




提起联邦学习, 首先是Google的横向联邦学习项目,可以从下面的图片了解一下:

这是从Google AI主页引用的图片, 图中简单地说了联邦学习是使用设备自身的数据来构建更好的产品的技术。google公开的资料显示, 早前使用联邦学习技术来改善google的输入法的效果, 具体的流程如下:
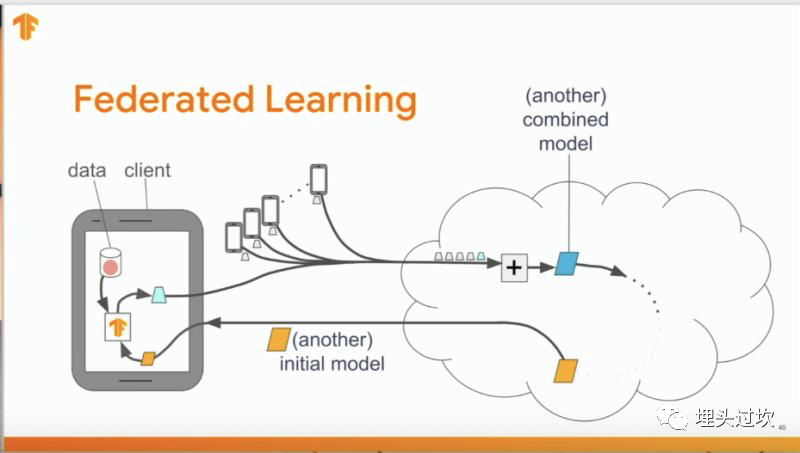
横向联邦学习是类似参数服务器的(parameter server)的架构, 一开始各个手机终端本地拥有初始的模型, 成千上万的终端在本地利用本地的数据进行训练, 再把模型的一些中间计算结果比如梯度信息等上报到训练中心, 训练中心汇总上报的梯度信息, 再训练一个新的模型, 训练好之后重新下发给各手机终端, 如此反复迭代, 持续不断地利用分布在用户手机终端的数据和模型来共建一个效果更好的模型, 而这个过程中不向外传输用户的原始/隐私数据。
这几年联邦学习的概念有些扩展, 主要是香港科技大学的杨强和微众在大力地推广。现阶段联邦学习通常会分为横向联邦学习、 纵向联邦学习和迁移联邦学习, 它们各自的特点如下:
| 类型 | 数据分布 | 适用场景 |
| 横向联邦学习 | 各方相同feature, 不同ID,各方都有自己的label | 各方样本数量不足,差异化大,各自有标签的场景 |
纵向联邦学习 | 各方相同ID,不同feature,某一方有label | 各方样本数量充足,但只有某一方有标签的场景 |
| 迁移联邦学习 | 各方的ID和feature重叠较小 | 样本标注成本高、样本数量不足的场景 |
在近几年联邦学习尝试商用, 在2B领域, 各大厂商主要还是主打纵向联邦学习, 原因是纵向联邦学习更能满足企业之间数据的流通、借助别人的数据来赋能自己的生意。
下面我们先来看一下纵向联邦学习的模型训练的示意图:
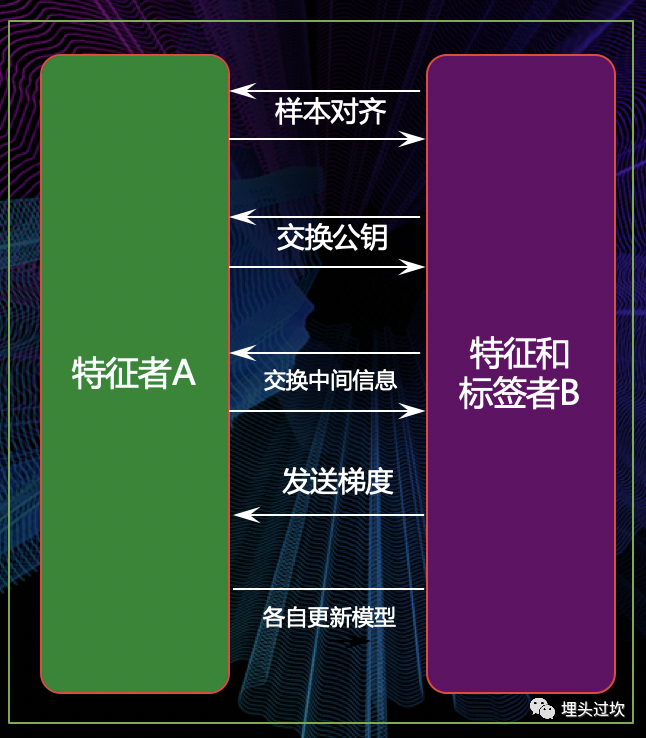
