




思考:设计一种数据结构,用来存放整数,要求提供3个接口(添加元素、获取最大值、删除最大值)。
使用数组/链表/BBST时,对应的时间复杂度:

有没有更优的数据结构?使用堆。
使用堆的时间复杂度:
获取最大值: O(1)删除最大值: O(logn)添加元素: O(logn)
一、堆
堆(Heap)也是一种树状的数据结构(注意:不要跟内存模型中的“堆空间”混淆)。
常见的堆实现:
二叉堆(Binary Heap,完全二叉堆) 多叉堆(D-heap、D-ary Heap) 索引堆(Index Heap) 二项堆(Binomial Heap) 斐波那契堆(Fibonacci Heap) 左倾堆(Leftist Heap,左式堆) 斜堆(Skew Heap)
1.1. 性质
堆的一个重要性质:任意节点的值总是≥(或≤)
子节点的值。
如果任意节点的值总是 ≥
子节点的值,称为:最大堆、大根堆、大顶堆。堆顶元素是最大值。如果任意节点的值总是 ≤
子节点的值,称为:最小堆、小根堆、小顶堆。堆顶元素是最小值。
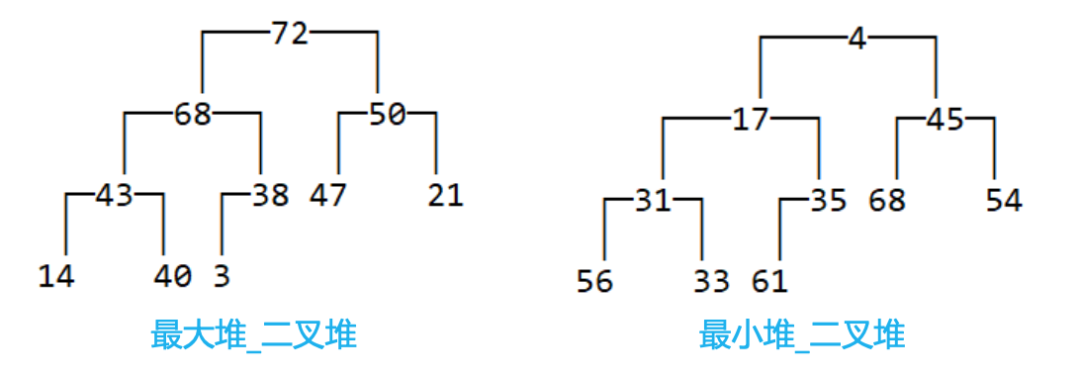
由此可见,堆中的元素必须具备可比较性(跟二叉搜索树一样)。
注意:不是每一层都比下一层节点值大,是节点值比子节点的值大。
1.2. 接口设计
int size(); // 元素的数量
boolean isEmpty(); // 是否为空
void clear(); // 清空
void add(E element); // 添加元素
E get(); // 获得堆顶元素
E remove(); // 删除堆顶元素
E replace(E element); // 删除堆顶元素的同时插入一个新元素
二、二叉堆
二叉堆(Binary Heap)的逻辑结构就是一棵完全二叉树,所以也叫完全二叉堆。
鉴于完全二叉树的一些特性,二叉堆的底层(物理结构)一般用数组实现即可。
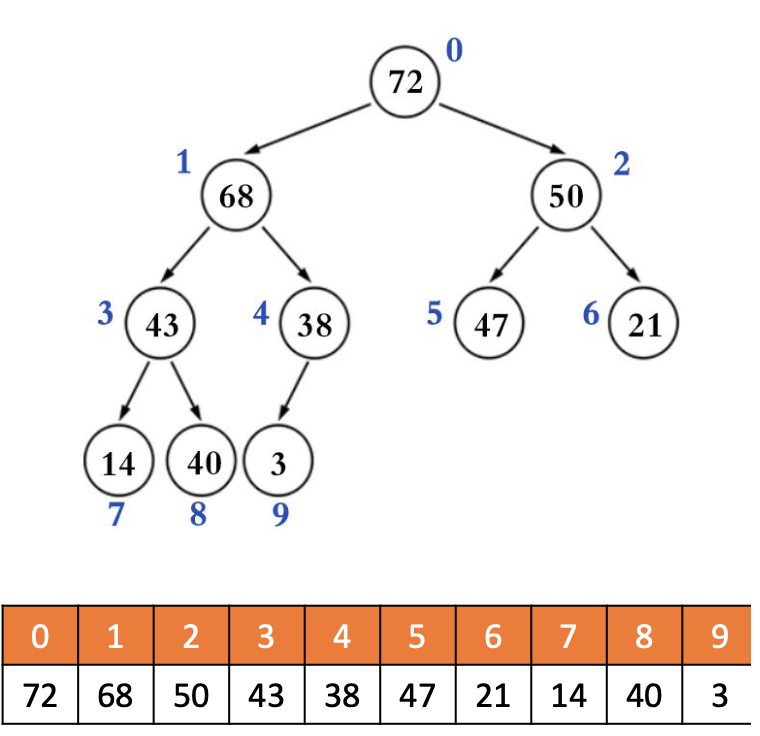
索引i
的规律(n是元素数量):
如果 i = 0
,它是根节点如果 i > 0
,它的父节点的索引为floor((i – 1) 2)如果 2i + 1 ≤ n – 1
,它的左子节点的索引为2i + 1如果 2i + 1 > n – 1
,它无左子节点如果 2i + 2 ≤ n – 1
,它的右子节点的索引为2i + 2如果 2i + 2 > n – 1
,它无右子节点
2.1. 最大堆
2.1.1. 添加
首选确认的是,元素不能添加到最后面,因为有可能数组前面的元素值比添加的元素值小。所以,添加的元素需要和父节点元素值进行比较。
实现思路:
循环执行以下操作(下图中的80简称为node
):
如果 node > 父节点
,与父节点交换位置;如果 node ≤ 父节点
,或者node
没有父节点,退出循环。
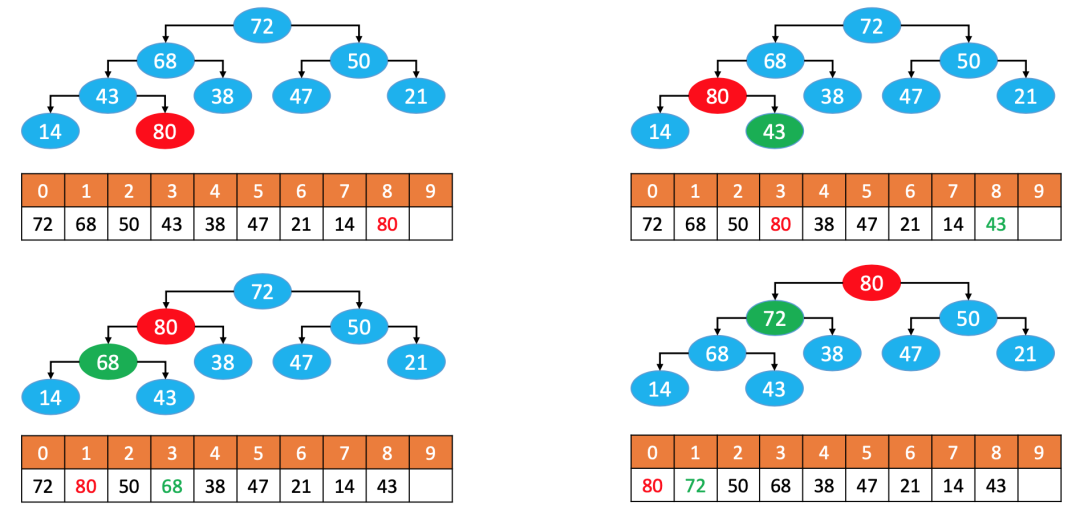
