





什么是人脸识别?
人脸识别是将未知 个人的面部与存储记录数据库中的图像进行比较的任务 。映射可以是一对一或一对多的,这取决于我们是运行人脸验证还是人脸识别。
在本教程中,我们感兴趣的是构建一个面部识别系统,该系统将验证图像(通常称为探测图像)是否存在于预先存在的面部数据库(通常称为评估集)中。
视觉
构建这样一个系统涉及四个主要步骤:
1. 检测图像中的人脸
可用的人脸检测模型包括 MTCNN、FaceNet、Dlib 等。
2. 裁剪和对齐面以保持一致性
OpenCV 库提供了我们这一步所需的所有工具。
3. 找到每个人脸的向量表示
由于程序不能直接处理 jpg 或 png 文件,我们需要某种方式将图像转换为数字。在本教程中,我们将使用 Insightface 模型为人脸创建多维 (512-d) 嵌入,以便它封装 与人脸有关的有用 语义信息。
为了使用单个库处理所有三个步骤,我们将使用 insightface
. 特别是,我们将使用 Insightface 的 ArcFace 模型。
InsightFace 是一个开源的深度人脸分析模型,用于人脸识别、人脸检测和人脸对齐任务。
4. 比较嵌入
一旦我们将每个独特的人脸翻译成一个向量,比较人脸的要点就归结为比较相应的嵌入。我们将利用这些嵌入来训练 sci-kit 学习模型。
代码可以在 Github 上找到(https://github.com/V-Sher/Face-Search)。
设置
创建虚拟环境(可选):
python3 -m venv face_search_env
激活这个环境:
源 face_search_env/bin/activate
此环境中的必要安装:
pip 安装 mxnet==1.8.0.post0
pip install -U Insightface==0.2.1
pip install onnx==1.10.1
pip install onnxruntime==1.8.1
更重要的是,一旦您完成 pip 安装 insightface
:
– 从onedrive下载 模型版本 。(它包含两个用于检测和识别的预训练模型)。*~/.insightface/models/*``*~/.insightface/models/antelope/\*.onnx*
如果设置正确完成,它应该是这样的:

如果您查看antelope
目录内部 ,您会发现onnx
用于人脸检测和识别的两个模型:

数据集
我们将使用Kaggle 上(https://www.kaggle.com/olgabelitskaya/yale-face-database)可用的 Yale Faces 数据集 ,其中包含大约 15 个个人的 165 张灰度图像(即每个身份 11 个唯一图像)。图像由各种表情、姿势和照明配置组成。
获得数据集后,继续将其解压缩到data
项目中新创建的目录中(请参阅Github(https://github.com/V-Sher/Face-Search)上的项目目录结构 )。
开始
如果您想继续学习, 可以在 Github 上找到Jupyter Notebook(https://github.com/V-Sher/Face-Search/blob/main/notebooks/face-search-yale.ipynb)。
import os
import pickle
import numpy as np
from PIL import Image
from typing import List
from tqdm import tqdm
from insightface.app import FaceAnalysis
from sklearn.neighbors import NearestNeighbors
加载 Insightface 模型
一旦 insightface
被安装,我们必须调用 app=FaceAnalysis(name="model_name")
加载模型。
由于我们将onnx
模型存储在 antelope 目录中:
app = FaceAnalysis(name="antelope")
app.prepare(ctx_id=0, det_size=(640, 640))
生成 Insightface 嵌入
使用该insightface
模型为图像生成嵌入非常简单 。例如:
# Generating embeddings for an image
img_emb_results = app.get(np.asarray(img))
img_emb = img_emb_results[0].embedding
img_emb.shape
------------OUTPUT---------------
(512,)
数据集
在使用此数据集之前,我们必须修复目录中文件的扩展名,以便文件名以 .gif
. (或者 .jpg
, .png
等)。
例如,以下代码片段会将文件名更改 subject01.glasses
为 subject01_glasses.gif
.