这是个两方参与的场景, 其中B是带特征和标签的, 训练的主要步骤为:
a. 两方进行样本对齐
b. 交换用于信息保护的公钥 (当前很多实现主要还是基于半同态加密)
c. 开始模型训练,交换中间信息
d. B计算梯度信息, 同步给A
e. 两边各自模型,直到收敛或者达到最大训练迭代次数, 不然重复c
而将纵向联邦学习进行产品化的完整架构可以参考如下:
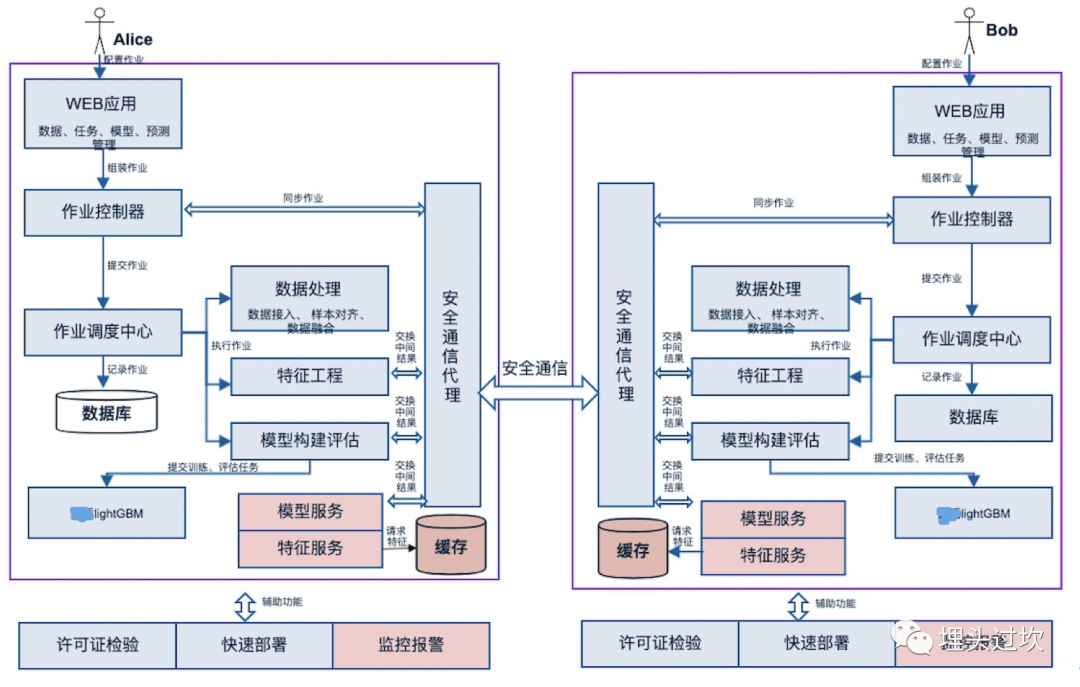
这个架构主要实现两方的纵向联邦学习。 参与方为Alice/Bob, 采用DAG调度框架, 用户通过网页进行数据上传、管理、 作业配置、触发、查看,模型评估、及发起预测等等操作。 主要分为模型构建及模型推理两大部分, 其中模型构建又包括数据处理(数据导入、数据对齐、数据融合等操作)、特征工程及模型的构建和评估, 模型推理包括模型serving及在线特征服务。 公共的模块包括作业控制器,用来组装作业,然后提交给作业调度中心的, 两方之间的安全通信是通过安全通信代理模块来完成的。 下面的支撑模块主要是产品进行私有化部署实施所需要的, 主要包括许可证检验、自动化部署及自动化监控报警运维模块。
用户使用时, 先在页面上选择或者填写合作方的信息、数据集信息等,然后一般是数据需求方发起建模, 数据拥有方可以做到接近自动化, 数据需求方先进行模型构建, 填写建模的表单, 包括数据处理、特征工程、模型构建和评估各步骤的参数,然后提交训练, 作业控制器会同步对方的作业控制器将相关的作业信息同步过去,然后分别两边各自调度执行, 直到模型训练完成; 用户接着可以进行模型推理, 填写模型推理、在线特征服务的参数,提交即可。
总的来说, 联邦学习提供了隐私计算的一种新的解决方案, 在数据不出本地的情况下完成协同建模, 目前这门技术还在发展中, 有包括安全、性能等问题需要进一步解决, 不过也已经在一些不那么敏感的领域和行业开始进行商用了, 前景还是挺好的。
