在工作中,很多人面临必须分析由多个表和数千个关系组成的 SQL 数据库的数据模型的挑战。在这种规模下,phpMyAdmin内置的可视化功能不足以深入了解结构。我们介绍一个工具,可以在其中应用各种过滤器(例如,表和列名称、行计数、连接数),然后以易于掌握的视觉表示形式查看过滤后的表及其关系。
获取数据
要可视化数据库的结构,我们首先需要获取有关表名和列名以及主键和外键的数据。幸运的是,SQL 数据库提供了一个非常好的此类信息来源: 信息模式。那是一个元数据库,即描述其他数据库的数据库——不是它们的内容,而是它们的结构、约束、数据类型等等。它由一堆表组成,但我们只需要其中三个:
表:从这里我们得到所有表的名称、它们所属的数据库(模式)、它们的行数和描述表的可选注释。
COLUMNS:这个表告诉我们所有表中每一列的列名,以及它属于哪个数据库和表。此外,我们可以获得数据类型、默认值和描述列的注释。
KEY_COLUMN_USAGE:就我们的目的而言,这是最重要的表。它告诉我们这些表是如何连接的,即,对于从一列到另一列的每个引用,它包含一个记录。此外,它还标识主键列。
我决定使用我的phpMyAdmin 访问数据库以 JSON 格式导出这三个表 。当然,你也可以直接访问信息架构(例如用 sshtunnel 和 SQLAlchemy的),但我想脱机工作的解决方案。以下代码将信息模式表中的数据加载到 Pandas (导入为 pd
)数据框中。
def load_from_json(self, file_name: str) -> pd.DataFrame:
df_raw = pd.read_json(file_name, orient='records')
df_data = df_raw[['data']].dropna()
data = df_data.iloc[0, 0]
df = pd.DataFrame(data)
return df
由于 JSON 导出的结构(文件包含我们不感兴趣的标题),我们需要提取数据列并删除空行。然后我们从数据框的第一个单元格中包含的数据中创建一个新框。生成的数据帧包含与信息模式表相同的数据,其 JSON 文件已传递给函数 load_from_json
。
现在我们使用此函数从上述信息模式表中获取有关表、列和引用的数据。我们从TABLES 表开始 。
def make_tables(self):
df = self.load_from_json(self.path + 'TABLES.json')
for index, row in df.iterrows():
name = row['TABLE_NAME']
db = row['TABLE_SCHEMA']
comment = row['TABLE_COMMENT']
N_rows = int(row['TABLE_ROWS'])
tab = information_schema.Table(name, db, N_rows, comment)
self.tables.add_table(tab)
使用pandas 数据框的 iterrows
功能, 我们遍历所有行,每行都为我们提供表的名称、数据库(架构)、注释和行数。最后两行值得解释一下: 是一个模块,我在其中定义了用于存储表、列及其关系上的数据的结构。随着 我们创建一个收集特定表上所有数据的对象,最后一行代码将此表添加到一个 对象中,如下所示:information_schema``information_schema.Table(...)``TableCollection
class TableCollection():
def __init__(self):
self.tables = {}
def __len__(self) -> int:
return len(self.tables)
def add_table(self, table: Table):
self.tables[(table.db, table.name)] = table
在这个表集合中,表对象存储在一个字典中,该字典使用由数据库(模式)名称和表名称组成的元组作为键(相同的表名称可能会在多个数据库中使用)。
现在我们在TableCollection
结构中拥有所有表 ,是时候添加关于列的信息,我们从 信息模式的COLUMNS表的 JSON 导出加载 这些信息。
def make_cols(self):
df = self.load_from_json(self.path + 'COLUMNS.json')
for index, row in df.iterrows():
name = row['COLUMN_NAME']
db = row['TABLE_SCHEMA']
table = row['TABLE_NAME']
dtype = row['COLUMN_TYPE']
default = row['COLUMN_DEFAULT']
comment = row['COLUMN_COMMENT']
col = information_schema.Column(name, dtype, default, comment)
self.tables.tables[(db, table)].add_col(col)
同样,我们遍历所有行,每一行描述我们已经加载的名称等表之一的一列。在最后两行中,我们创建了一个存储特定列属性的对象,然后将该information_schema.Column
对象添加 到它所属的表中,方法是将其传递给属于表集合中相应字典条目的函数。
现在我们在我们的TableCollection
对象中有关于表及其列的信息 。仍然缺少的是关于主键和外键的信息,我们从 信息模式的KEY_COLUMN_USAGE表中获取 这些信息。
def set_keys(self):
df = self.load_from_json(self.path + 'KEY_COLUMN_USAGE.json')
