吾日三省吾身:高否?帅否?富否?
阿浪:否!否!否!
o( ̄ヘ ̄o#)
所谓人丑就要多读书,阿浪一直对MySQL数据存储的底层结构比较模糊,经过几天几夜的奋发读书(摸鱼),终于让我拨开了萦绕心头的困惑。
存储引擎
我们都知道MySQL拥有多种存储引擎。MEMORY、MRG_MYISAM、 CSV、FEDERATED、PERFORMANCE_SCHEMA、MyISAM、InnoDB、BLACKHOLE、ARCHIVE等,其中最常用的就是MyISAM和InnoDB。
MyISAM引擎
在MySQL 5.5之前的版本,MyISAM是默认的存储引擎。读性能良好,拥有较高的查询速度。
不支持行级锁,只支持表级锁。因为MyISAM会一次性获得SQL所需的全部锁 (这句话包含的信息很多),所以不会出现死锁,这少了很多麻烦事。当MyISAM在执行select/insert/update/delete语句时,会自动给涉及的表加读锁(共享),在执行对表做结构变更操作时,会加写锁(独占)。
当写锁和读锁同时被申请时,优先获得写锁。读锁之间不互斥,读写锁之间、写锁之间是互斥的,通俗的讲,读操作不会阻塞其他线程对同一表的读请求,但会阻塞对同一表的写请求,而写操作会全部阻塞。由于写锁可能会一直阻塞读锁,所以这正是表级锁发生锁冲突概率最高的原因。
本篇文章主要介绍InnoDB的存储,就不对其它知识点做过多拓展。
总结: 不支持行级锁、不支持事物、支持表级锁、读性能较高。
InnoDB引擎
从MySQL 5.5 版本开始,官方选择InnoDB作为MySQL默认的存储引擎。既支持行级锁,也支持表级锁,但默认情况下是采用行级锁。当InnoDB在执行select语句时,不会加任何锁,在执行insert/update/delete操作时,会自动给涉及数据行加排它锁。
InnoDB支持外键,包含外键的InnoDB表转为MyISAM会失败。InnoDB最大的不同就是支持事物,所有的存储引擎中只有InnoDB是事务性存储引擎,对每一条SQL语言都默认封装成事务自动提交。
而且,InnoDB支持MVCC。目前,随着行业发展项目数据的吞吐量越来越大,支持MVCC对于高并发是一个很大的优势。
总结: 支持行级锁、支持表级锁、支持事物。
更直观的比较: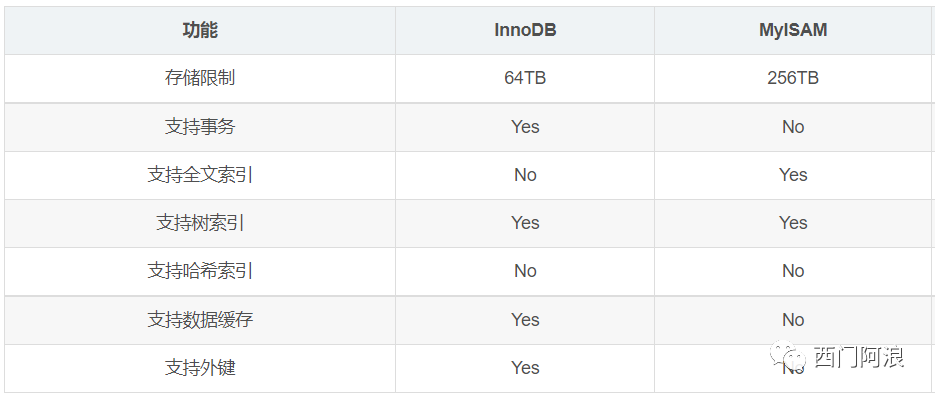
