




首先对上一篇《白呼白呼 gRPC,INT,和数据中心交换机(1)》做一点补充(不打草稿就是这种后果)。
前段时间我写过一篇文章给大家分享怎样编故事忽悠(划掉)客户购买25G以太网交换机《为什么云计算数据中心要使用25G TOR交换机?》。云计算数据中心需要RDMA对并行计算和分布式数据库和存储系统等应用进行加速,而且集群规模越大,对RDMA的需求越迫切。
“规模”是一个很重要的变量。推荐大家阅读《腾讯内网的小秘密》,引用其中一小段:
你可能没有意识到,我们的一生,都在和量级作斗争。你吃一个馒头容易,吃十个馒头就很难。你每月赚到5000很容易,每月赚到50000就很难。你学会500个英语单词很容易,你学会5000个英语单词就很难。你打游戏的时候,苟到最后十人挺容易,但是把把吃鸡就很难。体会到了吗?无论是人生哪个方向,跨越一个量级,难度可不止增加十倍。
而通常采用的RDMA是RoCE,因为性能和Infiniband差不多,但是成本却低很多。RoCE把RDMA over在以太网上,要做到无损传输,就要求以太网交换机能够处理好PFC和ECN。交换机仅仅支持PFC和ECN的功能是不够的,还需要对MMU进行精细化的管理。推荐大家阅读《浅析RDMA网络下MMU水线设置》的相关内容。
对MMU进行管理的前提,是能够知道buffer水线的状态,也就是要对其进行实时的监控。对于这个需求来说,Netconf太重了,XML/JSON的数据格式也是给人类阅读的,我从来没学过都可以看得八九不离十。但是机器阅读的不是文本,是二进制编码。所以需要Protocol Buffer和gRPC来满足这个应用的需求。gRPC/Netconf/REST各有特点,有各自的使用场景。
好了,下面接着白呼INT。
在《思科DNA架构SD-Access方案浅析》中提到,Cisco采用的Telemetry技术是Syslog/SNMP/NetFlow。说来惭愧,虽然很久之前就接触NetFlow/Netstream并实际操作过sFlow,但是在去年我才第一次听到“Telemetry”这个名词,中间专注于802.11无线网络的时间太长了。显然,Telemetry就是NetFlow/sFlow/IPFIX,而In-Band Network Telemetry则是另外一种技术。
那么Telemetry有什么问题?为什么有了Telemetry还需要In-Band Network Telemetry?
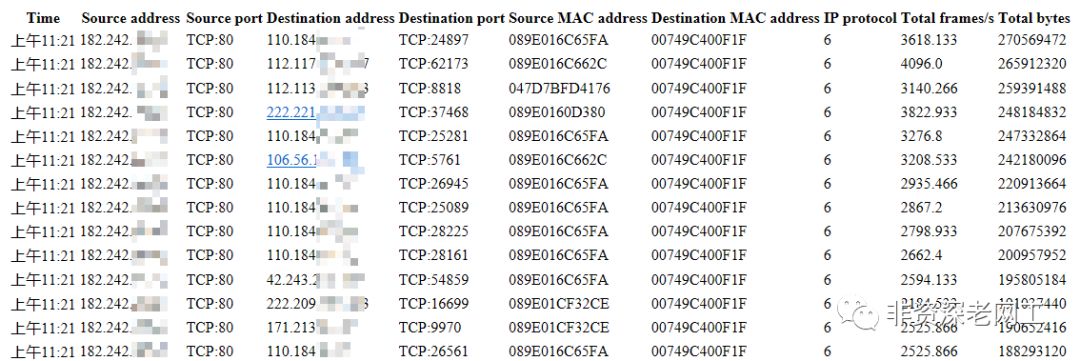
上面的截图是前几天在我的一个客户的交换机上采集的sFlow报表。可以看到,得到的sFlow报表是基于五元组(源IP,目的IP,协议,源端口,目的端口),也就是基于Flow或Connection来进行监控。同时也可以包括数据流的其他信息,例如源MAC,目的MAC,传输的数据包数量,总共的字节数,inputInterface和outputInterface(在生成报表的时候我们没有选择这2个项目)。从这个报表中,我们可以得到L3/L4信息,配合应用识别可以得到一些L7信息。但是对于底层的L1/L2信息,我们只能获取MAC地址,无法获取对于运维工作至关重要的延迟、抖动、丢包率、队列占用率、链路利用率等信息。
Telemetry的另一个问题是基于网络节点设备(VMware的vSwitch也支持Telemetry)单独进行采样,报表独立生成,无法进行端到端的路径监控。自然地,基于Telemetry实现SDN网络的集中控制也比较困难。
第三个问题是Telemetry使用采样的方式,需要CPU处理,时间尺度也比较大。而网络中经常发生微突发,队列状态、丢包率和延迟在毫秒级别变化,Telemetry没有能力在这个尺度进行监控。
实际上Telemetry的问题远不止这些,它们已经不再适合于当下数据中心网络的运维场景。
那么In-Band Network Telemetry是什么东东?
