




背景
前面文章
埋头过坎,公众号:埋头过坎这就是k8s系列之六(cert-manager升级)
介绍了cert-manager的安装及升级到稳定版本的过程, 并通过一个测试版本的Issuer验证了基本功能。cert-manager的强大其实体现在可以通过let's encrypt服务自动地更新证书, 无论是从保障服务的稳定性还是提高服务运维的效率上都是很有吸引力的。 笔者打算给datalab k8s集群引入这一机制, 然而整个过程并不是很顺畅, 遇到了一些诡异的问题, 还好一路下来,解决了各种问题好, 最后成功地部署了服务。下文将介绍具体的问题和排除故障的过程。

安装步骤
基于let's encrypt颁发和更新证书的服务的过程主要有两步, 一是创建描述clusterissuers资源文件, 二是应用创建该服务,如下:
# step1: 创建资源文件, 主要内容看注释[root@host01 cert-manager]# cat acme-v1.1.0.yamlapiVersion: cert-manager.io/v1 # 所使用的API版本kind: ClusterIssuer # 证书颁布者的类型,有issuer及cluster issuermetadata:name: letsencrypt-staging # 颁布者的名称spec:acme: # ACME协议配置内容# You must replace this email address with your own.# Let's Encrypt will use this to contact you about expiring# certificates, and issues related to your account.email: xxx@gmail.com # 用来获取证书更新的邮箱# 服务器地址,测试阶段使用staging, 生产阶段prod, https://acme-v01.api.letsencrypt.org/directoryserver: https://acme-staging-v02.api.letsencrypt.org/directoryprivateKeySecretRef:# Secret resource that will be used to store the account's private key.name: letsencrypt-staging # secret用于存储帐户的私钥# Add a single challenge solver, HTTP01 using nginxsolvers:- selector: {}http01: # 使用http01, 另一种是dns01ingress:class: nginx
# step2: 创建资源kubectl apply -f acme-v1.1.0.yaml
查看结果主要是通过看创建的clusterissuer的状态,如下:
[root@host01 ~]# kubectl get clusterissuerNAME READY AGEletsencrypt-staging False 18h
故障分析及对策
很不幸, 没有奇迹发生, 状态为False。 什么原因导致了异常呢?下面是故障排除的几个步骤:
1. 是不是配置文件写错了?2. 是不是letsencrypt-prod、letsencrypt-staing的原因?3. 是不是cert-manager的原因?=> 直观因素, 升级, 重启。4. 是不是nodelocaldns、coredns的原因? => 检查集群DNS配置、日志、重启。从错误日志中推测的原因。5. 是不是宿主机node节点/etc/resolv.conf中的search的原因?=> Github issue给的思路。6. 是不是宿主机代理的原因?=> 对比测试, 通过代理, 不通过代理7. 去掉代理了,还是不行?是什么原图呢?=> 对照测试, 本集群及其它 拥有外网的机器对比8. 还想保留代理, 同时又希望自动签证服务可以正常, 有什么办法呢?=> 优化方案9. 终于好了, works OK!
step 1, 考虑的是配置文件是不是哪里写错了,但整个配置项需要自己填写的就只有接受邮件通知那一项, 一开始采用的是国内的邮箱, 后面试了gmail, 仍然not work!
step 2, 留意到了lesencrpyt-prod及lesencrypt-staging的区别, 一开始的时候是采用的lesencrpyt-prod, 这个有访问频率等各种限制, 就替换成lesencrypt-staging, 仍然not work! 查看clusterisser的详情如下:
[root@host01 ~]# kubectl describe clusterissuersName: letsencrypt-staging # 名称Namespace: # 没有指定命名空间, defaultLabels: <none> # 没有指定标签Annotations: <none> # 没有指定注解/属性API Version: cert-manager.io/v1 # 用来创建的API版本Kind: ClusterIssuer # 类型Metadata: # 元数据Creation Timestamp: 2020-12-04T07:27:04Z # 创建时间Generation: 1Managed Fields: # 管理字段API Version: cert-manager.io/v1 # API版本Fields Type: FieldsV1 # 字段类型fieldsV1: # 字段具体信息f:metadata: # 字段元数据f:annotations: # 字段属性.:f:kubectl.kubernetes.io/last-applied-configuration:f:spec: # 字段清单.:f:acme: # acme协议.:f:email: # 邮箱f:privateKeySecretRef: # 私钥对应的secret.:f:name:f:server: # 服务器f:solvers: # 解析器Manager: kubectl-client-side-apply # 管理者Operation: Update # 操作为更新Time: 2020-12-04T07:27:04ZAPI Version: cert-manager.io/v1Fields Type: FieldsV1fieldsV1:f:status:.:f:acme:f:conditions:Manager: controllerOperation: UpdateTime: 2020-12-04T07:27:14ZResource Version: 1952054Self Link: apis/cert-manager.io/v1/clusterissuers/letsencrypt-stagingUID: cb385b83-e463-4c85-a66a-42e4acbcd8bdSpec: # 具体清单Acme: # ACME协议Email: xxx@gmail.com # 邮箱,用来接收通知Preferred Chain:Private Key Secret Ref: # 私钥对应的SecretName: letsencrypt-staging # secret名称Server: https://acme-staging-v02.api.letsencrypt.org/directory # CA服务器Solvers: # 解析器http01: # 采用http01方法, 另外一种是dns01Ingress: #Class: nginx # ingress类型为nginxSelector: # 选择器Status: # 状态Acme:Conditions:Last Transition Time: 2020-12-04T07:27:14Z # 最后传输时间Message: Failed to verify ACME account: context deadline exceeded # 失败信息Reason: ErrRegisterACMEAccount # 原因Status: False # 状态Type: Ready # 状态类型Events: # 事件Type Reason Age From Message---- ------ ---- ---- -------Warning ErrInitIssuer 37m (x486 over 41h) cert-manager Error initializing issuer: context deadline exceededWarning ErrVerifyACMEAccount 71s (x493 over 41h) cert-manager Failed to verify ACME account: context deadline exceeded
从clusterissuer的详情的status及events字段可以看到, 资源创建失败了, 具体的错误信息为" Failed to verify ACME account: context deadline exceeded", 错误原因为“ErrRegisterACMEAccount”。
从events中的可以看到, 这些信息的来源为cert-manager服务。
step 3, 开始排查cert-manager的日志。 关键的日志如下:
E1206 01:07:54.758810 1 setup.go:218] cert-manager/controller/clusterissuers "msg"="failed to verify ACME account" "error"="context deadline exceeded" "related_resource_kind"="Secret" "related_resource_name"="letsencrypt-staging" "related_resource_namespace"="cert-manager" "resource_kind"="ClusterIssuer" "resource_name"="letsencrypt-staging" "resource_namespace"="" "resource_version"="v1"E1206 01:07:54.758941 1 sync.go:83] cert-manager/controller/clusterissuers "msg"="error setting up issuer" "error"="context deadline exceeded" "resource_kind"="ClusterIssuer" "resource_name"="letsencrypt-staging" "resource_namespace"="" "resource_version"="v1"E1206 01:07:54.759046 1 controller.go:158] cert-manager/controller/clusterissuers "msg"="re-queuing item due to error processing" "error"="context deadline exceeded" "key"="letsencrypt-staging"W1206 01:10:39.663733 1 warnings.go:67] extensions/v1beta1 Ingress is deprecated in v1.14+, unavailable in v1.22+; use networking.k8s.io/v1 IngressI1206 01:12:54.759936 1 setup.go:178] cert-manager/controller/clusterissuers "msg"="ACME server URL host and ACME private key registration host differ. Re-checking ACME account registration" "related_resource_kind"="Secret" "related_resource_name"="letsencrypt-staging" "related_resource_namespace"="cert-manager" "resource_kind"="ClusterIssuer" "resource_name"="letsencrypt-staging" "resource_namespace"="" "resource_version"="v1"
相关的日志分析如下:
第一条日志的msg信息刚好是describe clusterissuers中status显示的, 推测应该是由cert-manager返回给clusterissuers的, 这里要留意的是, 提示关联的资源类型为secret, 名称为 "letsencrypt-staging", 这个是在创建clusterissuers时指定的用于存储私钥的secret。第二条日志显示重新入队, 推测是准备下次重试第三条日志关于Ingress api版本的warning, 可以忽略第四条日志msg提示AMCE服务器URL的主机与ACME私钥注册的主机不一样。需要重新检查ACME帐户注册。相关资源还是上面的secret。推测这一条可能是关键的日志,需要进一步展开
到这里, 最直接的做法是, 先重启一下cert-manager的服务, 试了重启, 查看日志, 依然not work! 错误依然存在。
此时怀疑是不是pod内的服务访问外网异常, 参考网上的文章( https://www.thinbug.com/q/57058270) 排查是不是DNS的问题。