综上所述,两者各有各的优势,如何选择应该看自己项目的场景。如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读也有写,使用InnoDB效果更好。
页(Page Structure)
大学学习操作系统的时候,我们知道 "页" 是操作系统从磁盘取数据到内存的基本单位,默认为4KB。虽然部分处理器会使用 8KB、16KB 或者 64KB 作为默认的页面大小,但是4KB的页面仍然是操作系统默认内存页配置的主流。
CPU在做指令操作时,从目标地址取数据到内存需要一次IO操作,多次操作数据就要相应发生多次IO。若每次取的数据都很小(远小于4KB),为减少IO操作每次直接取一页(4KB)。
InnoDB中的“页”
在MySQL中,select指令根据where字段查找数据时,表中每行数据都要被读到内存中依次与之比较,有多少条数据就要发生多少次IO操作。这样资源消耗太大,于是InnoDB借鉴了操作系统对内存的管理,引入了“Page Structure” 来减少IO操作。
InnoDB采用”页“的形式存储用户数据,有时也被称为“块”。MySQL默认的非压缩数据页为16KB,0~16KB偏移量即为0号数据页,16KB-32KB的为1号数据页,依次类推。
从MySQL官网可以了解到,InnoDB的页结构包含以下内容:

因为Page的内部结构很复杂,阿浪只能带着大家从宏观上浅层了解,感兴趣的同学可以对着官方文档深入研究:https://dev.mysql.com/doc/internals/en/innodb-page-structure.html
Fil Header
fil header用来描述页信息。记录了页的空间ID,区分了记录在同一文件内所属不同表空间的数据页,并且提供指针连接各个数据页。

其中最重要的是 fil_page_prev 和 fil_page_next 两个指针,当表数据达到一定规模时,就会生成大量的数据页,这时候通过指针以双向链表的形式维护数据页的连接性和有序性。
Page Header
用于记录页内的状态信息。分配新页的信息、页内第一条数据地址等。
User Records
表内有多少条数据,UserRecords就要存储多少条记录。若是主键,存储完整的表数据,并根据主键升序排列来提升检索效率。若是非主键索引,则根据索引字段排序。