for index, row in df.iterrows():
col_name = row['COLUMN_NAME']
db = row['TABLE_SCHEMA']
table = row['TABLE_NAME']
if row['CONSTRAINT_NAME'].lower() == 'primary':
is_primary = True
else:
is_primary = False
ref_db = row['REFERENCED_TABLE_SCHEMA']
ref_table = row['REFERENCED_TABLE_NAME']
ref_col = row['REFERENCED_COLUMN_NAME']
self.tables.tables[(db, table)].cols[col_name].is_primary_key = is_primary
if not ref_col is None:
tab = self.tables.tables[(db, table)]
tab.cols[col_name].add_reference(ref_db, ref_table, ref_col)
作为其所属表中主键的列在KEY_COLUMN_USAGE 的“CONSTRAINT_NAME”列中由值“PRIMARY” 标记。我们使用这些信息来设置相应属性 is_primary
的的 Column
对象。如果列是外键,则在“REFERENCED_TABLE_SCHEMA”、“REFERENCED_TABLE_NAME”和“REFERENCED_COLUMN_NAME”中指定引用的数据库、表和列。这些数据被添加到Column
上面代码最后一行的 对象中。
创建图表
如果您不熟悉 图论:图是由一组对象(节点)和这些对象(边)之间的一组连接组成的数学结构。这样的结构正是我们探索数据模型所需要的:表将是图的节点,表之间的引用将是它的边。
我们将使用 networkx 包来创建图,这需要四个步骤:
导入包:
import networkx as nx初始化一个图形对象,例如:
g = nx.Graph()使用 添加节点
g.add_node(node)
,其中node
可以是除 之外的任何可散列对象None
。我们还可以传递被解释为节点属性的关键字参数。使用
g.add_edge(node_1, node_2)
,也可以选择使用包含边属性的关键字参数在我们的节点之间添加边 。请注意,原则上可以跳过第 3 步,因为节点将与边一起自动创建,以防它们不存在。
但是在构建图形之后我们还没有完成。我们还想稍后对其进行操作(请记住,我正在处理 500 多个表并需要应用过滤器),为此我们编写了以下 GraphManipulator
类:
class GraphManipulator():
def __init__(self):
self.graph = nx.DiGraph()
self.graph_backup = None
self.tables = None
def load(self, tables: TableCollection):
self.tables = tables
self._make_nodes()
self._make_edges()
self._add_edge_count_attribs()
self.graph_backup = self.graph.copy(as_view=False)
在实例化 GraphManipulator
对象时,将创建图形对象。请注意,我们DiGraph()
在这里使用 ( networkx 包被导入为 nx
),它创建了一个有向图,即当创建一条边时,两个连接节点的顺序很重要。我们这样做是为了以后可以绘制从引用表指向被引用表的箭头。
该 load
函数将我们的 TableCollection
对象作为参数,因此该 GraphManipulator
对象可以访问我们从信息模式中获得的数据。然后由名称以下划线开头的三个函数构建图形,最后保存图形对象的副本,以便在使用过滤器后恢复它(稍后会详细介绍)。让我们来看看构建图形的三个函数。
我们从节点开始:
def _make_nodes(self):
for tab in self.tables.tables.values():
identifier = self._build_node_id(tab.db, tab.name)
f_keys = tab.get_foreign_keys()
references = []
for key in f_keys:
ref_str = ''
col = tab.cols[key]
N_refs = len(col.referenced_cols)
for i in range(N_refs):
ref_db = col.referenced_dbs[i]
ref_table = col.referenced_tables[i]
ref_col = col.referenced_cols[i]
ref_id = self._build_node_id(ref_db, ref_table)
ref_str += '%s:%s, ' % (ref_id, ref_col)
ref_str = ref_str[:-2]
references.append(ref_str)
attributes = {'db': tab.db,
'table': tab.name,
'primary_key': tab.get_primary_key(),
'foreign_keys': f_keys,
'references': references,
'cols': list(tab.cols.keys()),
'N_rows': tab.N_rows,
'N_edges_upstream': 0,
'N_edges_downstream': 0}
self.graph.add_node(identifier, **attributes)