这个过程,叫做上滤(Sift Up),时间复杂度:O(logn)
。
实现代码:
// 添加
public void add(E element) {
elementNotNullCheck(element);
ensureCapacity(size + 1);
elements[size++] = element;
siftUp(size - 1);
}
/**
* 让index位置的元素上滤
* @param index
*/
private void siftUp(int index) {
E e = elements[index];
while (index > 0) {
// 父节点索引 floor((i – 1) / 2) float -> int类型转换默认向下取整
int pindex = (index - 1) >> 1;
E p = elements[pindex];
if (compare(e, p) <= 0) return;
// 交换index、pindex位置的内容
E tmp = elements[index];
elements[index] = elements[pindex];
elements[pindex] = tmp;
// 重新赋值index(下一次循环)
index = pindex;
}
}
// 扩容
private void ensureCapacity(int capacity) {
int oldCapacity = elements.length;
if (oldCapacity >= capacity) return;
// 新容量为旧容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
E[] newElements = (E[]) new Object[newCapacity];
for (int i = 0; i < size; i++) {
newElements[i] = elements[i];
}
elements = newElements;
}
// 元素非空检查
private void elementNotNullCheck(E element) {
if (element == null) {
throw new IllegalArgumentException("element must not be null");
}
}
一般交换位置需要3行代码,可以进一步优化。将新添加节点备份,确定最终位置才摆放上去。
private void siftUp(int index) {
E element = elements[index];
while (index > 0) {
int parentIndex = (index - 1) >> 1;
E parent = elements[parentIndex];