# Fixing the file extensions
YALE_DIR = "../data/yalefaces"
files = os.listdir(YALE_DIR)[1:]
for i, img in enumerate(files):
# print("original name: ", img)
new_ext_name = "_".join(img.split(".")) + ".gif"
# print("new name: ", new_ext_name)
os.rename(os.path.join(YALE_DIR, img), os.path.join(YALE_DIR, new_ext_name))
接下来,我们将数据分为评估集和探针集:每个主体 90% 或 10 张图像将成为评估集的一部分,每个主体剩余的 10% 或 1 张图像将用于探针集中。
为避免采样偏差,将使用名为 的辅助函数随机选择每个对象的探测图像 create_probe_eval_set()
。它将包含属于特定主题的 11 张图像的(文件名)列表作为输入,并返回两个长度为 1 和 10 的列表。前者包含用于探测集的文件名,而后者包含用于评估集。
def create_probe_eval_set(files: List):
# pick random index between 0 and len(files)-1
random_idx = np.random.randint(0,len(files))
probe_img_fpaths = [files[random_idx]]
eval_img_fpaths = [files[idx] for idx in range(len(files)) if idx != random_idx]
return probe_img_fpaths, eval_img_fpaths
生成嵌入
由 返回的两个列表 create_probe_eval_set()
都按顺序提供给名为 的辅助函数 generate_embs()
。对于列表中的每个文件名,它读取灰度图像,将其转换为 RGB,计算相应的嵌入,最后返回嵌入以及图像标签(从文件名中提取)。
def generate_embs(img_fpaths: List[str]):
embs_set = list()
embs_label = list()
for img_fpath in img_fpaths:
# read grayscale img
img = Image.open(os.path.join(YALE_DIR, img_fpath))
img_arr = np.asarray(img)
# convert grayscale to rgb
im = Image.fromarray((img_arr * 255).astype(np.uint8))
rgb_arr = np.asarray(im.convert('RGB'))
# generate Insightface embedding
res = app.get(rgb_arr)
# append emb to the eval set
embs_set.append(res)
# append label to eval_label set
embs_label.append(img_fpath.split("_")[0])
return embs_set, embs_label
现在我们有了一个生成嵌入的框架,让我们继续使用 generate_embs()
.
# sorting files
files = os.listdir(YALE_DIR)
files.sort()
eval_set = list()
eval_labels = list()
probe_set = list()
probe_labels = list()
IMAGES_PER_IDENTITY = 11
for i in tqdm(range(1, len(files), IMAGES_PER_IDENTITY), unit_divisor=True): # ignore the README.txt file at files[0]
# print(i)
probe, eval = create_probe_eval_set(files[i:i+IMAGES_PER_IDENTITY])
# store eval embs and labels
eval_set_t, eval_labels_t = generate_embs(eval)
eval_set.extend(eval_set_t)
eval_labels.extend(eval_labels_t)