上面的代码循环遍历其信息存储在TableCollection
对象中的所有表 (此处 self.tables
)。该函数 _build_node_id
只返回一个由数据库名和表名组成的字符串。该字符串对于每个表都是唯一的,并用作节点对象。通过 tab.get_foreign_keys()
我们得到表中作为外键的列的列表,即它们引用其他表的主键列。
接下来,我们遍历列表中的所有外键, 为每个外键 f_keys
添加一个字符串到列表 references
中。此字符串包含引用列的数据库(架构)、表和列名称。最后,我们将我们感兴趣的所有属性(例如我们刚刚编译的引用列表)放入 attributes
字典中,并在我们的图中添加一个节点,并附加这些属性。请注意,两个方向的边数(字典中的最后两个条目)是稍后设置的。
现在我们有了所有的节点,是时候将边添加到我们的图中了。
def _make_edges(self):
for tab in self.tables.tables.values():
id_from = self._build_node_id(tab.db, tab.name)
for col in tab.cols.values():
for i in range(len(col.referenced_tables)):
ref_tab = col.referenced_tables[i]
ref_db = col.referenced_dbs[i]
id_to = self._build_node_id(ref_db, ref_tab)
self.graph.add_edge(id_from, id_to)
同样,我们遍历所有表,并为每个表遍历所有包含的列。最里面的循环查看一列的所有引用(一列可能引用其他几列)。上面代码的最后一行添加了一条从引用列到被引用列的边(记住,我们这里有一个有向图)到图形对象。
我认为在节点属性中同时包含从给定表到其他表的引用数以及从其他表到该表的引用数会很有用。
def _add_edge_count_attribs(self):
for node_1 in self.graph.nodes:
N_down = 0
N_up = 0
for node_2 in self.graph.nodes:
N_down += self.graph.number_of_edges(node_1, node_2)
N_up += self.graph.number_of_edges(node_2, node_1)
self.graph.nodes[node_1]['N_edges_upstream'] = N_up
self.graph.nodes[node_1]['N_edges_downstream'] = N_down
我将这些属性命名为 N_edges_downstream
and N_edges_upstream
,并使用number_of_edges
图形对象的函数获取它们的值 ,如上所示。正如您在代码中看到的,访问节点属性很容易: graph.nodes[name_of_node]['name_of_attribute']
. 现在我们的图形已经完成,我们可以将其可视化。但在我们这样做之前,让我们简要地谈谈过滤。
按节点属性过滤
正如我在本文开头所说,我正在处理一个由 500 多个表组成的数据库。显然,对于大多数人的大脑来说,一次接收太多信息。因此,我为我的 Python 脚本配备了过滤选项。原理很简单,包括以下步骤:
将我们在构建后立即保存的图的备份复制到图对象,如下所示: 这是必要的,因为我们希望将过滤器应用于原始图,而不是已过滤的图。
self.graph = self.graph_backup.copy(as_view=False)循环遍历图中的所有节点。
将节点属性与您的过滤条件进行比较,如果这些比较中的任何一项表明该节点不符合条件,请使用 将其删除
graph.remove_node(node)
。
在此过程之后,只有符合过滤条件的表才会作为节点留在图表中。它们之间的边不受影响,而将它们连接到已删除节点的边不再是图的一部分。我实现了以下过滤器:
数据库(模式)、表和列的名称(字符串与通配符比较)。
行数。
列数。
连接数,即对其他表的引用或来自其他表的引用。
有时过滤某些表很有用,例如,所有表的名称中都带有给定的字符串,然后还显示与过滤后剩下的表相连的所有表。为此,我编写了以下函数。
def extend_depth(self, depth: int):
g0 = self.graph_backup
keep_list = []
for i in range(depth):
for node in self.graph.nodes:
keep_list.append(node)
neighbors = (list(g0.neighbors(node)) +
list(g0.predecessors(node)))
for neighbor in neighbors:
keep_list.append(neighbor)
self.graph = g0.copy(as_view=False)
node_list = list(self.graph.nodes)
for node in node_list:
if not node in keep_list:
self.graph.remove_node(node)
整数参数 depth
确定此连接扩展的范围。案例 depth = 1
对应于我上面所说的,而 depth = 2
不仅包括连接的表,还包括连接到这些表的表,等等。换句话说,所有depth
距离过滤节点(self.graph.nodes
)不超过边的节点都将被保留 。
我们通过遍历过滤图中的所有节点并将它们以及它们的相邻节点添加到要保留的节点列表来实现这一点。请注意,对于有向图, DiGraph.neighbors(node)