step 4, 集群采用的是core-dns + nodelocaldns的架构,先是查看了core-dns、 nodelocaldns的pod及服务状态及相关的日志, 没有发现明显的问题, 按照上述文章, 创建了一个辅助调试dns的pod, 如下:
kubectl run -i -t busybox --image=radial/busyboxplus:curl --restart=Never
同时,查看pod内的DNS相关的配置并做普通测试,
[ root@busybox:/ ]$ cat etc/resolv.confnameserver ip01search default.svc.cluster.local svc.cluster.local cluster.local xxx.comoptions ndots:5[ root@busybox:/ ]$ nslookup kubernetes.defaultServer: ip02Address 1: ip03Name: kubernetes.defaultAddress 1: ip04 kubernetes.default.svc.cluster.local[ root@busybox:/ ]$ ping 8.8.8.8PING 8.8.8.8 (8.8.8.8): 56 data bytes^C--- 8.8.8.8 ping statistics ---3 packets transmitted, 0 packet
可以看到/etc/resolv.conf看起来是正常的, 也能解析内部地名称, 只是这里ping 8.8.8.8没有连通, 有些异常(没有进一步引起重视)。 又试了一下在pod内访问let's encrypt的服务,如下:
# 域名解析, 正确[ root@busybox:/ ]$ nslookup acme-staging-v02.api.letsencrypt.orgServer: ip1Address 1: ip2Name: acme-staging-v02.api.letsencrypt.orgAddress 1: 2606:4700:60:0:f41b:d4fe:4325:6026Address 2: 172.65.46.172# curl访问不通[ root@busybox:/ ]$ curl https://acme-staging-v02.api.letsencrypt.org/directorycurl: (7) Failed to connect to acme-staging-v02.api.letsencrypt.org port 443: Connection timed out[ root@busybox:/ ]$# ping不通[ root@busybox:/ ]$ ping 172.65.46.172PING 172.65.46.172 (172.65.46.172): 56 data bytes^C--- 172.65.46.172 ping statistics ---9 packets transmitted, 0 packets received, 100% packet loss
从上面的结果可以看到DNS解析出来的IP地址是正确的, 但是curl及ping都失败了。 非常诡异。
step 5, 又回去仔细看了cert-manager的错误日志, 其中有一点更具体的信息, 如下“ACME server URL host and ACME private key registration host differ. Re-checking ACME account registration”,字面上看是ACME的服务器URL的主机跟ACME私钥注册的主机不一样, 这个具体信息看起来是可以引导找出正确的解决方案的, 果然, 很幸运地从cert-manager的github上的issue找到两个相关的,答案部分截图如下:
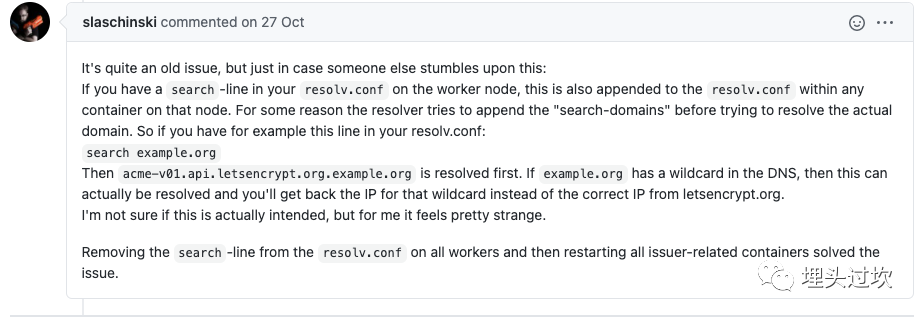
来自 这个issue
cert-manager issue:
https://github.com/jetstack/cert-manager/issues/641
, 基本意思就是resolv.conf里面的search 那行可能会导致解析出来两个不同的IP, 另一篇文章的相关内容如下:

来自这个issue
cert-manager issue:
https://github.com/jetstack/cert-manager/issues/3394
step 6, 很可惜, 依然not work! 在这里有些卡住了。想着pod内部curl不通let's encrypt的服务器, 那么在node节点宿主机上呢?试一下:
[root@host03 ~]# curl -v https://acme-staging-v02.api.letsencrypt.org/director* About to connect() to proxy ip01 port port01 (#0)* Trying ip01...* Connected to ip01 (ip01) port port01 (#0)Establish HTTP proxy tunnel to acme-staging-v02.api.letsencrypt.org:443▽ Proxy auth using Basic with user 'xxx'> CONNECT acme-staging-v02.api.letsencrypt.org:443 HTTP/1.1> Host: acme-staging-v02.api.letsencrypt.org:443> Proxy-Authorization: Basic enVvemVjaGVuZzp6dW96ZWNoZW5nMzIx> User-Agent: curl/7.29.0> Proxy-Connection: Keep-Alive>< HTTP/1.0 200 Connection established<* Proxy replied OK to CONNECT request* Initializing NSS with certpath: sql:/etc/pki/nssdb* CAfile: etc/pki/tls/certs/ca-bundle.crtCApath: none* SSL connection using TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384* Server certificate:* subject: CN=acme-staging.api.letsencrypt.org* start date: Dec 03 21:42:20 2020 GMT* expire date: Mar 03 21:42:20 2021 GMT* common name: acme-staging.api.letsencrypt.org* issuer: CN=R3,O=Let's Encrypt,C=US> GET director HTTP/1.1> User-Agent: curl/7.29.0> Host: acme-staging-v02.api.letsencrypt.org> Accept: */*>< HTTP/1.1 404 Not Found< Server: nginx< Date: Sun, 06 Dec 2020 04:17:53 GMT< Content-Type: text/plain; charset=utf-8< Content-Length: 19< Connection: keep-alive< X-Content-Type-Options: nosniff<404 page not found* Connection #0 to host ip01 left intact