if (compare(element, parent) <= 0) break;
// 将父元素存储在index位置
elements[index] = parent;
// 重新赋值index
index = parentIndex;
}
elements[index] = element;
}
仅从交换位置的代码角度看,上滤可以由大概的3 * O(logn)
优化到1 * O(logn) + 1
。
2.1.2. 删除
删除其实就是删除堆顶元素。如果直接按照数组的删除方法,把数组的第一个元素删除,那么数组后面的元素就需要往前移,时间复杂度是O(n)
。
正确做法是用数组的最后一个元素覆盖数组的第一个元素,然后把最后一个元素删除。但是仅仅这样做不符合最大堆的性质,因此需要把堆顶元素往下进行比较。
实现思路:
用最后一个节点覆盖根节点 删除最后一个节点 循环执行以下操作(下图中的43简称为node) 如果 node < 最大的子节点
,与最大的子节点交换位置如果 node ≥ 最大的子节点
,或者node
没有子节点,退出循环
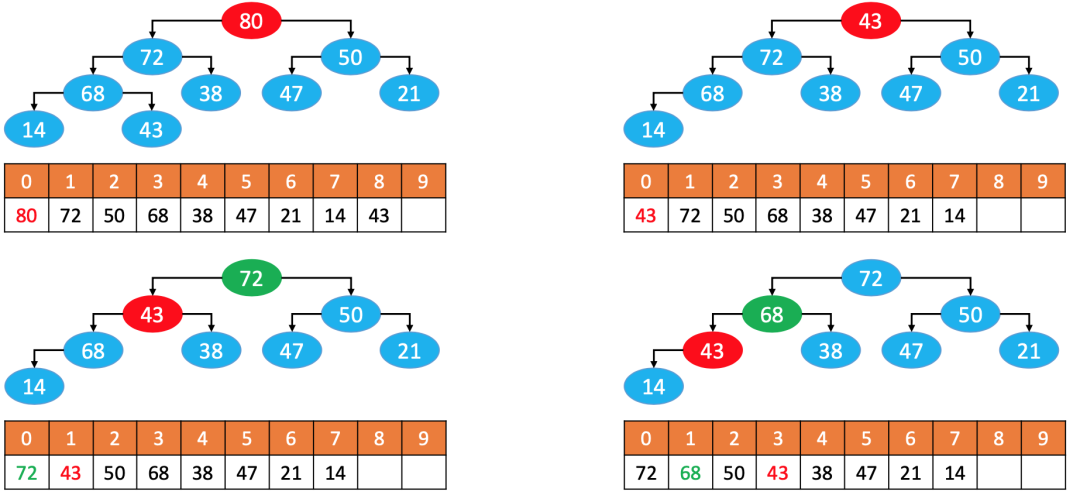
这个过程,叫做下滤(Sift Down),时间复杂度:O(logn)
。
实现代码:
// 删除堆顶元素
public E remove() {
emptyCheck();
int lastIndex = --size;
E root = elements[0];
elements[0] = elements[lastIndex];
elements[lastIndex] = null;
siftDown(0);
return root;
}
/**
* 让index位置的元素下滤
* @param index
*/
private void siftDown(int index) {
E element = elements[index];
int half = size >> 1;
// 第一个叶子节点的索引 == 非叶子节点的数量
// index < 第一个叶子节点的索引
// 必须保证index位置是非叶子节点
while (index < half) {
// index的节点有2种情况
// 1.只有左子节点
// 2.同时有左右子节点
// 默认为左子节点跟它进行比较
int childIndex = (index << 1) + 1;
E child = elements[childIndex];
// 右子节点
int rightIndex = childIndex + 1;
// 选出左右子节点最大的那个
if (rightIndex < size && compare(elements[rightIndex], child) > 0) {
child = elements[childIndex = rightIndex];
}