# store probe embs and labels
probe_set_t, probe_labels_t = generate_embs(probe)
probe_set.extend(probe_set_t)
probe_labels.extend(probe_labels_t)
需要考虑的几点:
返回的文件
os.listdir()
是完全随机的,因此第 3 行的排序很重要。为什么我们需要排序的文件名? 请记住create_probe_eval_set()
,第 11 行要求在任何一次迭代中都属于特定主题的所有文件。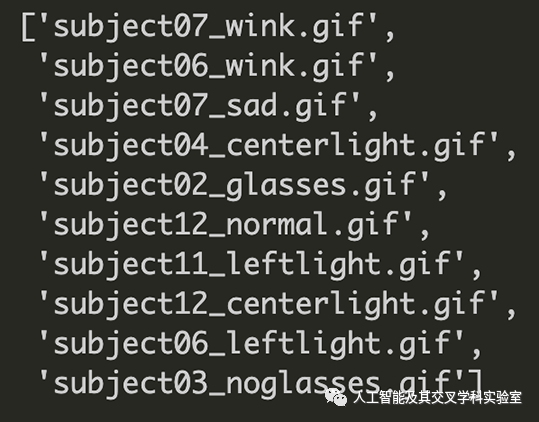
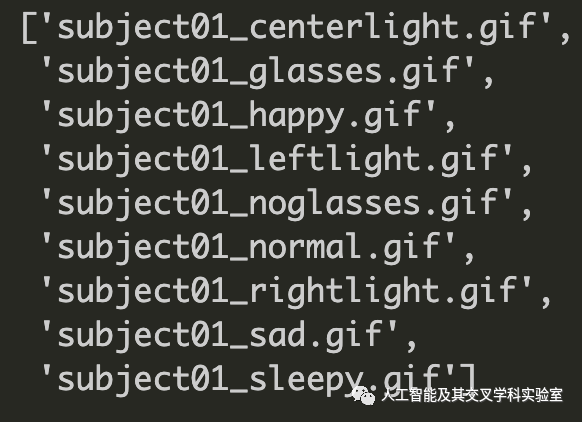
os.listdir() 的输出没有排序(上)和排序(下)
[可选]我们可以替换的
create_probe_eval_set()
功能,摆脱了for
循环,并在上面的代码片断简单的几行,如果我们使用了 分层train_test_split
提供的功能sklearn
。然而,在本教程中,我将清晰性置于代码简单性之上。
通常, insightface
无法检测到人脸并随后为其生成空嵌入。这解释了为什么probe_set
或 eval_set
列表中的某些条目 可能为空。重要的是我们过滤掉它们并只保留非空值。
为此,我们创建了另一个名为 的辅助函数 filter_empty_embs()
:
def filter_empty_embs(img_set: List, img_labels: List[str]):
# filtering where insightface could not generate an embedding
good_idx = [i for i,x in enumerate(img_set) if x]
if len(good_idx) == len(img_set):
clean_embs = [e[0].embedding for e in img_set]
clean_labels = img_labels
else:
# filtering eval set and labels based on good idx
clean_labels = np.array(img_labels)[good_idx]
clean_set = np.array(img_set, dtype=object)[good_idx]
# generating embs for good idx
clean_embs = [e[0].embedding for e in clean_set]
return clean_embs, clean_labels
它将图像集(probe_set
或 eval_set
)作为输入 并删除那些insightface
无法生成嵌入的元素 (见第 6 行)。在此之后,它还更新标签( probe_labels
或 eval_labels
)(见第 7 行),使得集合和标签具有相同的长度。
最后,我们可以仅获得评估集和探针集中良好指标的 512-d 嵌入 :
evaluation_embs, evaluation_labels = filter_empty_embs(eval_set, eval_labels)
probe_embs, probe_labels = filter_empty_embs(probe_set, probe_labels)
assert len(evaluation_embs) == len(evaluation_labels)
assert len(probe_embs) == len(probe_labels)
有了这两个集合,我们现在准备使用 Sklearn 库中实现的流行的无监督学习方法来构建我们的人脸识别系统。
创建人脸识别系统
我们 使用 评估嵌入 来训练最近邻模型 。这是一种用于无监督最近邻学习的巧妙技术。
最近邻法允许我们找到距离新点最近的预定义数量的训练样本。
注意:通常,距离可以是任何度量,例如欧几里得、曼哈顿、余弦、 Minkowski 等。
# Nearest neighbour learning method
nn = NearestNeighbors(n_neighbors=3, metric="cosine")
nn.fit(X=evaluation_embs)
# save the model to disk
filename = 'faceID_model.pkl'
with open(filename, 'wb') as file:
pickle.dump(nn, file)
