




去年在学习数据中心网络架构的时候,发现了一个Blog很详细的介绍了Facebook数据中心Fabric网络架构。国内也已经有很多人进行了翻译和介绍,但是为视频做字幕似乎只有我一个。去年把视频放到了优酷上,到现在为止只有十几个人看过 :-(
看过Facebook的视频之后,收获很大,但同时也很疑惑,为什么现在国内互联网巨头们的数据中心还在使用Cluster架构(虽然他们自己宣称是CLOS架构),而Facebook和Google早在4年前就已经进化到Fabric架构了?
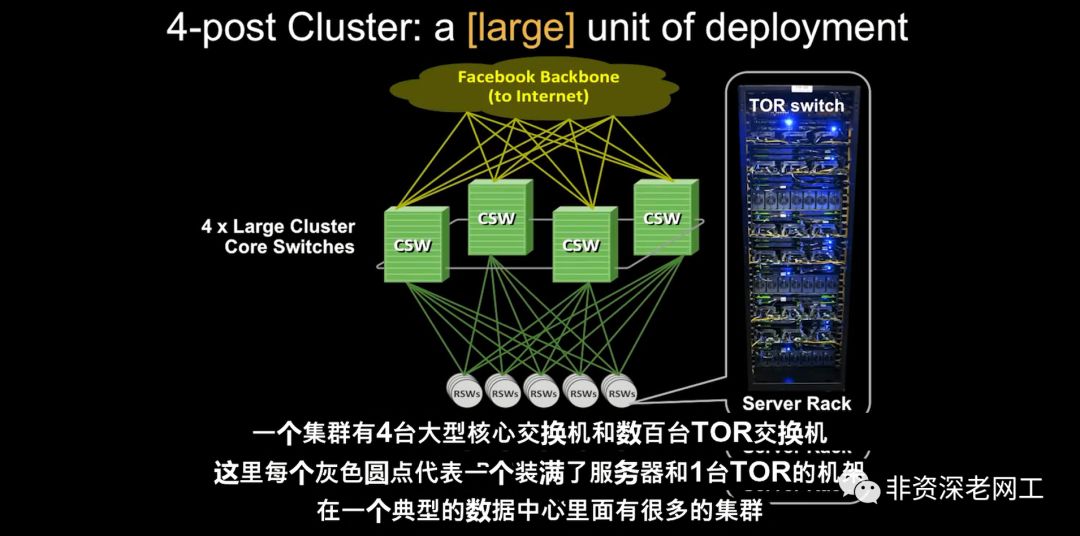
上图就是Facebook在2014年之前使用的,国内现在还在使用的Cluster架构图,在一个IDC里面放4台8个业务槽或者16个业务槽的大核心,连接100多台甚至是数百台TOR。即使升级到25G/100G架构也还是这样的部署方式。
而Facebook新一代Fabric架构把Cluster缩小,称为Pod。每个Pod有48个服务器机架,48台TOR,4台小核心。小核心是4个业务槽位的自研交换机,在网络架构中被称为Fabric Switch,夹在Leaf和Spine中间。
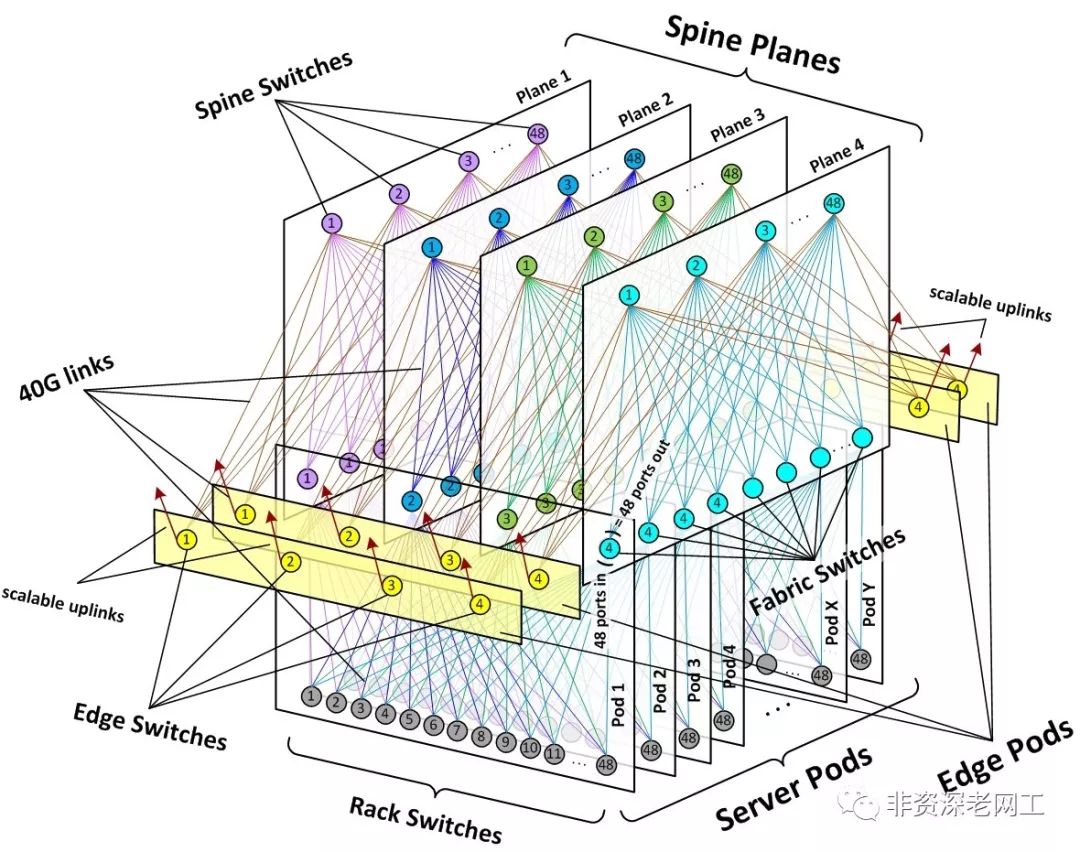
Fabric架构的创新是提出了Spine平面来提供Pod之间的东西向流量转发。一共有4个各自独立的Spine Plane,每一个Plane的核心层一般是48台Spine Switch,接入层是Fabric Switch。可以根据数据中心的规模进行横向扩展。
Rack Switch的端口数量是 48*10G+4*40G,10G端口连接服务器,40G端口分别连接4台Fabric交换机。
Fabric Switch和Spine Switch都采用自研小核心,称为“6-pack”。有4个标准宽度业务槽(8个半槽),2个交换网板。每个半槽接口板卡支持16*40G,整机最多可提供128*40G端口。