和 DiGraph.predecessors(node)
将分别给我们一个节点的后继和前驱,即它在两个方向上的邻居。对于无向图,您只能使用 Graph.neighbors(node)
. 一旦我们有了要保留的节点列表,我们只需用未过滤的备份覆盖我们的图,然后删除不在列表中的所有节点。如果 depth
大于 1,则新的迭代将从self.graph
包含我们刚刚放在保持列表中的所有节点开始 。
在 Web 应用程序中可视化图形
该 networkx 包提供了基本的 可视化功能,但这并不是它的地方优势所在。我决定使用Dash开发一个 Web 应用程序, 因为它允许对数据库结构进行交互式探索。如果您不熟悉 Dash,请查看其文档并查看 绘图 可视化示例,以了解您可以使用它做什么。您还可以 在 Medium上找到一些关于使用Dash 的有用文章 。
为了可视化网络图和应用过滤器,我发现这些 Dash plotly 功能特别有用:
您无需大量编码即可构建 Web 应用程序(也可以在本地运行)。
您不需要编写 HTML 或 JavaScript 代码,除非您想将应用程序扩展到Dash提供的范围之外 。
您无需为可视化重新发明轮子,因为 plotly 已经具有缩放、平移、在鼠标悬停事件时显示注释以及以 PNG 格式保存绘图的功能等功能。
有关如何使用Dash构建 Web 应用程序的详细信息 ,请访问我上面提供的链接。这里我只简单介绍一下应用程序,然后讨论有趣的部分,即可视化图形的代码。这些是创建 Web 应用程序的基本步骤:
导入您需要的模块,在本例
dash
中为dash_core_components
(asdcc
)、dash_bootstrap_components
(asdbc
) 和dash_html_components
(ashtml
) 以创建应用程序和添加控件。由于我们想在回调函数中访问控件的内容,因此我们还需要:from dash.dependencies import Input, Output创建一个 Dash 应用程序对象,如下所示:在这一行中,您可以通过向函数传递参数来做很多事情。例如,您可以通过指定 CSS 文件来更改 GUI 的外观。
app = dash.Dash(…)创建您需要的所有控件(文本标签、输入字段、下拉菜单等)。使用 dash_bootstrap_components, 您可以轻松地将它们按行和列排列以创建响应式布局。绘图区域是一个
dash_core_components.Graph
对象(不要与我们的网络图混淆)。这些控件组(行内的列)被收集在一个容器对象中并插入到
layout
我们的 Dash 应用程序对象的 属性中:app.layout = html.Div(dbc.Container([…]))最后,我们链接功能来使用我们的控制
@app.callback
装饰,如所描述 这里。
现在我们来谈谈如何绘制网络图。当“更新图表”按钮的回调被触发时执行相应的代码。这个回调函数的返回值是一个 plotly.graph_objs.Figure
对象,它的输出被设置为'figure'
绘图区(dash_core_components.Graph
对象)的 属性。
在实际绘制之前,我们需要计算网络图节点的位置。幸运的是, networkx 包可以为我们完成繁重的工作,因为它包含用于以有用的方式排列节点的布局功能。我在 GUI 中添加了一个下拉菜单,允许用户选择他们想要应用的布局功能。我实现了以下选项(networkx 导入为 nx
):
pos = nx.layout.planar_layout(graph)
此函数尝试定位节点,以便可以绘制所有边而不会交叉,从而创建整洁的可视化。如果这是不可能的,则会引发错误。pos = nx.layout.shell_layout(graph, nlist=node_list)
这将根据nlist
(节点列表列表)的内容将节点排列在同心圆(壳 )中。我选择根据节点的边数将节点分配给外壳(连接最多的节点位于中心)。当要显示的节点很少且边缘很多且节点很多时,这对于获取概览很有用。pos = nx.layout.spring_layout(graph)
应用这个布局函数创建一个力导向的布局,即边缘像弹簧一样,节点相互排斥。通过为节点分配权重属性,可以单独更改弹簧的吸引力(否则所有节点的值都相同)。我发现这种布局对于在所有节点具有相似边数的非平面图中创建顺序很有用。pos = nx.layout.kamada_kawai_layout(graph)
Kamada-Kawai 算法也产生力导向布局,但会影响每对节点的图距离(最短路径中的边数)。它对于识别强连接节点的集群很有用。
通过调用布局函数之一计算节点位置后,这些位置被传递给图形对象,如下所示: nx.set_node_attributes(graph, name='pos', values=pos)
现在我们有可用的节点位置作为节点属性,我们可以开始绘图。我们将从边缘开始。
line = {'width': 1,
'color': '#FFFFFF'}
edge_trace = go.Scatter(x=[], y=[], line=line,
hoverinfo='none', mode='lines')
annotations = []
for edge in graph.edges():
x0, y0 = graph.nodes[edge[0]]['pos']
x1, y1 = graph.nodes[edge[1]]['pos']
edge_trace['x'] += tuple([x0, x1])
edge_trace['y'] += tuple([y0, y1])
edge_annot = {'x': x1,
'y': y1,
'xref': 'x',
'yref': 'y',
'text': '',
'showarrow': True,
'axref': 'x',
'ayref': 'y',