if (compare(element, child) >= 0) break;
// 将子节点存放到index位置
elements[index] = child;
// 重新设置index
index = childIndex;
}
elements[index] = element;
}
// 空堆检查
private void emptyCheck() {
if (size == 0) {
throw new IndexOutOfBoundsException("Heap is empty");
}
}
计算叶子节点和非叶子节点数量可回顾二叉树中计算节点的内容:

2.1.3. 获取堆顶元素
获取堆顶元素其实就是获取数组中的第一个元素。
public E get() {
emptyCheck();
return elements[0];
}
2.1.4. 替换堆顶元素
如果replace
操作是先移除堆顶元素,再添加元素,时间复杂度就是2logn
。为了减少不必要的操作,可以直接把堆顶元素替换掉,然后执行下滤操作,时间复杂度是logn
。
public E replace(E element) {
elementNotNullCheck(element);
E root = null;
if (size == 0) {
elements[0] = element;
size++;
} else {
root = elements[0];
elements[0] = element;
siftDown(0);
}
return root;
}
2.2. 批量建堆
如果一个数组中的数据是无序的,如何把数组中的数据快速建立成一个堆,这种操作叫做批量建堆(Heapify)。
批量建堆,有2种做法:
自上而下的上滤 自下而上的下滤
2.2.1. 自上而下的上滤
从堆顶开始,每一个节点做上滤操作(堆顶元素没有必要上滤),最终把数组中的数据变成一个最大堆。
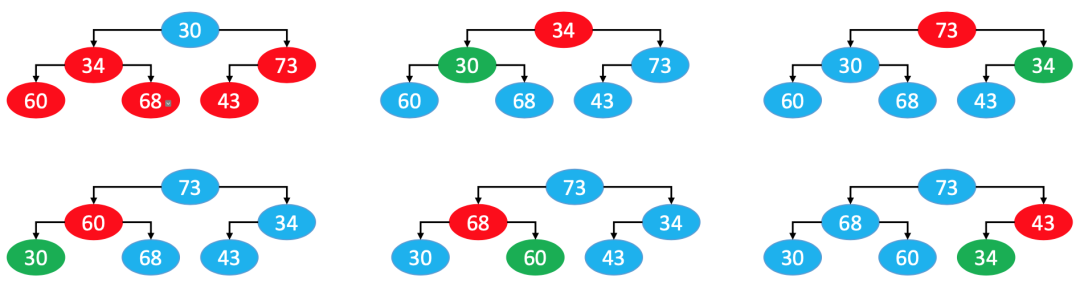
其实就是在原来已经是最大堆的基础上添加元素(本质类似于添加堆节点)。
for (int i = 1; i < size; i++) {
siftUp(i);
}
2.2.2. 自下而上的下滤
从最后一个元素开始,每一个节点做下滤操作(叶子节点没有必要下滤),最终把数组中的数据变成一个最大堆。
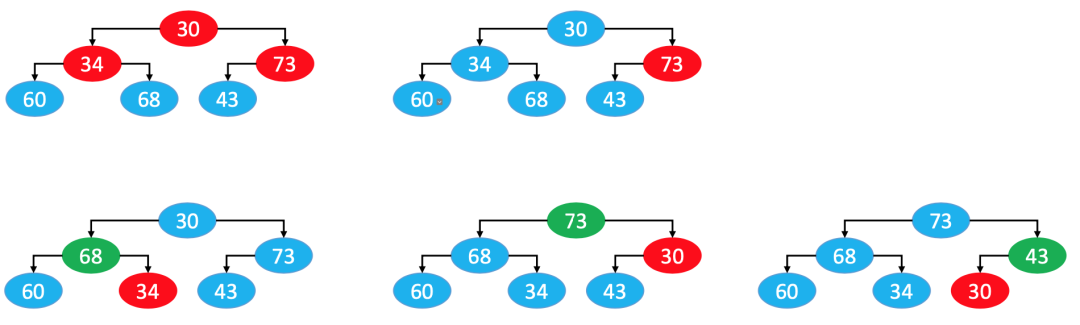
每个非叶子节点做下滤操作时,它的左右子节点一定是一个最大堆(本质类似于删除最大堆)。
for (int i = (size >> 1) - 1; i >= 0; i--) {
siftDown(i);
}
2.2.3. 效率对比
从代码表象来看,自下而上的下滤(非叶子节点)效率是比自上而下的上滤(除根节点外的每个节点)效率高的。下面从二叉树角度分析两者的效率。
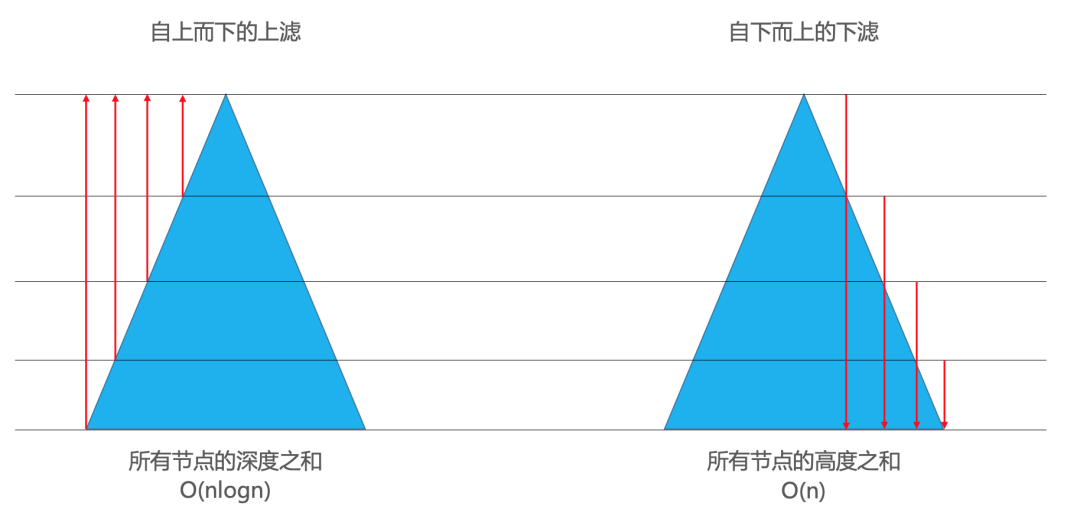
