




“ 分类算法的核心就是在于经验不断积累,不断迭代自己的规则,从而得到最好的答案。”

01
—
距离
我相信很多小白一听到距离应用在算法里面的时候第一反应是黑人三个问号,特别是评估两个不同样本之间的“相似性”,通常使用的方法就是计算两个样本之间的“距离”,而且距离还分带着奇奇怪怪的名字好几种。嘿嘿,还是那句别问我怎么知道的。
因为我们每个人在特定的文化里成长,慢慢有了每个人特定的认知分类图式,当有不符合我们认知无法归类的事物比如印度人直接用手抓饭吃,会让我们觉得不舒服,特别是任何全新事物。我们可以在大脑里腾个位置,尝试重复去理解,改变自己的认知分类图式,总归有个过程,这样你的认知范围就会越来越大。
换个角度想,距离本就可以分类,比如省份,也可以聚类,比如同乡会。再套到上面文绉绉官方定义,是不是觉得很有道理了。
一、两样本间:距离=相似度
二、数据科学中常见的9种距离度量方法:
1.欧氏距离(Euclidean)/2.余弦相似度(Cosine)/3.汉明距离(Hamming)
4.曼哈顿距离(Manhattan)/5.闵氏距离(Minkowski)/6.切比雪夫距离(Chebyshev)
7.雅卡尔指数(Jaccard)/8.半正矢(Haversine)/9.Sørensen-Dice 系数
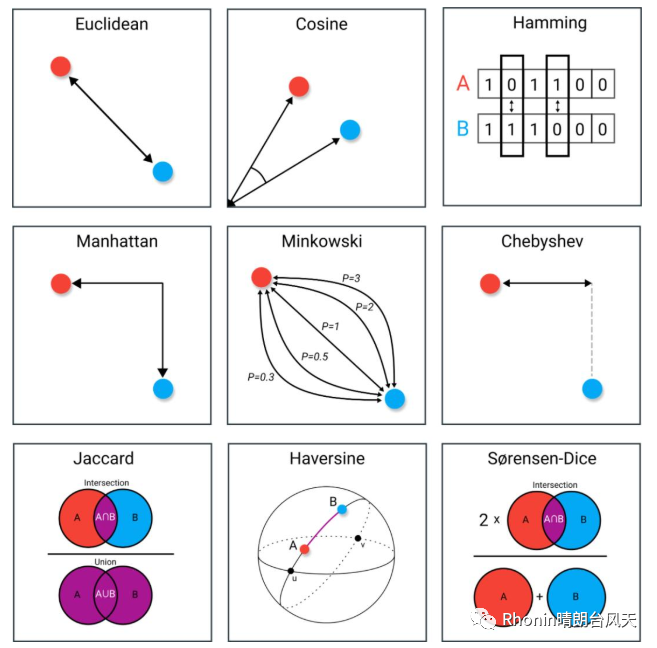
选自towardsdatascience
三、KNN最常用的距离
欧氏距离,两点距离(n维空间)。嗯,不用犹疑,就是我们最常用的距离公式如下:

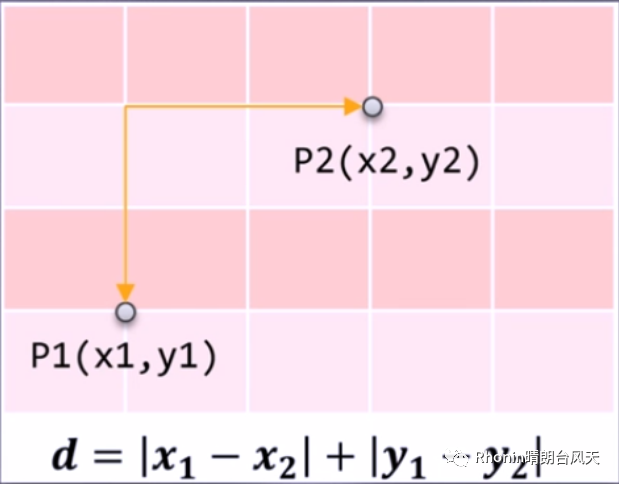
曼哈顿距离,两十字路口距离。
闵氏距离(闵可夫斯基距离),一组距离(不是一个距离)。P=1为曼哈顿,p=2为欧氏距离,p→∞切比雪夫。
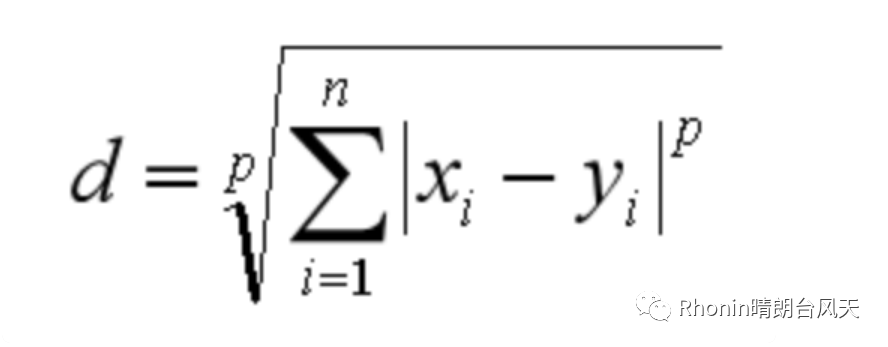
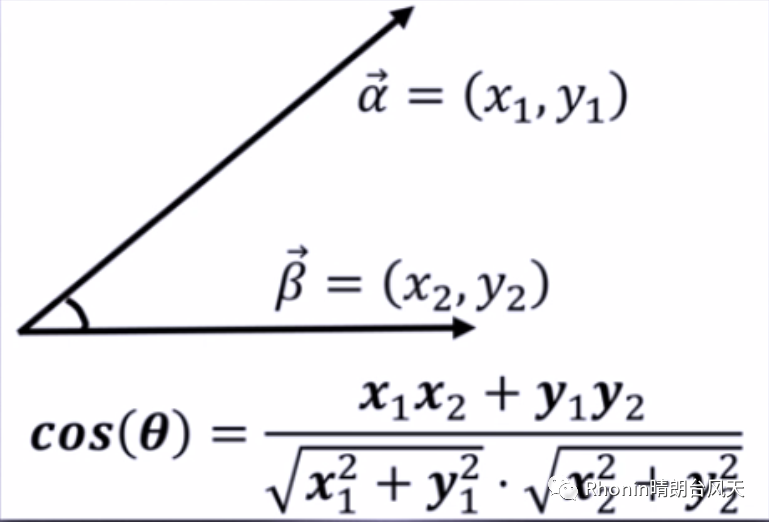
余弦相似度,两向量夹角的余弦值。兴趣相关性比较上,角度关系比距离的绝对值更重要,可用于衡量用户对内容兴趣的区分度。
02
—
KNN工作原理
1、KNN,K-Nearest Neighbor,K近邻。
2、官方定义:通过计算待分类数据点,与已有数据集中的所有数据点的距离。取距离最小的前K个点,根据“少数服从多数”的原则,将这个数据点划分为出现次数最多的那个类别。
3、白话版:K个邻居属于哪个分类多,待分类物体就属于哪类。
4、一句话版:近朱者赤,近墨者黑。
03
—
K值选择