我们先从字面上来理解:
词根 tele = remote,metry = metron = measure。意思是从远程的,或者无法直接访问的节点上采集数据,实现监控的功能
Network:监控的是网络状态和事件,不仅包括上面提到的延迟、抖动、丢包率、队列占用率、链路利用率等信息。还有其他的,后面再讲
In-Band:传统的Telemetry是一种带外技术,Telemetry流量单独生成,单独传输,与业务数据流量互不影响。但是INT是一种带内技术——INT的数据嵌入到每个业务数据包里面,这意味着INT并不是基于Flow的,而是基于Package,颗粒度更细。同时,INT工作于数据面,不需要控制面参与,对CPU几乎没有影响
现在让我们看一张图,快点进入状态:
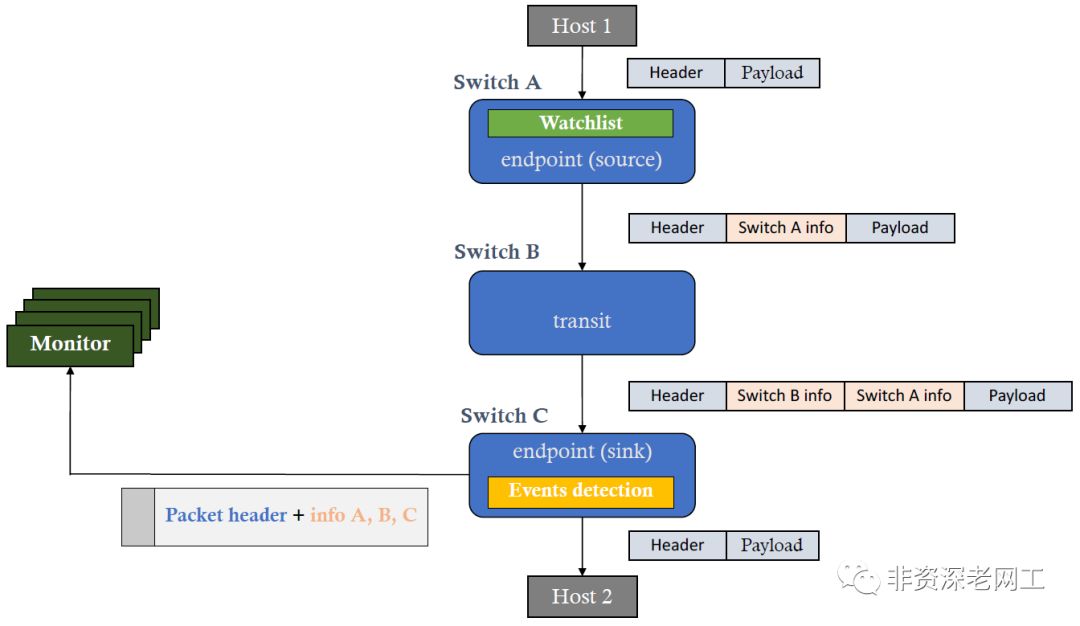
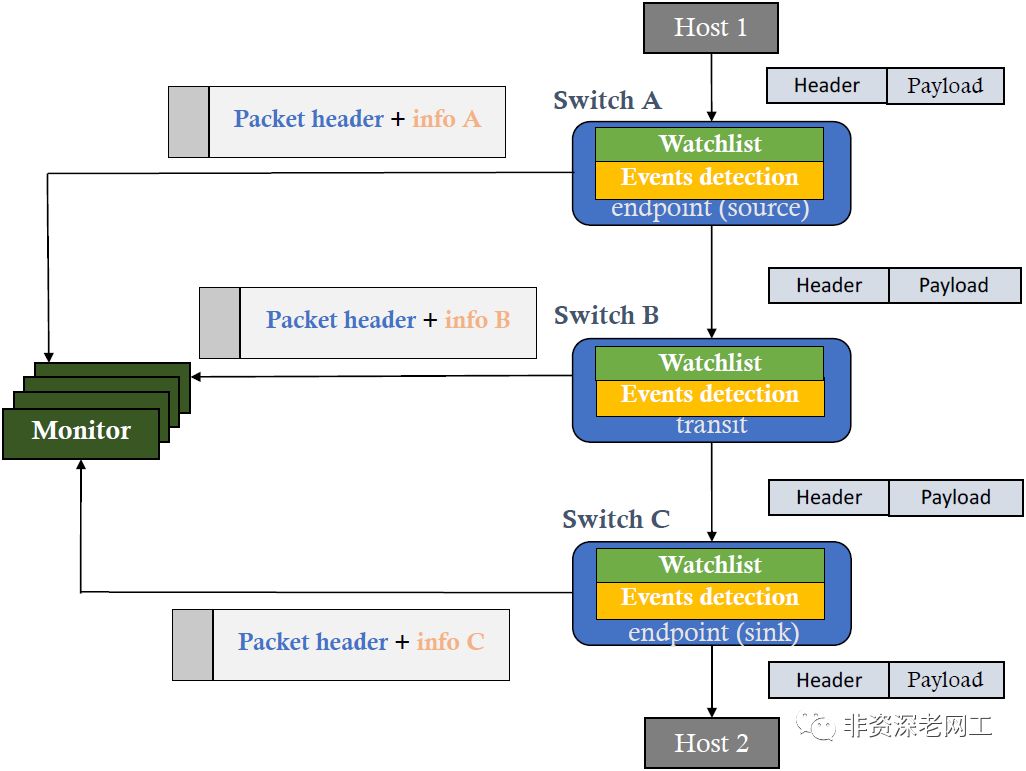
如上图所示,INT的处理过程如下:
Host 1向Host 2发送一个数据包,有正常的Header和Payload
Switch A发现数据包符合Watchlist,于是将元数据插入到Header和Payload中间,然后转发给Switch B。Switch A是INT的发起节点,称为INT source
Switch B解析到Header后面的INT信息之后,知道这是一个INT数据包,于是把自己的元数据插入到Header和Switch A的元数据中间,然后转发给Switch C。Switch B是INT的中转节点,称为INT transit
Switch C发现自己是最后一个INT节点,于是把Switch A和Switch B的元数据取出来,加上自己的元数据,一起封装到一个数据包里面发给监控平台。通常是采用IPFIX,也可以采用Apache Kafka。同时,Switch C把正常的业务数据包发给Host 2。Switch C是INT的结束节点,称为INT sink(请注意,INT支持Domain和Domain的嵌套,所以sink节点不一定是所有INT的结束节点)