'ax': x0,
'ay': y0,
'arrowhead': 3,
'arrowwidth': 1,
'arrowsize': 2,
'arrowcolor': '#FFFFFF'}
annotations.append(edge_annot)
上面的代码创建了散点图对象edge_trace
(导入 plotly.graph_objs
as 后 go
),我们将描述用于绘制边缘的线类型的字典传递给该对象 。然后我们遍历图中的所有边,并通过访问'pos'
我们刚刚分配的属性来提取相应的开始和结束节点(分别为索引 0 和 1)的坐标对 。这些位置被添加到散点图对象内的坐标数据中。由于我们希望箭头从引用指向被引用的表节点,因此我们创建了 list annotations
。对于每条边,我们将一个条目添加到此列表中,这是一个描述我们要绘制的箭头的字典。
接下来,我们处理节点(所有元素的实际绘制发生在最后)。
conn_ticks = [0, 1, 3, 10, 30, 100]
log_arg_ticks = [x + 1 for x in conn_ticks]
tick_vals = list(np.log10(log_arg_ticks))
cbar = {'thickness': 15,
'title': 'Connections',
'xanchor': 'left',
'titleside': 'right',
'tickvals': tick_vals,
'ticktext': [str(x) for x in conn_ticks]}
marker = {'showscale': True,
'colorscale': 'Inferno',
'color': [],
'size': [],
'colorbar': cbar,
'cmin': tick_vals[0],
'cmax': tick_vals[-1]}
line = {'width': 2}
node_trace = go.Scatter(x=[], y=[], text=[], mode='markers',
hoverinfo='text', marker=marker, line=line)
使用颜色作为 节点拥有的连接数N的指标 。上面的代码创建了一个对数颜色条,这在有很多表很少连接和很少表有很多连接时很有用。该列表 conn_ticks
包含 我们想要标记刻度的N值 。由于存在N = 0 的节点 ,我们将使用 log( N + 1) 分配颜色,并相应地选择放置刻度标签的值 tick_vals
。字典 marker
定义了节点的外观,利用我们刚刚设置的颜色条和plotly的内置“Inferno”色标 。
正如我们对边所做的那样,我们创建了一个散点图对象,现在必须用描述每个节点的数据填充它。
for node in graph.nodes:
node_name = '%s/%s' % (graph.nodes[node]['db'],
graph.nodes[node]['table'])
connections = (graph.nodes[node]['N_edges_upstream'] +
graph.nodes[node]['N_edges_downstream'])
N_rows = graph.nodes[node]['N_rows']
N_cols = len(graph.nodes[node]['cols'])
prim_key = graph.nodes[node]['primary_key']
f_keys = graph.nodes[node]['foreign_keys']
refs = graph.nodes[node]['references']
node_info = node_name
node_info += '<br>'
node_info += 'primary key: %s' % prim_key
node_info += '<br>'
if len(f_keys) > 0:
node_info += 'foreign keys:<br>'
for i in range(len(f_keys)):
ref_str = ' %s -> %s<br>' % (f_keys[i], refs[i])
node_info += ref_str
node_info += 'rows: %i<br>' % N_rows
node_info += 'columns: %i<br>' % N_cols
node_info += 'connections: %i' % connections
x, y = graph.nodes[node]['pos']
node_trace['x'] += tuple([x])
node_trace['y'] += tuple([y])
if show_table_names:
node_annot = {'showarrow': False,
'text': '/<br>'.join(node_name.split('/')),
'xref': 'x',
'yref': 'y',
'x': x,
'y': y + 0.03}
annotations.append(node_annot)
node_trace['marker']['color'] += tuple([np.log10(connections + 1)])
size = 1.5 * np.log(N_rows + 2.) + 10
node_trace['marker']['size'] += tuple([size])
node_trace['text'] += tuple([node_info])
上面显示的代码循环遍历图中的所有节点并访问感兴趣的节点属性。这些属性被编译成 string node_info
,在代码的最后一行设置为鼠标悬停文本。正如我们对边所做的那样,我们提取节点位置(线 x, y = ...