Page Directory
UserRecords可能保存一个很长的单链表,因为长链表不支持随机访问,检索时间随着数据规模的增长而增长。所以PageDirectory以组划分链表记录用户数据的相对位置,默认以6条数据为一组。
当查询数据时,直接与Page Directory内的数据比较快速锁定数据范围,然后进入UserRecodes获取完整数据。
画图看更直观(简图):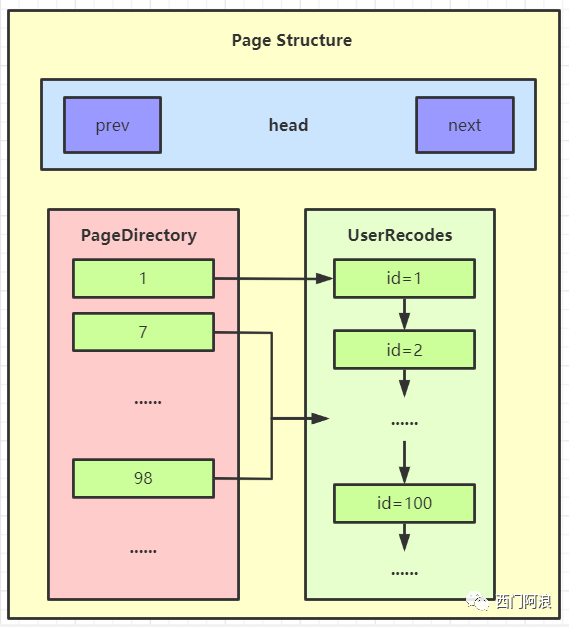
物理划分上的“区” “段”
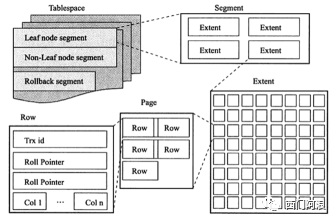
区(extent):由连续的64个16KB的Page组成的大小为1M的空间。区是实际的1M物理空间。当碎片区用完之后,就会申请1M的连续物理空间。
段(segment):由一个或多个区组成,不要求是地址连续的区。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
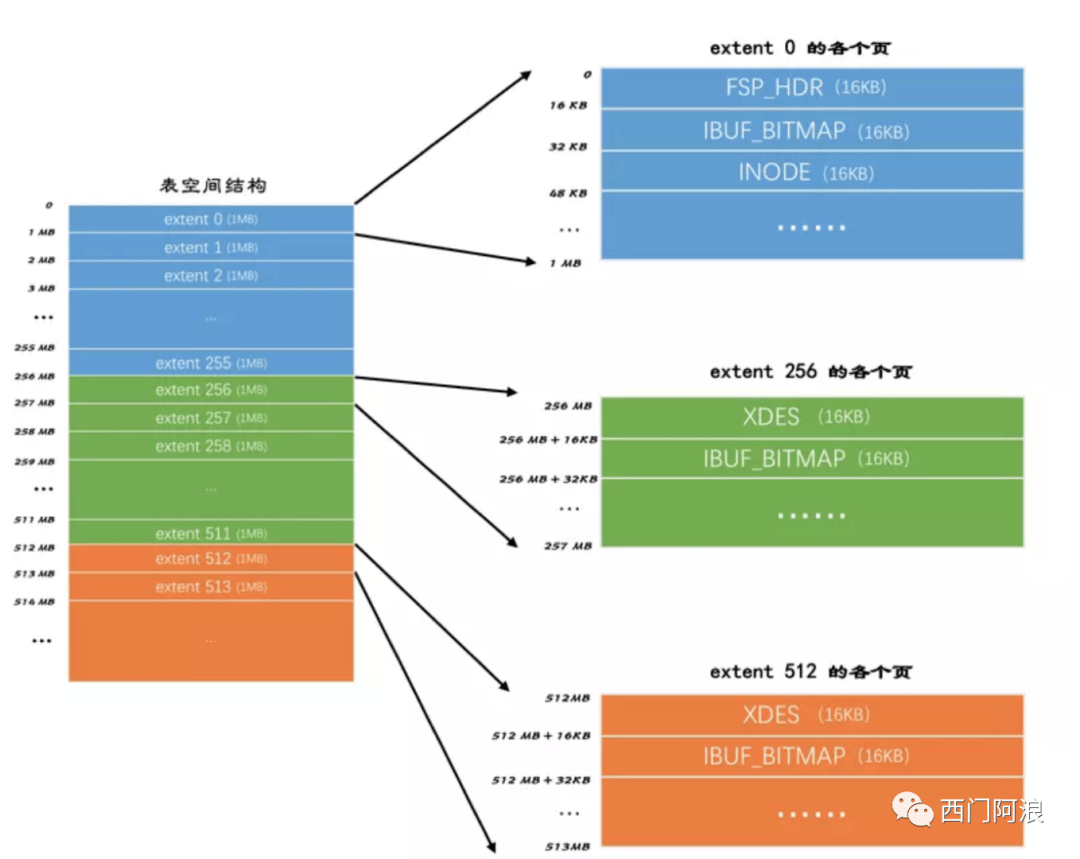
我从网上找到一张图,很形象的展示了区在表空间内的结构。
B-Tree与B+Tree
传统的B-Tree
有些人会读成“B减树”,虽然只是个名称,但出于规范化考虑,还是推荐把“-”看成连接符,读作“B树”。
说到B树可能日常中不常用,但二叉查找树(Binary Search Tree) 大家应该很熟悉。对于它的每个节点有这么个特性,若左子树不空,则左子树上所有结点的值均小于它的根结点的值。若右子树不空,则右子树上所有结点的值均大于它的根结点的值。
在二叉查找树的基础上又产生了平衡二叉查找树(Self-Balancing Binary Search Tree),增加了 左子树与右子树的高度之差的绝对值不超过1的特性,大名鼎鼎有的AVL树和红黑树。下面是一颗AVL树: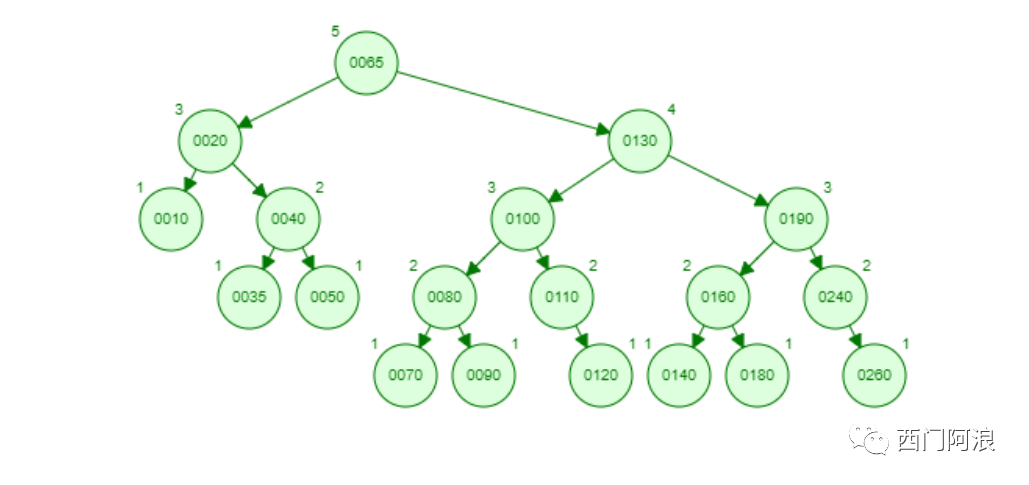
B树就是在平衡二叉树基础上实现的多路平衡查找树,继承了二叉平衡树的所有特征,又由于自身是多叉树,所以是个“小胖墩”。下面是一颗最小度数为5的B树: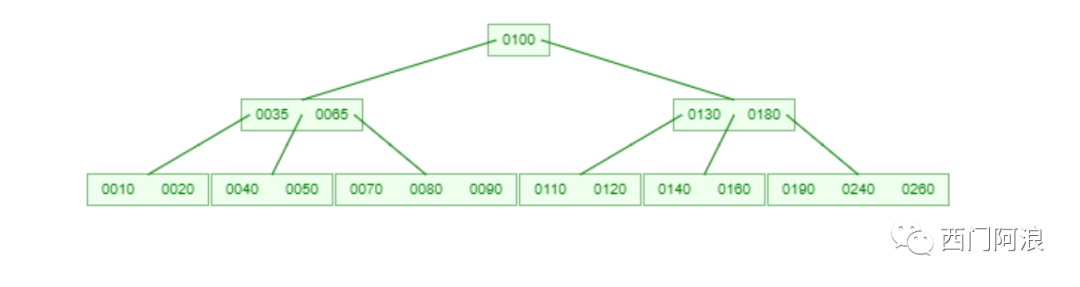
我们很明显的看出来B树比AVL树的高度要小,这会带来什么好处呢?
