




1、HDFS写数据整体流程
2、网络拓扑-节点距离计算
2.1、机架感知(副本存储节点的选择)
2.2、源码
3、HDFS读数据的流程
4、总结
1、HDFS写数据整体流程
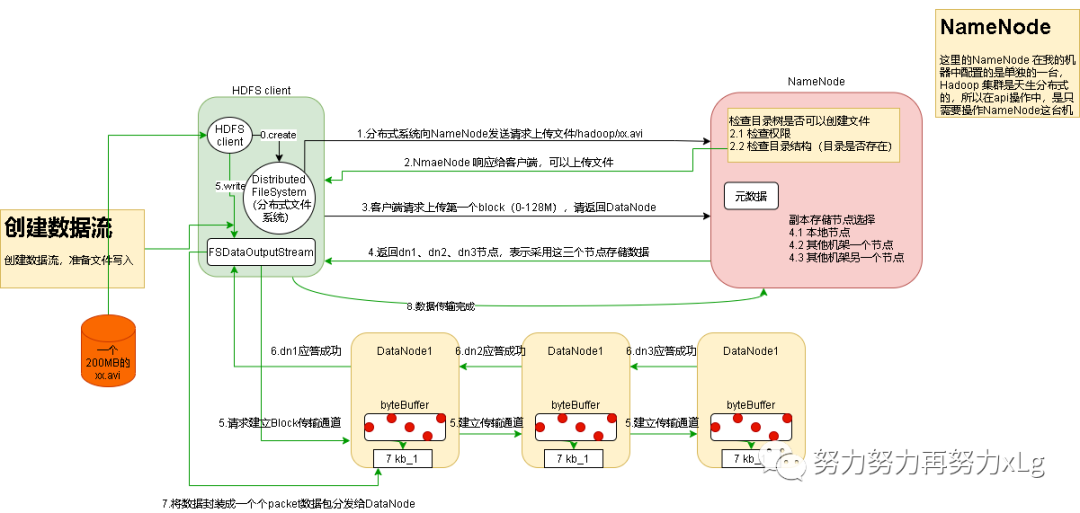
Hadoop 集群天生支持分布式的,在创建集群时,1号节点就已经设置为NameNode节点用来操作集群的。
在HDFS client 与集群创建好连接之后(这里以Java的API为例。),首先HDFS Client 为连接到分布式文件系统中,也就是NameNode暴露出来的连接端口。