)并将其添加到散点图对象的坐标数据中 node_trace
。如果要显示表名,必要的数据(node_annot
包含文本和位置的字典 )将添加到我们之前用于添加箭头的注释列表中。节点颜色是根据我们使用node_trace['marker']['color']
属性的对数颜色条设置的 。节点大小根据其行数设置(以最小值为对数)。
我们现在需要做的最后一件事是构建实际的图形对象。
margin = {'b': 20, 'l': 5, 'r': 5, 't': 40}
axis_props = {'showgrid': False,
'zeroline': False,
'showticklabels': False}
c_axis_props = {'cauto': False}
layout = go.Layout(showlegend=False, hovermode='closest',
margin=margin, annotations=annotations,
xaxis=axis_props, yaxis=axis_props,
coloraxis=c_axis_props,
plot_bgcolor='#A0A0A0')
fig = go.Figure(data=[edge_trace, node_trace], layout=layout)
return fig
上面的代码设置了绘图区域周围的边距,并定义了 x/y 轴 ( axis_props
) 以及颜色轴的属性(c_axis_props
;颜色范围自动缩放已关闭)。边距和轴字典与我们的注释列表(箭头和节点名称)一起传递给布局对象。最后我们创建了 plotly.graph_obs.Figure
“更新图形”按钮的回调函数返回到 'figure'
绘图区属性的对象。
这是我们所有努力的结果:

Web 应用程序的 GUI
上图显示了在搜索名称中带有字符串“auth”的所有表并将深度设置为 1(包括连接到搜索结果表的表)后的 Web 应用程序。请注意,出于数据保护的原因,我在这里更改了一些名称。
下面的屏幕截图演示了鼠标悬停功能,它允许快速检查网络图中表的最重要属性(在示例中选择了 Kamada-Kawai 布局,这对于识别集群通常很实用)。另请注意右上角的菜单栏,这是plotly的内置功能 ,允许缩放、平移和将图像保存为 PNG 文件。
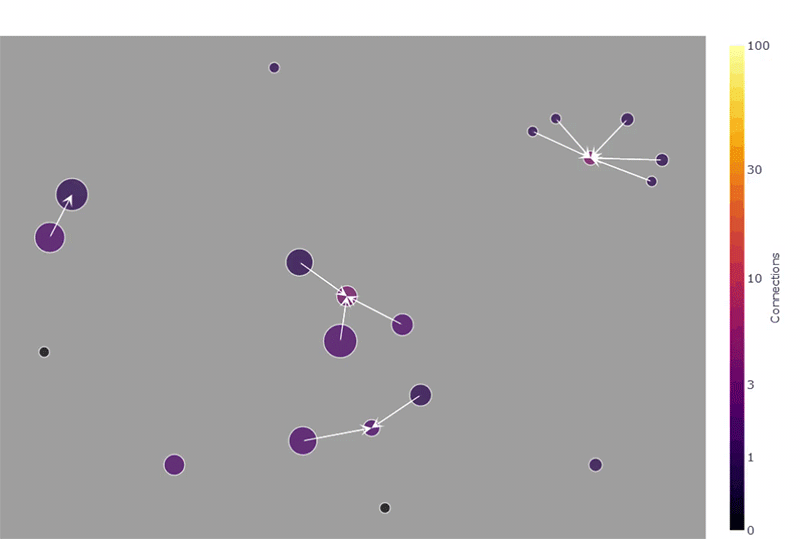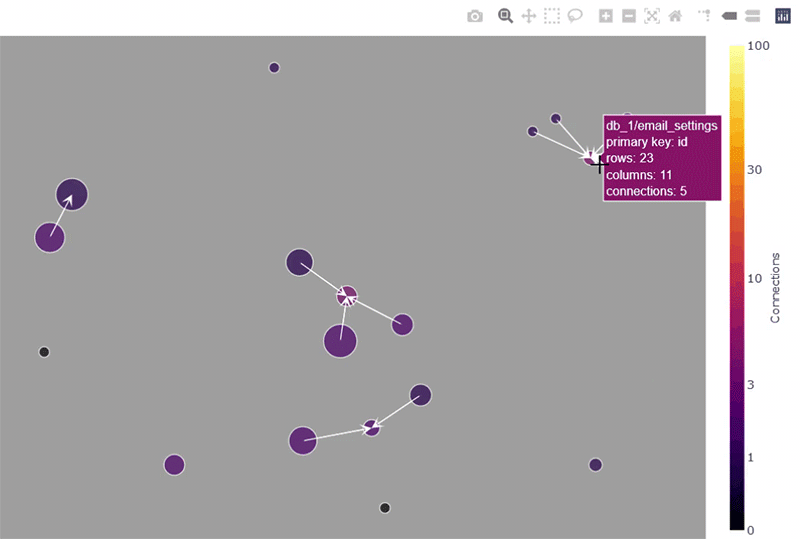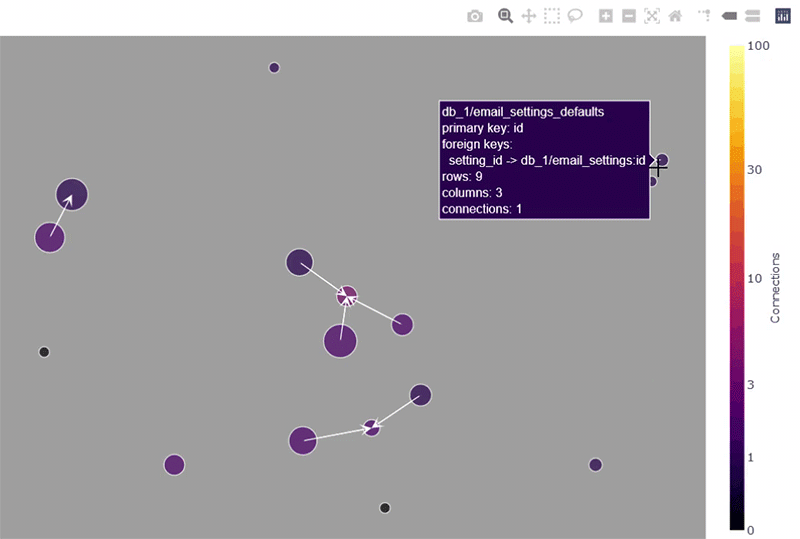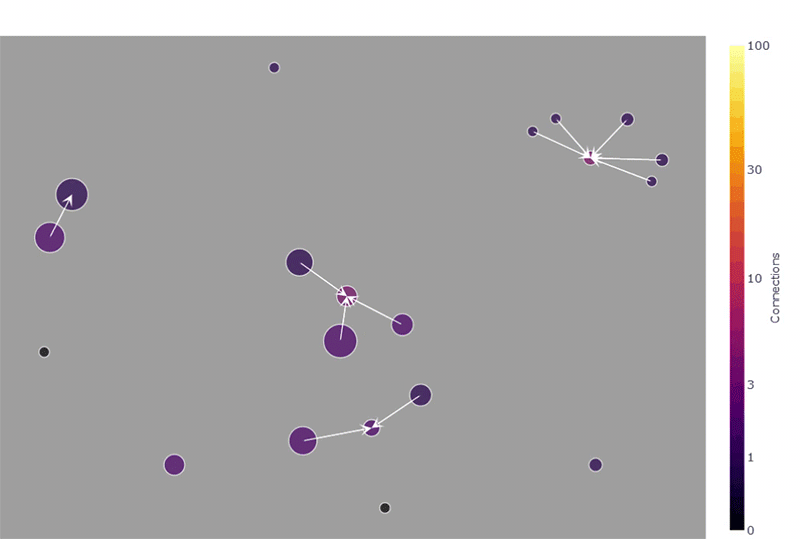
鼠标悬停功能是 plotly 的内置功能。