




 卡片,关注 InsideMySQL
卡片,关注 InsideMySQLYet at its core, GitHub.com remained built around one main database cluster (called mysql1
) that housed a large portion of the data used by core GitHub features, like user profiles, repositories, issues, and pull requests.
更为重要的是,从产品角度看,分布式数据库并不是一种用户体验非常好的产品。
分布式数据库,如 Spanner、OceanBase、TiDB 等注定不会成为未来 主流的 OLTP关系型数据库。
by 破产码农 2021年10月12日
回到 Github 数据库架构升级案例来看,Github 选择的是对数据库进行垂直拆分。
Github 首先对库表进行梳理,哪些表是随事务一起被访问,然后将其映射到一个虚拟库(Schema Domain)中,以便后期做真实的拆分。
接着编写了两个 SQL Linter 的 SQL 检查工具,以便在开发和测试环境中发现目前存在的跨域(Cross Schema Domain)访问 SQL,然后交由开发人员进行改写。
上述 SQL Linter 检查工具会自动向跨域的 SQL 添加一种特别的注释:/*cross-schema-domain-query-exempted */
这样就能在持续集成环境中确保后续发布的版本没有 SQL 跨域问题。
由于做了垂直拆分,为实现对上层业务访问的透明性,Github 使用了 Vitess 中间件,并使用 Vertical sharding 功能屏蔽下面的数据拆分。
Vitess 在国内并不怎么流行,其架构如下所示,感兴趣的同学可以看下:
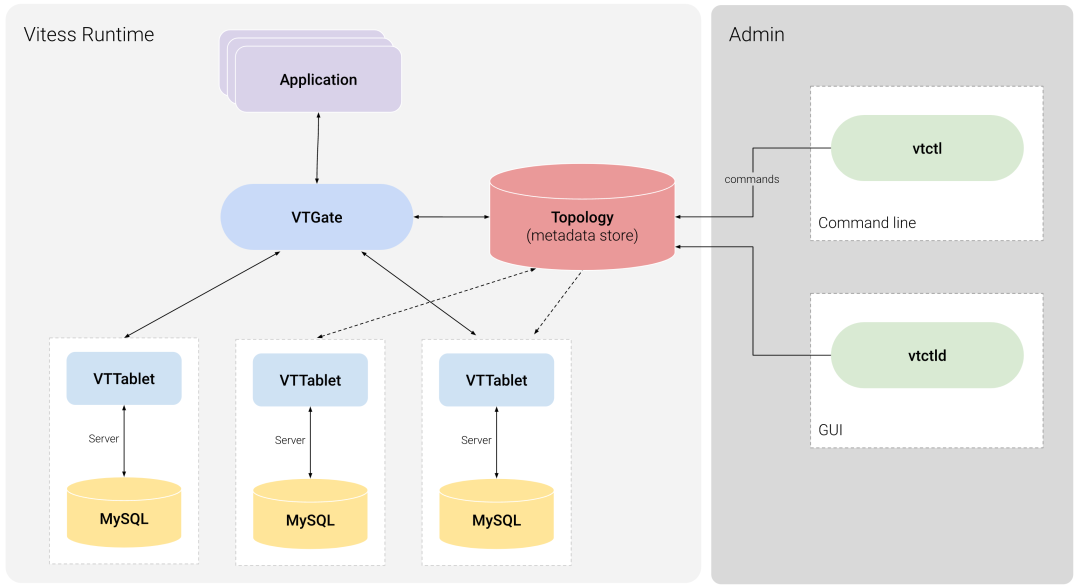
对于实际数据的垂直拆分,Github 通过 MySQL 原生的复制技术。
最终,在经过这次数据库的架构升级后,Github 的核心数据库取得了如下的成果:
2019年,mysql1 集群 QPS 为 95W,主节点(Master) QPS 5W;从节点(Slave)的读取 QPS 为 90W;读写比约为 20 : 1。
2021年,mysql1 集群 QPS 为 120W,主节点(Master) QPS 7.5W;从节点(Slave)的读取 QPS 为 112.5W;读写比差不多依然为 20 : 1。
当前硬件技术发展迅猛,百核CPU、半T内存、千兆IOPS都已唾手可得。
加之关系型数据库新版本都在对多核、超速硬盘进行优化。
通过优化,单实例数据库 QPS 达到十数万并不是难事。
对于 Github 的数据库架构改造来说,我相信当然可以设计出一个分布式的 MySQL 架构,也可以设计一个 Redis + MySQL 的架构。
但上述两者的设计,对业务侵入巨大,对程序的限制变多,后期运营成本也是巨大。
真正好的架构设计应该大道至简,做减法而不是不断做加法。
所以,技术应该是服务于业务,而不是让业务去适应技术。
你说是不是呢?欢迎留言。
BTW,想要观看原文分享的同学,请点击下方的原文阅读。

直播预告



刚刚,我成功复活了 MySQL 祖先版本!

用 VSCode 编译和调试 MySQL,每个 DBA 都应 get 的小技能
VScode,yyds!用VScode编译和调试MySQL

老盖除名 Oracle ACE ,旧时代的终结!

收藏!最新《MySQL数据库开发设计规范》