这是一个端到端的,Hop-by-Hop的路径监控过程。因为INT依靠交换芯片工作于数据面,符合Watchlist的每一个数据包都可以被监控到,能够监控到微突发,而且可以实现线速的,Tb级别的高性能监控。
那么问题来了,什么是元数据?
元,Meta,牛津词典的释义是:
(US)(of a creative work) referring to itself or to the conventions of its genre; self-referential
意思是“自指的”,所以元数据就是描述数据的数据。这样讲太抽象了,我们来看看元数据具体都包括哪些种类的数据。下图是INT Hop-by-Hop Metadata Header Format,其中Instruction Bitmap中的每一位都对应一种Metadata:
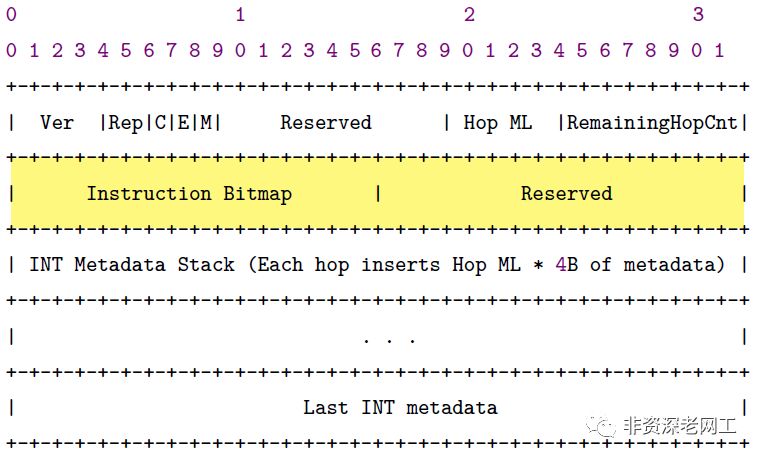
bit0:Switch ID
bit1:Level 1 Ingress Port ID (16 bits) + Egress Port ID (16 bits),可以是物理端口也可以是逻辑端口
bit2:通过对比入口和出口的时间戳,计算出的当下这一跳产生的延时
bit3:Queue ID (8 bits) + Queue occupancy (24 bits)。Queue occupancy就是这个INT数据包在被转发时,观察到的端口队列占用情况,可以用bytes,cells,或者packets来表示
bit4:入口时间戳
bit5:出口时间戳