Fabric Switch采用48*40G下行,连接48台TOR;48*40G上行,分别连接48台Spine交换机。共占用96个40G端口,收敛比1:1。
Spine Switch就没有上行端口的概念了,所有的端口都是下行端口,用来连接Server Pod和Edge Pod的Fabric交换机。每台Spine交换机最多可以连接128台Fabric交换机。
Edge Pod对应国内数据中心的Border,用来连接外部网络,包括骨干网和其他建筑物的Fabric网络。每个Edge Pod同样有4台Fabric交换机,但是其上行链路的数量并不固定,是Scalable的,取决于流量的大小。Edge Pod的数量同样也不固定。每个Edge Pod最大提供7.68Tbps的外部互联带宽,平均到每台Fabric交换机是1.92Tbps,换算成40G端口数量需要48个。这就意味着,每台Edge Pod的Fabric交换机最多需要48个40G端口连接Spine交换机,还有48个40G端口连接骨干网交换机,一共占用96个40G端口,收敛比同样是1:1。
相比于上一代的Cluster架构,这种Fabric网络架构带来的好处是:
网络单元更小,更简单
ECMP路径更多,容错率更高,相比于一台8槽或16槽大核心,一台6-pack小核心出现故障对网络的影响会小很多
网络更加标准化,模块化,这为自动化配置带来的好处是显而易见的,以后有机会再来了解一下Facebook的Zero Touch Provisioning,和商业网络设备厂商的做法不太一样
如果出现故障,通过对比其他路径就可以很容易的发现故障原因,并且下一次出现故障时就可以交给机器人或者AI自动处理
可视化也相对简单
可以更容易地掌控和调节网络中的数据
当然,现在是2018年,Facebook的Fabric网络也已经升级到25G/100G,6-pack已经退出舞台,新一代的交换机和Cumulus、Big Switch、Barefoot、Cavium等厂商都有合作,详情可以访问 http://t.cn/RBPqvoV
