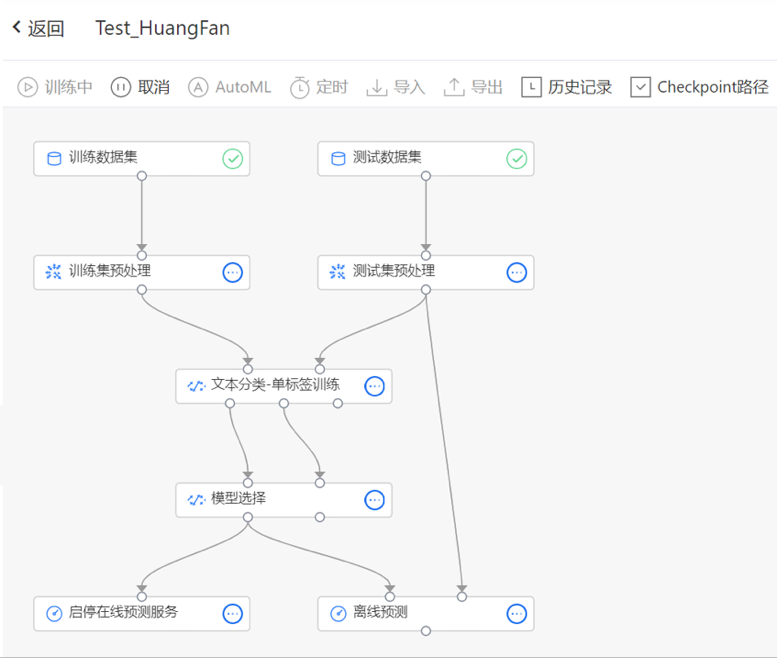
智能文本产线-文本分类高级模式示意图
3
模型效果
本次实验的模型策略替换后,违禁、涉政识别的效果得到了明显提升。在违禁识别上,同批测试数据精确率由原来的65.7%相对提升至84.5%,新模型对违禁语句漏召及正常对话过召的问题都有显著的改善。在涉政识别上,同批测试数据精确率由原来的90.6%相对提升至93.1%。正常对话的过召情况得到明显优化。
多媒体审核服务已经投入使用,本次审核预测服务版本,除提供文本审核、违禁审核,还提供暴恐审核、敏感人脸审核、商标LOGO识别、敏感标识识别、水印/二维码检测等智能审核能力。同时考虑到不同场景的审核规则不尽相同,系统还支持自定义敏感词审核、自定义人脸审核、自定义LOGO审核,全方位满足行内的内容审核需求。通过此智能服务,行内的图片、文本、音视频及直播流审核工作都能得到及时响应,相关业务的发展也会更加有保障。

结语
经过多年的数字化转型探索,为了更好的把AI技术元素注入业务全流程、全领域,光大银行通过建设人工智能平台,深化对人工智能多个领域技术如机器学习、自然语言处理等研究和使用,全面支持在思维与感知领域的智能化应用与业务创新。力争AI将融入到全行业务、管理的方方面面,打造辅助经营决策、辅助管理的大脑,最终AI建设将成为带动全行业持续创新的竞争力核心。

作者 | 张 彬
视觉 | 王朋玉
统筹 | 郑 洁