# some time later...
# load the model from disk
# with open(filename, 'rb') as file:
# pickle_model = pickle.load(file)
因为我们正在实施一种 无监督 学习方法,请注意我们没有传递任何标签,即 evaluation_label
该 fit
方法。我们在这里所做的就是将评估集中的人脸嵌入映射到潜在空间中。
基于邻居的方法被称为 非泛化机器学习方法,因为它们只是“记住”其所有训练数据(可能转换为快速索引结构,例如球树或 KD 树)。
推理
对于每个新的探测图像,我们可以通过使用搜索其前k 个 邻居的 nn.neighbours()
方法来发现它是否存在于评估集中 。例如,
# Example inference on test image
dists, inds = nn.kneighbors(X = probe_img_emb.reshape(1,-1),
n_neighbors = 3,
return_distances = True
)
如果inds
评估集中返回索引 ( )处的标签与探测图像的原始/真实标签完美匹配,那么我们知道我们已经在验证系统中找到了我们的脸。
我们已将上述逻辑包装到 print_ID_results()
方法中。它将探针图像路径、评估集标签和verbose
用于指定是否应显示详细结果的标志作为输入 。
def print_ID_results(img_fpath: str, evaluation_labels: np.ndarray, verbose: bool = False):
img = Image.open(img_fpath)
img_emb = app.get(np.asarray(img))[0].embedding
# get pred from KNN
dists, inds = nn.kneighbors(X=img_emb.reshape(1,-1), n_neighbors=3, return_distance=True)
# get labels of the neighbours
pred_labels = [evaluation_labels[i] for i in inds[0]]
# check if any dist is greater than 0.5, and if so, print the results
no_of_matching_faces = np.sum([1 if d <=0.6 else 0 for d in dists[0]])
if no_of_matching_faces > 0:
print("Matching face(s) found in database! ")
verbose = True
else:
print("No matching face(s) not found in database!")
# print labels and corresponding distances
if verbose:
for label, dist in zip(pred_labels, dists[0]):
print(f"Nearest neighbours found in the database have labels {label} and is at a distance of {dist}")
这里有几件重要的事情需要注意:
inds
包含evaluation_labels
集合中最近邻居的索引 (第 6 行)。例如,inds = [[2,0,11]]
在 index=2 处的手段标签evaluation_labels
被发现最接近探测图像,其次是在 index = 0 处的标签。由于对于 任何 图像,
nn.neighbors
将返回非空响应,如果 返回的距离小于或等于 0.6(第 12 行),我们必须仅将这些结果视为面部 ID 匹配 。(PS 0.6 的选择完全是任意的)。
例如,继续上面的例子 whereinds = [[2,0, 11]]
and let's saydists = [[0.4, 0.6, 0.9]]
,我们只会将 index=2 和 index = 0 (inevaluation_labels
)处的标签 视为真正的人脸匹配,因为dist
最后一个邻居的 太大以至于它不是真正的比赛。
作为快速检查,让我们看看当我们输入婴儿的脸作为探测图像时系统的响应。正如预期的那样,它显示没有找到匹配的面孔!但是,我们设置 verbose
为 True,因此我们可以在数据库中看到其虚假 最近邻居的标签和距离 ,所有这些看起来都很大(> 0.8)。

评估人脸识别系统
测试该系统是否有用的方法之一是查看 前 k 个邻居中存在多少 相关结果。相关结果是真实标签与预测标签匹配的结果。该度量通常称为 k处的精度,其中 k 是预先确定的。
例如,从探针集中选择一个图像(或者更确切地说是一个嵌入),其真实标签为“subject01”。如果此图像pred_labels
返回 的前两个 nn.neighbors
是 ['subject01', 'subject01'],则表示 k (p@k) 处的精度 k=2
为 100%。类似地,如果只有一个值 pred_labels
等于“subject05”,p@k 将是 50%,依此类推……
dists, inds = nn.kneighbors(X=probe_embs_example.reshape(1, -1),
n_neighbors=2,
return_distance=True)
pred_labels = [evaluation_labels[i] for i in inds[0] ]
pred_labels
----- OUTPUT ------
['002', '002']
让我们继续计算p@k
整个探针集的平均值 :
# inference on probe set
dists, inds = nn.kneighbors(X=probe_embs, n_neighbors=2, return_distance=True)
# calculate avg p@k
p_at_k = np.zeros(len(probe_embs))
for i in range(len(probe_embs)):
true_label = probe_labels[i]
pred_neighbr_idx = inds[i]
pred_labels = [evaluation_labels[id] for id in pred_neighbr_idx]
pred_is_labels = [1 if label == true_label else 0 for label in pred_labels]
p_at_k[i] = np.mean(pred_is_labels)
p_at_k.mean()------ 输出 --------0.9