bit6:Level 2 Ingress Port ID + Egress Port ID (4 bytes each),可以是物理端口也可以是逻辑端口
bit7:当INT数据包被发送时,出口出向的带宽利用率
bit15:Checksum Complement
bit8到bit14是保留位,这意味着以后可以加入更多种类的元数据。INT目前还在草案阶段,实际上现在Barefoot和Cisco已经可以将数据包匹配了哪个转发规则策略加入到元数据中。
Instruction Bitmap后面还有16位的保留位,有更大的拓展空间
凡有接触,必留痕迹(Every contact leaves a trace)
——现代法证学的开山大师埃德蒙•罗卡(Edmond Locard,1877-1966)
数据包同样符合罗卡定律——它在网络中经过,必然会在网络传输节点上留下痕迹,这些痕迹,就是Metadata。
继续提问,INT的作用是什么?都有哪些适用场景?
INT最主要的用途是OAM——Operation, Administration and Maintenance。了解场景,最好的方式是从应用系统入手。Barefoot的产品列表中有一个INT可视化监控平台,叫做Barefoot Deep Insight,它有4个最主要的功能:
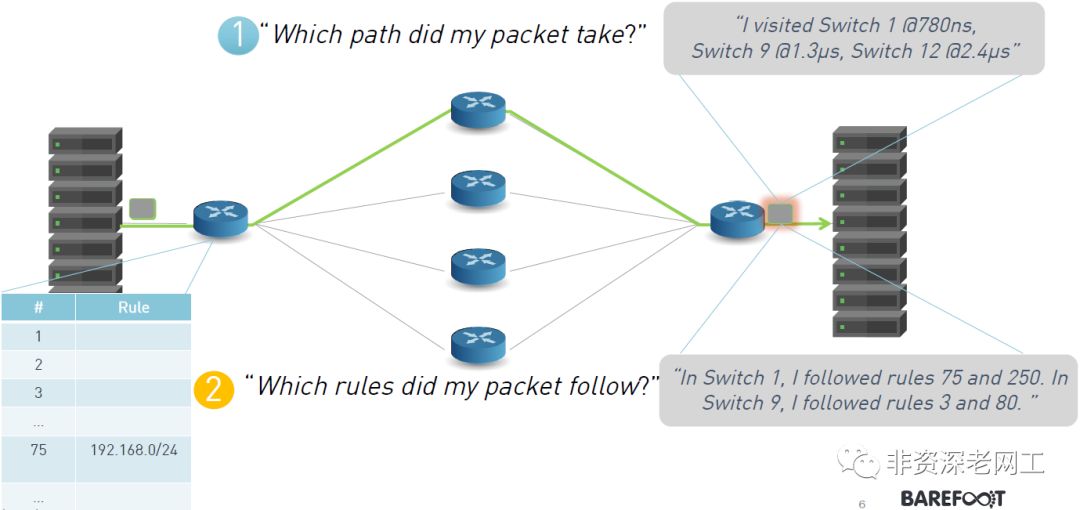
1、Which path did my packet take?
当管理员制定了流量工程的策略,Service Chain的策略,PBR的策略之后,怎样确认数据包是按照预定义的路径转发的?另外,数据中心网络普遍存在等价路径,也广泛使用微服务和NFV,需要对数据包的传输路径进行验证。
2、Which rules did my packet follow?
在确认数据包的转发路径之后,还需要知道数据包为什么会沿着这个路径转发,它遵从了哪些规则?