温故而知新:大家还记得K 折交叉验证吗?
大家可以回顾下:算法-2 分类:决策树ID3、C4.5、CART
04
—
KD树和球树
1、KD tree
很多年前看过一篇吴军老师写的关于1-100最多问6次就能猜对的一个小游戏,当时还拿这个忽悠过客服小妹妹,结果她一脸神奇,觉得我很厉害,哈哈!用的就是中值定位。第一次问是比50大还是小,如果小,第二次问比25大还是小……一直到猜中,这个方法应用到计算机可以提升效率。我感觉KD树就是类似这个原理切分提升效率。
因为KNN要计算样本和所有点距离进行比较,这是非常大量的计算,为了提升KNN的搜索效率,这才有了KD树二叉树数据结构。KD树是对依次对K维坐标轴,每次选取剩下中方差最大的维度中中位数作为分割点不断二分构造的树,每一个节点是一个超矩形,在维数小于20时效率最高。
有个挺搞笑的图分享大家帮助理解KD树:有只4个纹身的暴躁兔,距离爱心最近的纹身是什么?
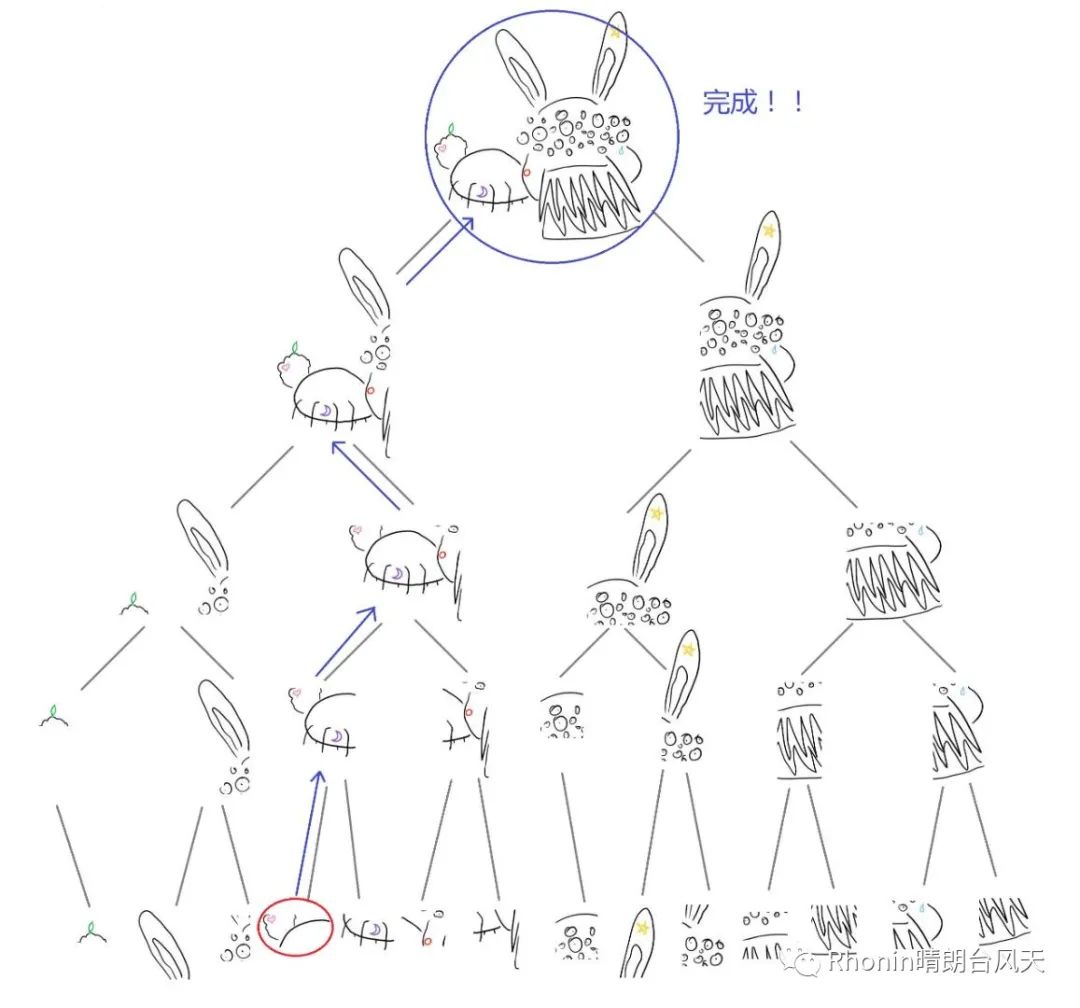
引用肖睿《kd 树算法之思路篇》
2、Ball tree
ball tree 是为了克服KD树高维失效而发明的,其构造过程是以质心C和半径r分割样本空间,每一个节点是一个超球体。KD树在搜索路径优化时使用的是两点之间的距离来判断,而球树使用的是两边之和与第三边大小来判断.
这是我认为比较好理解的说明,以下图为例搜索点q的半径为r内的最近邻,|q-x|<=r,
从根节点q开始从上至下递归遍历每个可能包含最终近邻的子空间,对于目标空间(q,r),所有被该超球体截断的子超球体内的所有子空间都将被遍历搜索。
由于子超球体a与b被q所截,而对于a与b内的子空间,d,h,f又被q所截,所以接下来就会在d,h,f内进行线性搜索。诸如c,e,g这些距离太远的子空间将被舍去。最后[x4,x7]就是最终得到的最近邻。

———知乎用户https://www.zhihu.com/question/30957691
05
—
KNN回归
先计算待测点到已知点的距离,选择距离最近的 K 个点,将这些点属性加权平均就是预测的属性值
06
—
Python sklearn 简介
1、引用,如果一个算法有 Classifier 类,都能找到相应的 Regressor 类
分类
from sklearn.neighbors import KNeighborsClassifier
回归
from sklearn.neighbors import KNeighborsRegressor
2、构建分类器
KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’, leaf_size=30)
n_neighbors:即 KNN 中的 K 值,代表的是邻居的数量。K 值如果比较小,会造成过拟合。如果 K 值比较大,无法将未知物体分类出来。一般我们使用默认值 5。
weights:是用来确定邻居的权重,有三种方式
a.weights=uniform,代表所有邻居的权重相同
b.weights=distance,代表权重是距离的倒数,即与距离成反比
c.自定义函数,你可以自定义不同距离所对应的权重。大部分情况下不需要自己定义函数。
algorithm:用来规定计算邻居的方法,它有四种方式
a.algorithm=auto,根据数据的情况自动选择适合的算法,默认情况选择 auto
b.algorithm=kd_tree
c.algorithm=ball_tree
d.algorithm=brute,也叫作暴力搜索,它和 KD 树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索。当训练集大的时候,效率很低。
leaf_size:代表构造 KD 树或球树时的叶子数,默认是 30,调整 leaf_size 会影响到树的构造和搜索速度。
3、训练
knn.fit(train_ss_x, train_y)
4、分类
predict_y = knn.predict(test_ss_x)
———文章有参考数据分析实战 陈旸

Python 系列-算法篇(起):算法-1 “高大上”的数据挖掘
Python 系列-基础篇(起):时隔一年重学Python
统计与概率系列(起):统计-1 统计与概率是门虐待学吗?
数据库与SQL(起):数据库与SQL-1 数据库系统
有需要思维导图的宝宝要等等啦,我写完算法篇后要重新整理会提供给大家下载哟~