所有节点的深度之和:
仅仅是叶子节点,就有近n/2
个,而且每一个叶子节点的深度都是O(logn)
级别的。因此,在叶子节点这一块,就达到了O(nlogn)
级别。O(nlogn)
的时间复杂度足以利用排序算法对所有节点进行全排序。
所有节点的高度之和:
假设是满树,节点总个数为n
,树高为h
,那么n = 2^h − 1
。计算所有节点的高度之和H(n)
:
H(n) = 2^0 * (h − 0) + 2^1 * (h − 1) + 2^2 * (h − 2) + … + 2^(h − 1) * [h − (h − 1)]
= h * (2^0 + 2^1 + 2^2 + … + 2^(h − 1)) − [1 * 2^1 + 2 * 2^2 + 3 * 2^3 + … + (h − 1) * 2^(h − 1)]
= h * (2^h - 1) - [(h - 2) * 2^h + 2]
= h * 2^h - h - h * 2^h + 2^(h + 1) - 2
= 2^(h + 1) - h - 2
= 2 * (2^h - 1) - h
= 2n - h
= 2n - log2(n + 1)
= O(n)
公式推导:
S(h) = 1 * 2^1 + 2 * 2^2 + 3 * 2^3 + … + (h − 2) * 2^(h − 2) + (h − 1) * 2^(h − 1)
2S(h) = 1 * 2^2 + 2 * 2^3 + 3 * 2^4 + … + (h − 2) * 2^(h − 1) + (h − 1) * 2^h
S(h) – 2S(h) = 2^1 + 2^2 + 2^3 + … + 2^(h - 1) - (h - 1) * 2^h
= 2^h - 2 - (h - 1) * 2^h
S(h) = (h - 1) * 2^h - (2^h - 2)
= (h - 2) * 2^h + 2
2.3. 最小堆
最小堆可以在最大堆的基础上改变比较的方向即可(把最小的值放在最前面)。
BinaryHeap<Integer> heap = new BinaryHeap<>(data, new Comparator<Integer>() {
public int compare(Integer o1, Integer o2) {
// o1 - o2 是最大堆;o2 - o1 是最小堆,具体实现可查看compare方法。
return o2 - o1;
}
});
2.4. 面试题
面试中经常会问到Top K问题(从n个整数中,找出最大的前 k个数,k远远小于n)。
如果使用快排算法进行全排序,需要O(nlogn)
的时间复杂度。
如果使用二叉堆来解决,可以使用O(nlogk)
的时间复杂度来解决。
使用二叉堆解决步骤:
新建一个小顶堆 扫描n个整数 先将遍历到的前k个数放入堆中 从第 k + 1
个数开始,如果大于堆顶元素,就使用replace