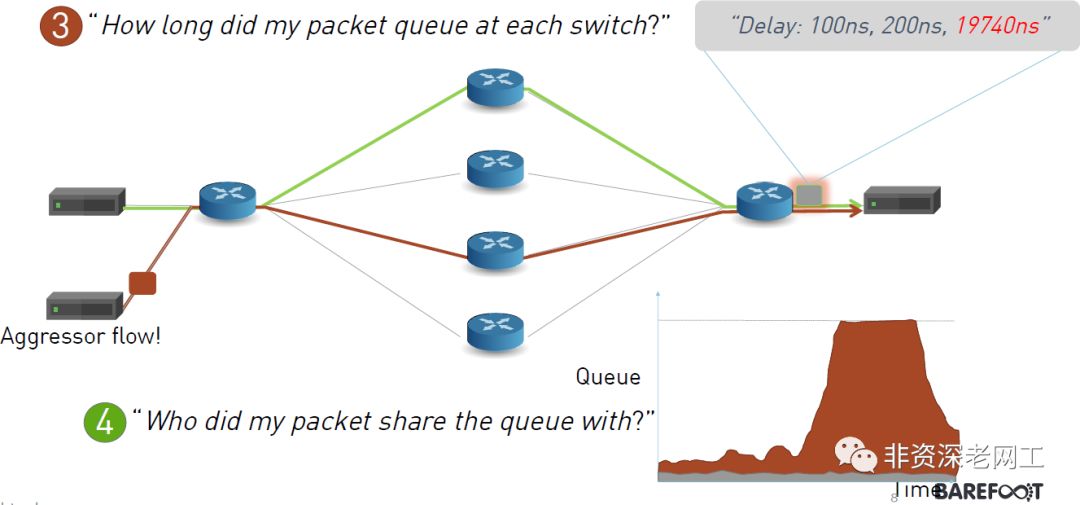
3、How long did my packet queue at each switch?
网络运维部门作为业务部门的乙方,也需要提供SLA服务等级协议。怎样对网络的SLA进行评估?INT是一个很好的方法。
4、Who did my packet share the queue with?
如果发现Packet在某个位置出现了延迟问题或者丢包了,需要知道原因是什么。例如,是不是有其他的流量挤占了队列空间?
除了OAM之外,INT还具备实时控制和反馈的机制。比如RoCE场景的ECN功能,INT sink如果发现有拥塞发生,利用可编程芯片,从数据面发送信息给INT source的控制面,INT source可以据此调整流量转发的行为。请见下图的direct feedback loop蓝色箭头虚线:
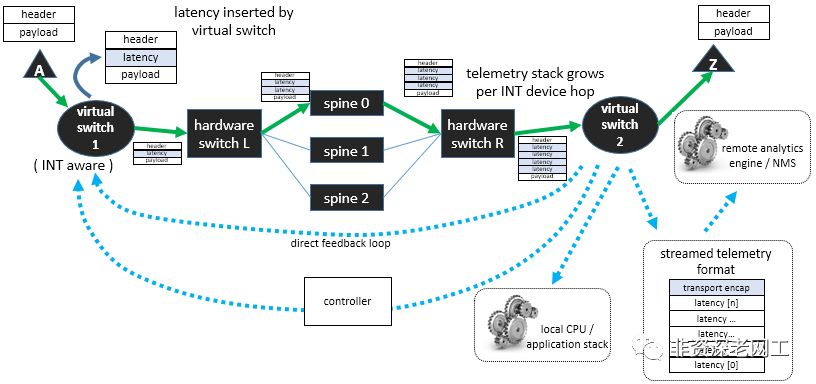
这张图又引出新的问题:不是说INT是工作于数据面,不需要CPU参与吗?为什么上图要把CPU画出来?