虽然返回404, 但还是连接成功了。仔细看了下输出, 好像不是直连的, 而是通过代理连接的, 想起之前使用kubespray安装集群时, 为了解决gcr.io等墙外站点无法访问问题, 给整个集群都配置了proxy, 莫非是因为走了一层proxy的原因,使得上面出现了ACME的服务器URL的主机跟ACME私钥注册的主机不一样。有思路, 赶紧验证。把整个集群的机器的proxy都取消了, 然后查看cert-manager的日志kubectl logs -n cert-manager cert-manager-xxx -f , 发现依然not work, 错误还是在。
step 7, 代理去掉了,可还是不行, 是什么原因呢?这里找了另外一台拥有访问外网权限的机器, 试着连通let's encrypt的服务,如下:
[root@hostxx ~]# curl -v https://acme-staging-v02.api.letsencrypt.org/director* About to connect() to acme-staging-v02.api.letsencrypt.org port 443 (#0)* Trying 172.65.46.172... connected* Connected to acme-staging-v02.api.letsencrypt.org (172.65.46.172) port 443 (#0)* Initializing NSS with certpath: sql:/etc/pki/nssdb* CAfile: etc/pki/tls/certs/ca-bundle.crtCApath: none* SSL connection using TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384* Server certificate:* subject: CN=acme-staging.api.letsencrypt.org* start date: Nov 30 19:24:59 2020 GMT* expire date: Feb 28 19:24:59 2021 GMT* common name: acme-staging.api.letsencrypt.org* issuer: CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US> GET director HTTP/1.1> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.44 zlib/1.2.3 libidn/1.18 libssh2/1.4.2> Host: acme-staging-v02.api.letsencrypt.org> Accept: */*>< HTTP/1.1 404 Not Found< Server: nginx< Date: Sun, 06 Dec 2020 06:31:25 GMT< Content-Type: text/plain; charset=utf-8< Content-Length: 19< Connection: keep-alive< X-Content-Type-Options: nosniff<404 page not found
发现服务是可以连接成功的, 但在去掉了代理的node上访问是超时的, 如下:
[root@host03 ~]# curl -v https://acme-staging-v02.api.letsencrypt.org/director* About to connect() to acme-staging-v02.api.letsencrypt.org port 443 (#0)* Trying 172.65.46.172...* Connection timed out* Trying 2606:4700:60:0:f41b:d4fe:4325:6026...* After 85020ms connect time, move on!* Failed connect to acme-staging-v02.api.letsencrypt.org:443; Operation now in progress* Closing connection 0curl: (7) Failed connect to acme-staging-v02.api.letsencrypt.org:443; Operation now in progress
看起来是去掉代理后, 访问外网异常了。又拿jd.com, qq.com等做了下对比测试了一下, 果然是异常了。
接下来是修复外网访问功能, 笔者所有的集群是通过隧道连接到专有的外网访问集群来实现外网访问功能的, 修复后路由表中多了一条隧道相关的路由,如下:
[root@host03 ~]# route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 0.0.0.0 0.0.0.0 U 0 0 0 natgre
此时查看, clusterissuer的状态, 终于变为正常了, 如下:
[root@host01 cert-manager]# kubectl get clusterissuersNAME READY AGEletsencrypt-staging True 5h39m
step 8, 服务终于正常了,但考虑到平时拉取镜像等还是需要proxy的, 如何保持proxy情况下, 还可以保持cert-manager服务的正常工作呢。方法很简单, 通过nslookup解析出对应的ip地地址, 加到no_porxy列表中就可以了。把proxy加回来了, 验证了一下, ok.
step 9, 终于好了, works OK!
总结
k8s本质是个微型的IDC, 融合了很多网络、存储、计算等概念, 真正要用好k8s, 离不开这些基础功的扎实。即使经常看似简单的通过资源定义或者helm来安装相应的应用, 但在具体的环境下也有可能遇到各种各样的问题, 而这些问题在网上不一定有答案, 前人也不一定遇见过, 这时候就需要回归基础知识, 一步步地定位、推理问题并加以解决。
