




点击蓝字关注这个神奇的公众号~

MongoDB安装与配置
Nosql简介
什么是NoSQL?
NoSQL指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
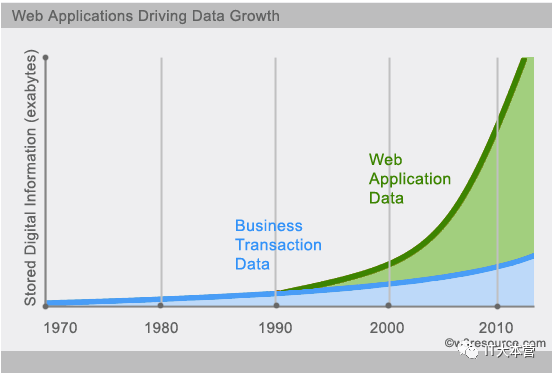
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
为什么使用NoSQL ?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
实例
社会化关系网:
Each record: UserID1, UserID2
Separate records: UserID, first_name,last_name, age, gender,...
Task: Find all friends of friends of friends of ... friends of a given user.
Wikipedia 页面 :
Large collection of documents
Combination of structured and unstructured data
Task: Retrieve all pages regarding athletics of Summer Olympic before 1950.
RDBMS vs NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
NoSQL 简史
NoSQL一词最早出现于1998年,是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。2009年,Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论[2],来自Rackspace的Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。2009年在亚特兰大举行的"no:sql(east)"讨论会是一个里程碑,其口号是"select fun, profit from real_world where relational=false;"。因此,对NoSQL最普遍的解释是"非关联型的",强调Key-Value Stores和文档数据库的优点,而不是单纯的反对RDBMS。
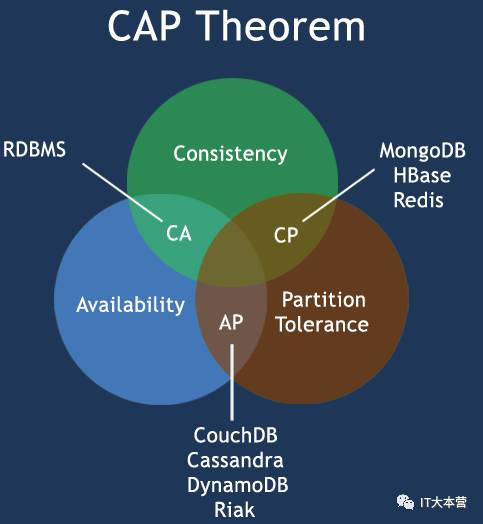
CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency) (所有节点在同一时间具有相同的数据)
可用性(Availability) (保证每个请求不管成功或者失败都有响应)
分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:
一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
NoSQL的优点/缺点
优点:
高可扩展性
分布式计算
低成本
架构的灵活性,半结构化数据
没有复杂的关系
缺点:
没有标准化
有限的查询功能(到目前为止)
最终一致是不直观的程序
NoSQL 数据库分类
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
Basically Availble --基本可用
Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
Eventual Consistency --最终一致性 最终一致性, 也是是 ACID 的最终目的。
谁在使用
现在已经有很多公司使用了 NoSQL:
Google
Facebook
Mozilla
Adobe
Foursquare
LinkedIn
Digg
McGraw-Hill Education
Vermont Public Radio
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
mongoDB的特点:
1.MongoDB的提供了一个面向文档存储,操作起来比较简单和容易。
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
2.你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
3.如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上 这就是所谓的分片。
4.Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
5.MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
6.Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
7.Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
8.Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
9.GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
10.MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
11.MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
12.MongoDB安装简单。
MongoDB 应用案例
下面列举一些公司MongoDB的实际应用:
Craiglist上使用MongoDB的存档数十亿条记录。
FourSquare,基于位置的社交网站,在Amazon EC2的服务器上使用MongoDB分享数据。
Shutterfly,以互联网为基础的社会和个人出版服务,使用MongoDB的各种持久性数据存储的要求。
bit.ly, 一个基于Web的网址缩短服务,使用MongoDB的存储自己的数据。
spike.com,一个MTV网络的联营公司, spike.com使用MongoDB的。
Intuit公司,一个为小企业和个人的软件和服务提供商,为小型企业使用MongoDB的跟踪用户的数据。
sourceforge.net,资源网站查找,创建和发布开源软件免费,使用MongoDB的后端存储。
etsy.com ,一个购买和出售手工制作物品网站,使用MongoDB。
纽约时报,领先的在线新闻门户网站之一,使用MongoDB。
CERN,著名的粒子物理研究所,欧洲核子研究中心大型强子对撞机的数据使用MongoDB。
MongoDB 提供了 linux 各发行版本 64 位的安装包,你可以在官网下载安装包。
下载地址:https://www.mongodb.com/download-center#community
下载完安装包,并解压 tgz(以下演示的是 64 位 Linux上的安装) 。
#curl -O 下载mongodb包
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz
#tar zxf mongodb-linux-x86_64-3.0.6.tgz
//解压包
#mv mongodb-linux-x86_64-3.0.6 /usr/local/mongodb
//移动mongodb到/usr/local/
#ln -s /usr/local/mongodb/bin/* usr/local/bin/
MongoDB 的可执行文件位于 bin 目录下,所以可以将其添加到 PATH 路径中:
#export PATH=/usr/local/mongodb/bin:$PATH
创建数据库目录
MongoDB的数据存储在data目录的db目录下,但是这个目录在安装过程不会自动创建,所以你需要手动创建data目录,并在data目录中创建db目录。
以下实例中我们将data目录创建于根目录下(/)。
注意:/data/db 是 MongoDB 默认的启动的数据库路径(--dbpath)。
#mkdir -p data/db
命令行中运行 MongoDB 服务
你可以再命令行中执行mongo安装目录中的bin目录执行mongod命令来启动mongdb服务。
注意:如果你的数据库目录不是/data/db,可以通过 --dbpath 来指定。
#cd usr/local/mongodb/bin
# ./mongod