而国内的互联网巨头们虽然借鉴了Spine Plane的思想,但为什么还要采用大核心交换机,设计很大的Cluster呢?问过负责巨头客户的同事,但是没有得到答案,我也没机会当面去向巨头们请教,所以还是只能瞎猜了~
原因一,应该和机房的布线条件有关。
美国人少地多,所以数据中心的占地面积都很大,只有一层,外加一层“小阁楼”。汽车可以直接把集装箱开进去,建设速度非常快,布线系统也基本上只有水平布线。比如Facebook在阿尔图纳的数据中心园区是这样的:

内部的布线系统是下图这样的,MDF和BDF都在同一层,不仅网络架构是模块化的,布线系统同样也做到了模块化。
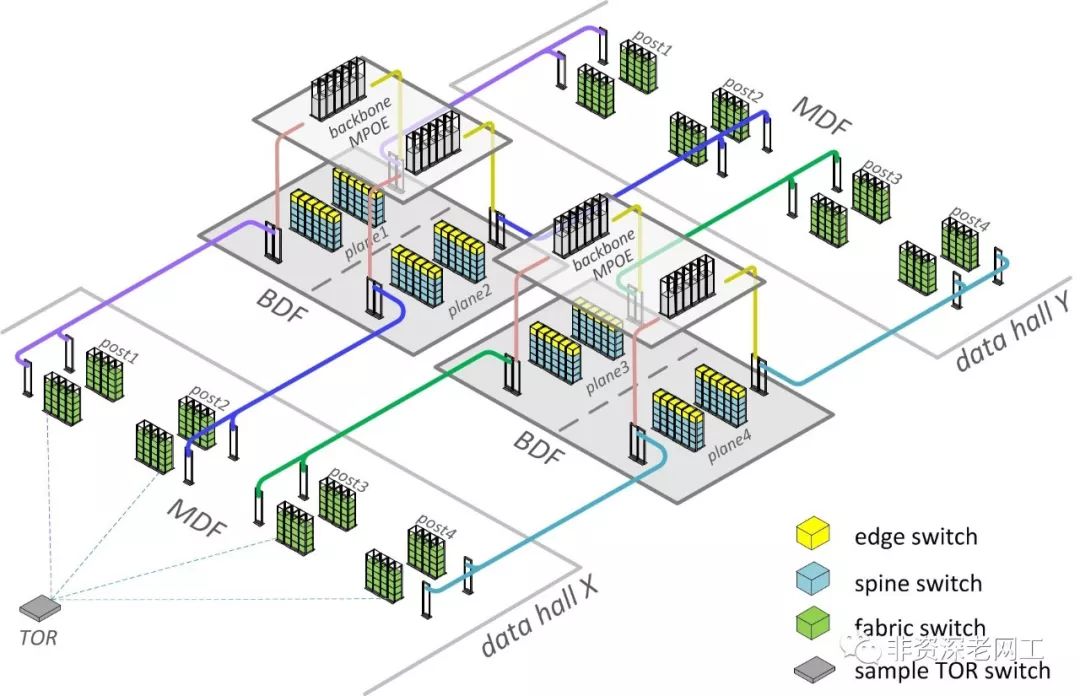
但是国内人多地少,地价也贵,据说北上广的房产总价都和整个美国的房产总价一样了。所以数据中心园区基本上会采用“楼宇”的形式来建设,然后再把“楼宇”分成若干个“机房”。布线系统会变得比较复杂,所以干脆就把一个机房做成了一个Cluster。
国内园区的图片我就不贴了,有泄漏客户信息的嫌疑。帮大家找到一个世纪互联的数据中心照片,请移步至 http://t.cn/RA1F7nT
原因二,国内的巨头在白盒上的投入比较少,而且还停留在TOR交换机的阶段,没有合适的Fabric交换机可供选择。
原因三,Fabric架构因为有更多的交换机互联链路,所以需要更多的光模块,算下来总体的投资要比Cluster架构更多,大概需要1.5倍的投资。
不过从去年底开始,因为国内数据中心产业的发展,也出现了建筑扁平化的数据中心,另外光模块的价格也在一直下降,所以开始有一些国内的互联网公司尝试采用Fabric架构,不过选择的交换机硬件类型是紧凑的2U交换机。
另外我司也很快会为互联网巨头推出4个标准业务槽位的数据中心小核心交换机,可以据此判断,真正的Fabric架构就要在国内普及了。
点击左下角“阅读原文”,可以访问Facebook的Blog。