如果数据都放在磁盘里,与内存访问时间相比,磁盘访问时间非常长。大多数树操作需要 O(h) 次磁盘访问,其中h是树的高度。由于B树的高度较低,因此与二叉平衡树(如 AVL 树、红黑树等)相比,大多数操作的总磁盘访问量显着减少。
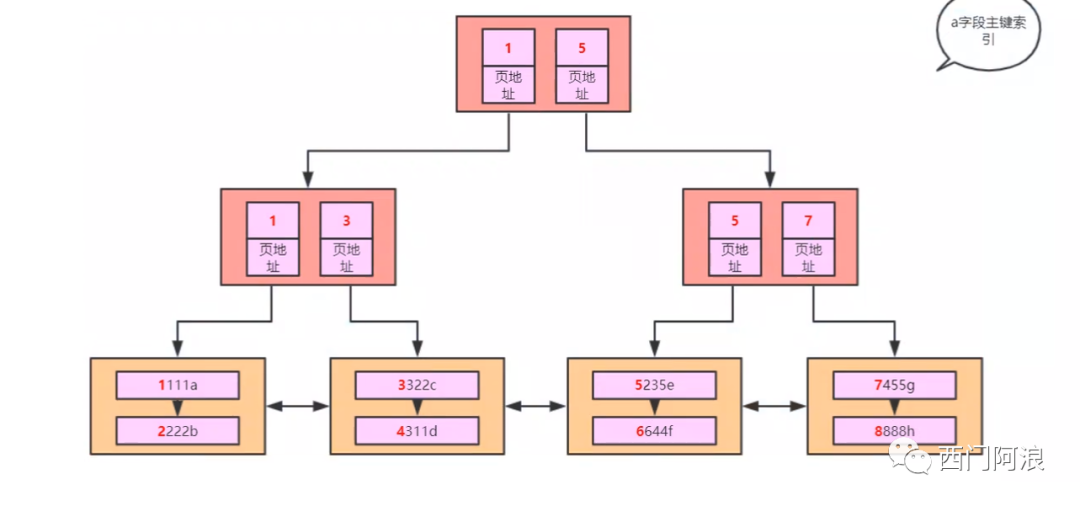
了解B树后,我们知道了从根节点到叶子节点的连接特性,但这样会损失叶子节点也可以相互指向带来的效率。InnoDB允许在叶与叶之间相互指向,所以InnoDB内被称为B+树。
InnoDB中的B+Tree
其实B+树仅仅只是B树的一个变种,而InnoDB中的B+树又在此基础上做了一个小改进。下面是最大度数为4的B+树:
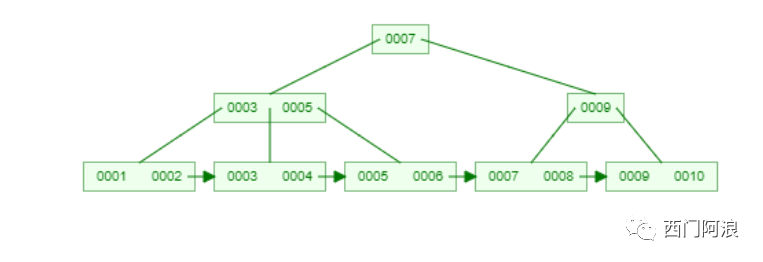
与上面的B树对比,最明显的是叶子结点通过指针相互连接,只看叶子结点的话就是一条单链表。为何说InnoDB里的B+树是传统B+树的改良版呢?因为InnoDB里的B+树的叶子结点不只有后继指针,还有多出来的前驱指针,叶子结点构成了一条双向链表。