操作(删除堆顶元素,将第k + 1
个数添加到堆中)扫描完毕后,堆中剩下的就是最大的前k个数
// 新建一个小顶堆
BinaryHeap<Integer> heap = new BinaryHeap<>(new Comparator<Integer>() {
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
// 找出最大的前k个数
int k = 3;
Integer[] data = {51, 30, 39, 92, 74, 25, 16, 93, 91, 19,
54, 47, 73, 62, 76, 63, 35, 18, 90, 6,
65, 49, 3, 26, 61, 21, 48};
for (int i = 0; i < data.length; i++) {
if (heap.size() < k) { // 前k个数添加到小顶堆
heap.add(data[i]); // logk
} else if (data[i] > heap.get()) { // 如果是第k + 1个数,并且大于堆顶元素
heap.replace(data[i]); // logk
}
}
为什么使用小顶堆而不是大顶堆?因为是拿堆顶元素和第k + 1
元素进行比较的,当k + 1
元素大于堆顶元素时,把堆顶元素替换掉,堆中剩余的元素绝对是遍历过的元素中最大的前k个元素。
如果是找出最小的前k个数呢?用大顶堆,如果小于堆顶元素,就使用replace
操作。
三、LeetCode
数组中的第K个最大元素:https://leetcode-cn.com/problems/kth-largest-element-in-an-array/
根据字符出现频率排序:https://leetcode-cn.com/problems/sort-characters-by-frequency/
数据流中的第K大元素:https://leetcode-cn.com/problems/kth-largest-element-in-a-stream/
有序矩阵中第K小的元素:https://leetcode-cn.com/problems/kth-smallest-element-in-a-sorted-matrix/
前K个高频元素:https://leetcode-cn.com/problems/top-k-frequent-elements/
前K个高频单词:https://leetcode-cn.com/problems/top-k-frequent-words/
查找和最小的K对数字:https://leetcode-cn.com/problems/find-k-pairs-with-smallest-sums/
合并K个排序链表:https://leetcode-cn.com/problems/merge-k-sorted-lists/