MongoDB后台管理 Shell
如果你需要进入MongoDB后台管理,你需要先打开mongodb装目录的下的bin目录,然后执行mongo命令文件。
MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。
当你进入mongoDB后台后,它默认会链接到 test 文档(数据库):

由于它是一个JavaScript shell,您可以运行一些简单的算术运算:

现在让我们插入一些简单的数据,并对插入的数据进行检索:

第一个命令将数字 10 插入到 runoob 集合的 x 字段中。
MongoDb web 用户界面
MongoDB 提供了简单的 HTTP 用户界面。 如果你想启用该功能,需要在启动的时候指定参数 --rest 。
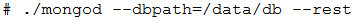
MongoDB 的 Web 界面访问端口比服务的端口多1000。
如果你的MongoDB运行端口使用默认的27017,你可以在端口号为28017访问web用户界面,
即地址为:http://localhost:28017。
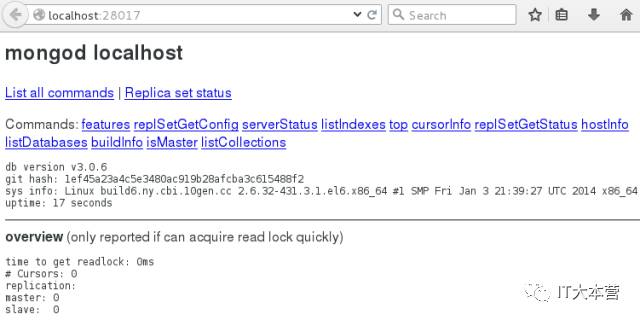
创建数据库:

如果你想查看所有数据库,可以使用 show dbs 命令:
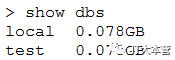
可以看到,我们刚创建的数据库 zc并不在数据库的列表中, 要显示它,我们需要向 zc数据库插入一些数据。
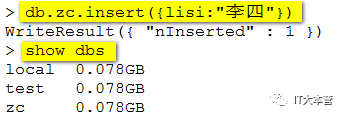
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
删除数据库
MongoDB 删除数据库的语法格式如下:
db,dropDatabase()
删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
例如:
以下实例我们删除了数据库 zc。
首先,查看所有数据库:
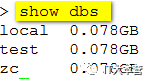
接下来我们切换到数据库 zc:
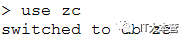
执行删除命令:

最后,我们再通过 show dbs 命令数据库是否删除成功:

创建集合
创建集合的同时会生成一个系统索引
格式:db.createCollection("集合名")
查看集合:
>show collection 或者 show tables

删除集合
集合删除语法格式如下:
db.collection.drop()
以下实例删除了 zc数据库中的集合 site:

MongoDB数据备份
在Mongodb中我们使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中。
mongodump命令可以通过参数指定导出的数据量级转存的服务器。
mongodump命令脚本语法如下:
>mongodump -h dbhost -d dbname -o dbdirectory
-h:
MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:
需要备份的数据库实例,例如:test
-o:
备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据
MongoDB数据恢复
mongodb使用 mongorestore 命令来恢复备份的数据。
语法
mongorestore命令脚本语法如下:
>mongorestore -h
--host <:port>, -h <:port>:
MongoDB所在服务器地址,默认为: localhost:27017
--db , -d :
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。
你不能同时指定
--dir:
指定备份的目录
你不能同时指定
MongoDB 监控
在你已经安装部署并允许MongoDB服务后,你必须要了解MongoDB的运行情况,并查看MongoDB的性能。这样在大流量得情况下可以很好的应对并保证MongoDB正常运作。
MongoDB中提供了mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
mongotop
mongotop也是mongodb下的一个内置工具,mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongotop命令,如下所示:
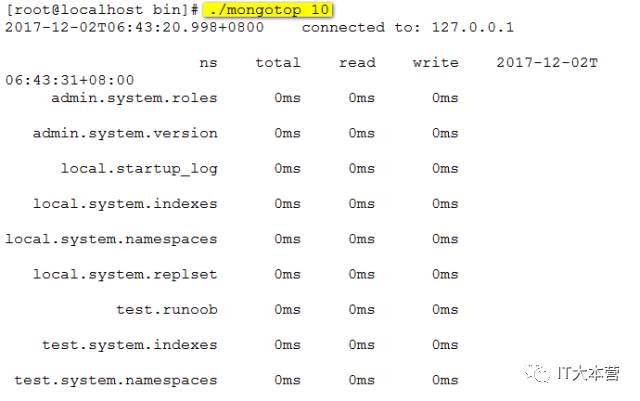
后面的10是
报告每个数据库的锁的使用中,使用mongotop - 锁,这将产生以下输出:
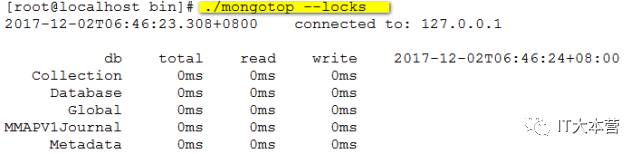
输出结果字段说明:
ns:
包含数据库命名空间,后者结合了数据库名称和集合。
db:
包含数据库的名称。名为 . 的数据库针对全局锁定,而非特定数据库。
total:
mongod花费的时间工作在这个命名空间提供总额。
read:
提供了大量的时间,这mongod花费在执行读操作,在此命名空间。
write:
提供这个命名空间进行写操作,这mongod花了大量的时间。
mongostat 命令
mongostat是mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongostat命令,如下所示:

MongoDB 插入文档
本章节中我们将向大家介绍如何将数据插入到MongoDB的集合中。
文档的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON。
插入文档:
格式:
>db.COLLECTION_NAME.insert(document)

>db.zc.find()//查看已插入的文档

我们也可以将数据定义为一个变量,如下所示:
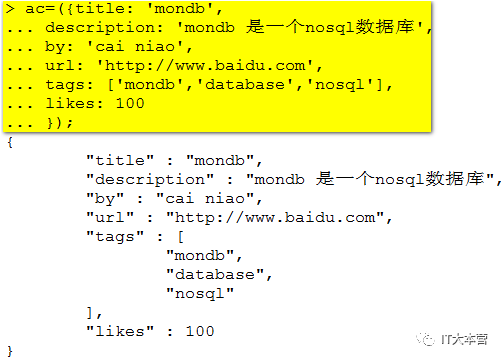
执行插入操作:
插入单条数据
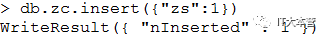
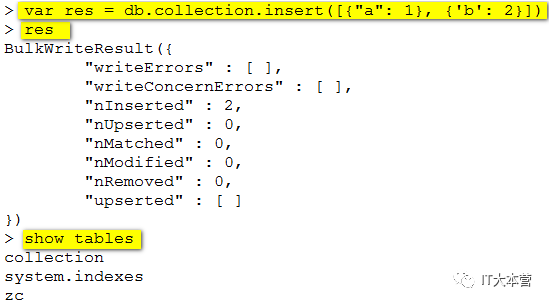
插入多条数据:
查询文档:
格式:db.文档名称.find()
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db,文档名称.find().pretty()


MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
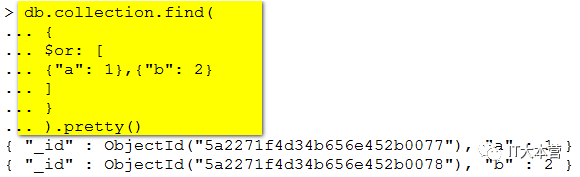
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where key = value AND (key = value OR key = value)'
>db.col.find({"key": value, $or: [{"key": value},{"key": value}]}).pretty()
MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
MongoDB 删除文档
我们已经学习了MongoDB中如何为集合添加数据和更新数据。在本章节中我们将继续学习MongoDB集合的删除。
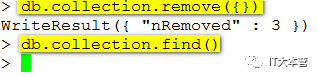
MongoDB remove()函数是用来移除集合中的数据。
MongoDB数据更新可以使用update()函数。在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
只删除一条:
db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
删除集合下全部文档:
1、drop
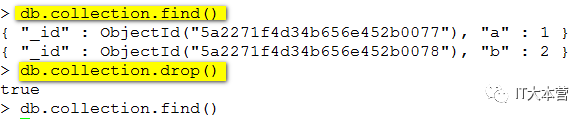
2、remove

MongoDB 更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
update() 方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
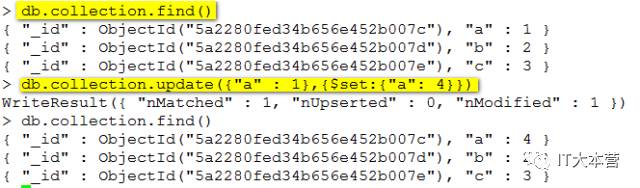
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。



更多实例
只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
全部添加加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
更多连接实例
连接本地数据库服务器,端口是默认的。
mongodb://localhost
使用用户名fred,密码foobar登录localhost的admin数据库。
mongodb://fred:foobar@localhost
使用用户名fred,密码foobar登录localhost的baz数据库。
mongodb://fred:foobar@localhost/baz
连接 replica pair, 服务器1为example1.com服务器2为example2。
mongodb://example1.com:27017,example2.com:27017
连接 replica set 三台服务器 (端口 27017, 27018, 和27019):
mongodb://localhost,localhost:27018,localhost:27019
连接 replica set 三台服务器, 写入操作应用在主服务器 并且分布查询到从服务器。
mongodb://host1,host2,host3/?slaveOk=true
直接连接第一个服务器,无论是replica set一部分或者主服务器或者从服务器。
mongodb://host1,host2,host3/?connect=direct;slaveOk=true
当你的连接服务器有优先级,还需要列出所有服务器,你可以使用上述连接方式。
安全模式连接到localhost:
mongodb://localhost/?safe=true
以安全模式连接到replica set,并且等待至少两个复制服务器成功写入,超时时间设置为2秒。
mongodb://host1,host2,host3/?safe=true;w=2;wtimeoutMS=2000
用户授权:
可读写的权利

roles:指定用户的角色,可以用一个空数组给新用户设定空角色;在roles字段,可以指定内置角色和用户定义的角色。role里的角色可以选:
Built-In Roles(内置角色):1. 数据库用户角色:read、readWrite;2. 数据库管理角色:dbAdmin、dbOwner、userAdmin;3. 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;4. 备份恢复角色:backup、restore;5. 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase6. 超级用户角色:root // 这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)7. 内部
Read:允许用户读取指定数据库readWrite:允许用户读写指定数据库dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profileuserAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户clusterAdmin:只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。readAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读权限readWriteAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读写权限userAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限dbAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限。root:只在admin数据库中可用。超级账号,超级权限角色:__system
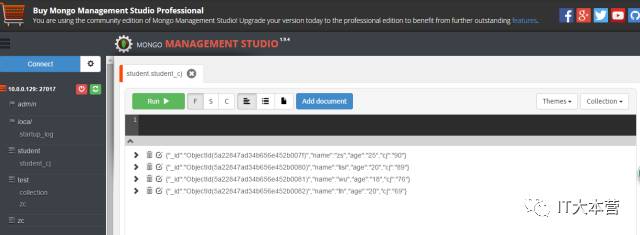
MongoDB 管理工具:
Mongo Management Studio
windows版本:
Linux版本:
微信号:Zhuchao0915
加关注

点击“阅读原文”