没错,INT工作于数据面,不需要控制面参与,对CPU几乎没有影响。请注意“几乎”两个字。
有一些设备本地堆栈的应用,需要利用CPU。例如Cisco的Extended Ping就是一个本地INT应用:
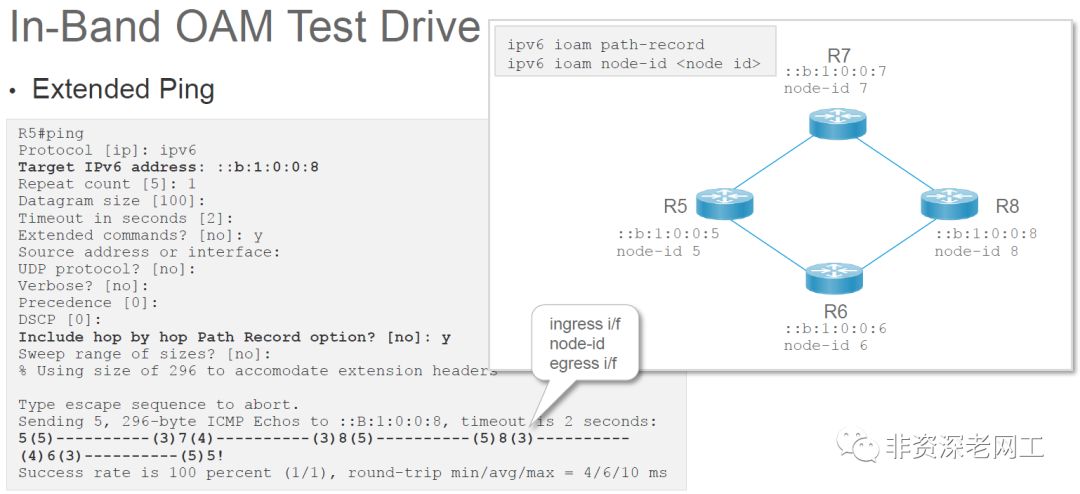
多说几句,现在越来越多的公司加入了Barefoot发起的INT工作组,包括Cisco。我们都了解Cisco的风格,他们也发布了自己的IETF草案,称为 In-situ OAM(也称为In-band OAM,简写为iOAM,http://t.cn/RdSFkEK),这个草案也有Barefoot参与。未来形成标准的时候,很有可能将INT和iOAM融合在一起。
回到正题。另外,Metadata的插入和弹出工作确实不需要CPU参与,但是Sink节点需要取出所有Metadata,打包成IPFIX或者Kafka或者其他协议的数据包,发送给远程的监控平台(比如Barefoot Deep Insight),这个过程是由CPU来完成的。
我们再来思考这个打包的过程,将Tb级别数据包的Metadata进行package封装,需要多大的CPU?IPFIX本身是Telemetry技术,它能实现1:1的采样吗?
答案是不能。所以送给监控平台的INT数据并不是全量的,和Telemetry一样,这里也有一个采样率,实际部署的时候一般可以做到1000:1。
问题又来了,既然也有一个采样比,那INT应该也没有能力监控微突发呀。
其实不需要担心。INT具备实时控制和反馈的机制,此外还可以进行网络事件检测。一旦有微突发等网络事件发生,INT sink可以实时反馈给SDN控制器,然后由SDN控制器对网络进行集中或分布式的控制。当然,遭遇到微突发的所有数据包的全量Metadata也会发给监控平台。
到这里就差不多了。再补充一点内容。
1、除了Hop-by-Hop的模式之外,INT还支持Destination模式和Postcard模式:
Destination Mode,不再有transit节点,路径的中间节点透明转发INT数据包
Postcard模式,不再是基于Path进行监控,而是各个节点单独发送INT Metadata给监控平台,每个INT节点都具备网络事件检测的能力,业务数据包在网络中传输的过程中不会被插入Metadata
2、除了具备可编程芯片的以太网交换机可以担当INT节点,一些智能网卡,裸金属服务器(需要eBPF, extended Berkeley Packet Filter,是内核追踪、应用性能调优/监控、流控的内核架构技术),Hypervisor(需要Open vSwitch,VMware也是INT的发起者之一,但现在似乎还没有在商用版本的NSX上面支持INT)也支持INT功能,可以在虚拟化环境中实现端到端的INT监控,下面是一个智能网卡厂商Netronome提供的虚拟化环境Metadata的插入过程:
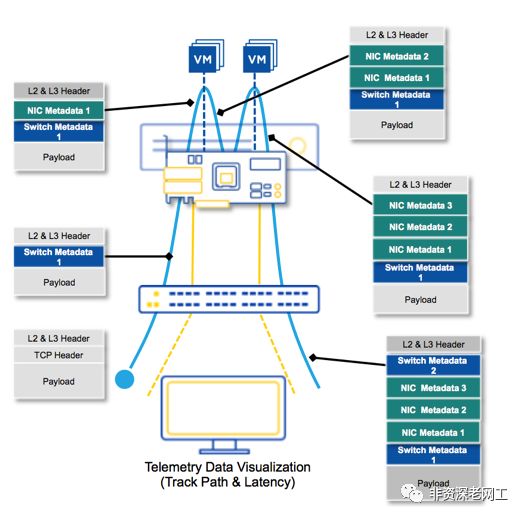
3、INT数据包的封装方式也有很多种,可以是VXLAN-GPE,Geneve,NSH,TCP,UDP,GRE。详情请点击左下角阅读原文,下载最新版本的INT Specification和Header Format Specification。
不知道还有没有第三篇。就酱,再见!
