




1 新建项目
新建 idea Maven项目工程, 并创建子工程,pom.xml文件中引入spark依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>dintalk-classes</artifactId><groupId>cn.dintalk.bigdata</groupId><version>1.0.0</version></parent><modelVersion>4.0.0</modelVersion><artifactId>spark-core</artifactId><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.1.1</version></dependency></dependencies></project>
2 准备数据文件
3 代码编写
3.1 第一种写法
package cn.dintalk.bigdata.spark.core.wcimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark01_WordCount {def main(args: Array[String]): Unit = {// application -> spark 框架// 1. 建立 和 Spark框架的连接// JDBC 有 connection , Spark 有 SparkContextval sparkConf= new SparkConf().setMaster("local").setAppName("wordCount")val sc = new SparkContext(sparkConf)// 2. 执行业务操作// 2.1 读取文件, 获取一行一行的数据val lines: RDD[String] = sc.textFile("datas")// 2.2 将行数据进行切分,形成一个一个的单词val words: RDD[String] = lines.flatMap(_.split(" "))// 2.3 将数据按照单词进行分组,便于统计val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)// 2.4 对分组后的数据进行转换// (hello,hello,hello), (word,word) -> (hello,3),(word,2)val wordCount: RDD[(String, Int)] = wordGroup.map {case (word, list) => {(word, list.size)}}// 2.5 将转换结果采集到控制台输出val tuples: Array[(String, Int)] = wordCount.collect()tuples.foreach(println)// 3. 关闭连接sc.stop()}}
3.2 第二种写法
package cn.dintalk.bigdata.spark.core.wcimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark02_WordCount {def main(args: Array[String]): Unit = {// application -> spark 框架// 1. 建立 和 Spark框架的连接// JDBC 有 connection , Spark 有 SparkContextval sparkConf= new SparkConf().setMaster("local").setAppName("wordCount")val sc = new SparkContext(sparkConf)// 2. 执行业务操作// 2.1 读取文件, 获取一行一行的数据val lines: RDD[String] = sc.textFile("datas")// 2.2 将行数据进行切分,形成一个一个的单词val words: RDD[String] = lines.flatMap(_.split(" "))val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(t => t._1)val wordCount: RDD[(String, Int)] = wordGroup.map {case (word, list) => {list.reduce((t1, t2) => {(t1._1, t1._2 + t2._2)})}}// 2.5 将转换结果采集到控制台输出val tuples: Array[(String, Int)] = wordCount.collect()tuples.foreach(println)// 3. 关闭连接sc.stop()}}
3.3 第三种写法
package cn.dintalk.bigdata.spark.core.wcimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark03_WordCount {def main(args: Array[String]): Unit = {val sparkConf= new SparkConf().setMaster("local").setAppName("wordCount")val sc = new SparkContext(sparkConf)val lines: RDD[String] = sc.textFile("datas")val words: RDD[String] = lines.flatMap(_.split(" "))val wordToOne: RDD[(String, Int)] = words.map((_, 1))val wordCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)val tuples: Array[(String, Int)] = wordCount.collect()tuples.foreach(println)sc.stop()}}
3.4结果验证

4 log4j控制日志输出
4.1 resources目录下新建log4j.properties并 配置
log4j.rootLogger=ERROR, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppenderlog4j.appender.R.File=../log/agent.loglog4j.appender.R.MaxFileSize=10240KBlog4j.appender.R.MaxBackupIndex=1log4j.appender.R.layout=org.apache.log4j.PatternLayoutlog4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
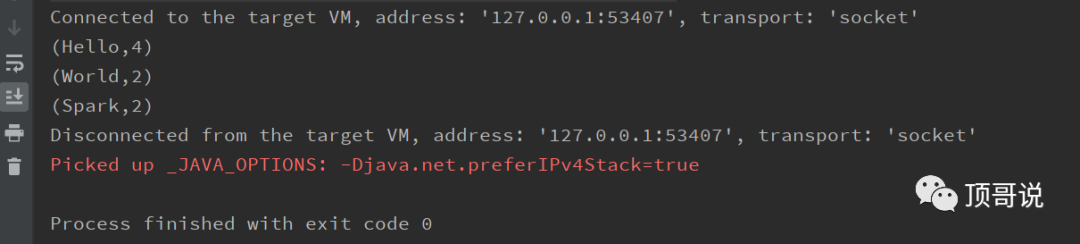
4.2 验证日志输出
无多余日志的输出
【推荐阅读】


文章转载自顶哥说,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