image-20210919003308353 以上就是获取到分布式文件系统连接。

image-20210919003532155 该行代码包含了下述所有的操作
NameNode 接受到请求上传的请求后,会判断请求中父节点是否存在,检查权限,如果都没问题会返回给client确认应答
Client 收到上传通过应答之后,会向NameNode请求一个Block(默认大小为128M),并且返回对应的NodeData
此时的NameNode 会做比较复杂的判断包括如下几点
对现有的集群做负载均衡处理 判断计算并且返回最近的节点(这里设计到了就近的节点距离计算的逻辑) 返回的节点会包含自身,就近的机架等信息 收到传输对应的NodeData之后,Client 会创建输出流
FSDataOutputStream
进行数据传输dn1,dn2,dn3逐级应答客户端。 客户端这时才会给dn1上传第一个Block(先从磁盘中读取数据,将数据存放到本地内存中,为了提到效率),然后再讲数据以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1 每传一个Packet就会放入一个到应答队列中等待应答 这里的数据传输与zk中的数据交互非常类似,都是将数据拆分为多个packet数据包,进行分片传输。
一个packet的组成是由多个
chunk
和4个byte字节组成的,也就是多个chunk(512byte)+ chunksum(4byte)组成的,当这些个chunk装满了一个packet(64kb)时,才会传送到DataNode中。所有的packet会先存放到一个缓冲队列中,当一个packet发送到DataNode中时,还会在应答队列中缓存一份该packet,当该packet应答成功之后,应答队列中的缓冲会删除,如果没有成功,应答队列中的packet会重新发送给DataNode,以此类推。直到所有的数据都传送完毕,(有点类似于RocketMQ中的ack模式)
客户端请求dn1上传数据时,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通道管道建立完成
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器(并且会重复执行3-5步)
2、网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传最近距离的DateNode接受数据,该距离是如何计算的呢?
节点距离:两个节点到大最近的共同祖先的距离总和
首先理解一下机架的原理
机架相当于一个机房里面放着很多个架子,这些架子都整齐的码放着服务器
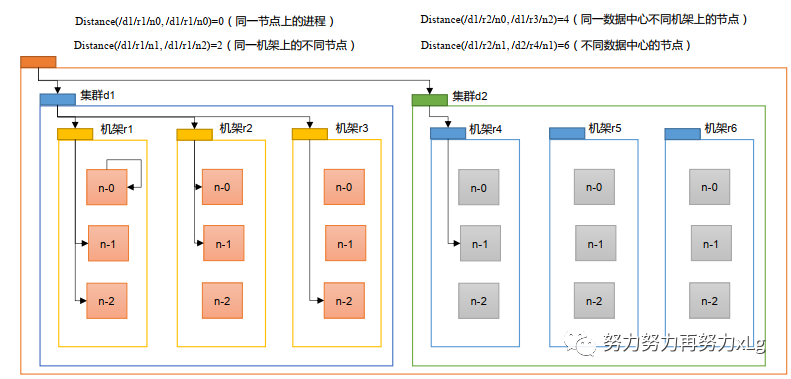
上图中
数据中心就是相当于一个机房
节点就相当于机房中的存放机架一排一排的编号
机架就是具体到那个编号的柜子
假设两个分片在同一个节点上,那么两个节点的共同祖先就是当前节点,不用想钱追溯。其他情况都一次类推,最终目的就是找到相同节点。
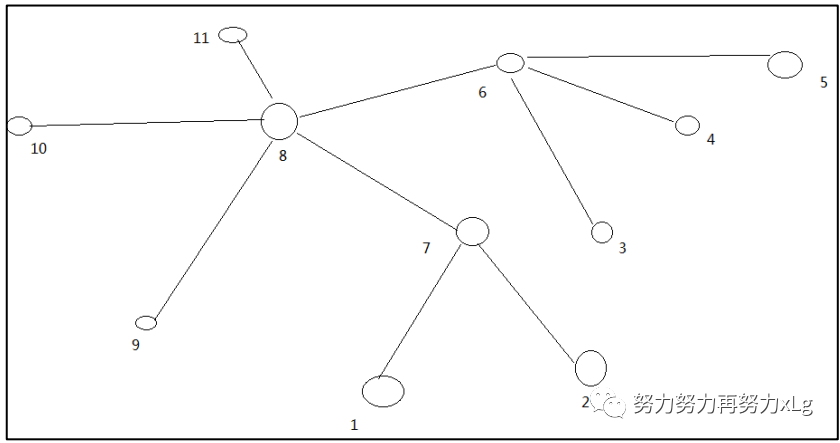
上图:假设 10 与5两个节点之间需要走一步是一样的道理
10 -> 5 需要走3步
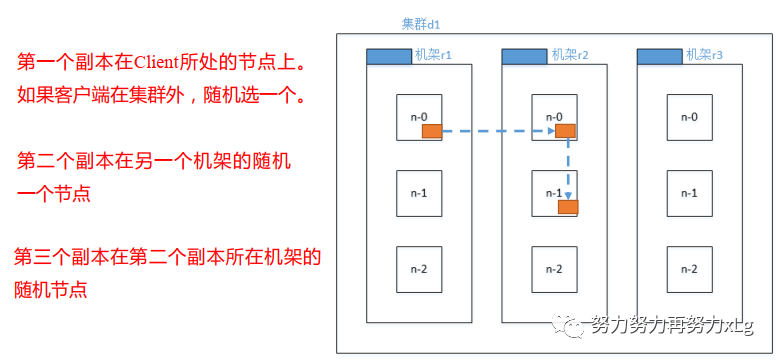
2.1、机架感知(副本存储节点的选择)
官网
The NameNode determines the rack id each DataNode belongs to via the process outlined in Hadoop Rack Awareness. A simple but non-optimal policy is to place replicas on unique racks. This prevents losing data when an entire rack fails and allows use of bandwidth from multiple racks when reading data. This policy evenly distributes replicas in the cluster which makes it easy to balance load on component failure. However, this policy increases the cost of writes because a write needs to transfer blocks to multiple racks.
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
从官方文档中可以知晓,在HDFS存储数据节点时,同时兼顾着性能和高可用的考虑,假设目前有三个节点,第一个节点Hadoop会选择存储在NameNode的本地节点,效率最高,而第二个会考虑到高可用的情况,会存储到最近的另一个节点上,但是第三个又会存储在第二个本地的节点上。
2.2、源码
BlockPlacementPolicyDefault
中的chooseTargetInOrder
方法
protected Node chooseTargetInOrder(int numOfReplicas, Node writer, Set<Node> excludedNodes, long blocksize, int maxNodesPerRack, List<DatanodeStorageInfo> results, boolean avoidStaleNodes, boolean newBlock, EnumMap<StorageType, Integer> storageTypes) throws NotEnoughReplicasException {
int numOfResults = results.size();
if (numOfResults == 0) { // 当节点数为0时,使用的是chooseLocalStorage 选择本地节点存储
DatanodeStorageInfo storageInfo = this.chooseLocalStorage((Node)writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes, true);
writer = storageInfo != null ? storageInfo.getDatanodeDescriptor() : null;
--numOfReplicas;
if (numOfReplicas == 0) {
return (Node)writer;
}
}
DatanodeDescriptor dn0 = ((DatanodeStorageInfo)results.get(0)).getDatanodeDescriptor();
if (numOfResults <= 1) { // 第二个节点 使用的chooseRemoteRack 选择远程节点
this.chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
--numOfReplicas;
if (numOfReplicas == 0) {
return (Node)writer;
}
}
if (numOfResults <= 2) { // 第三个时,一般情况会判断第二个if ,则落地到当前dn1节点上
DatanodeDescriptor dn1 = ((DatanodeStorageInfo)results.get(1)).getDatanodeDescriptor();
if (this.clusterMap.isOnSameRack(dn0, dn1)) {
this.chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
} else if (newBlock) {
this.chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
} else {
this.chooseLocalRack((Node)writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
}
--numOfReplicas;
if (numOfReplicas == 0) {
return (Node)writer;
}
}
this.chooseRandom(numOfReplicas, "", excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
return (Node)writer;
}
从源码的角度也可以很好的 看到hadoop 机架的感知逻辑
3、HDFS读数据的流程
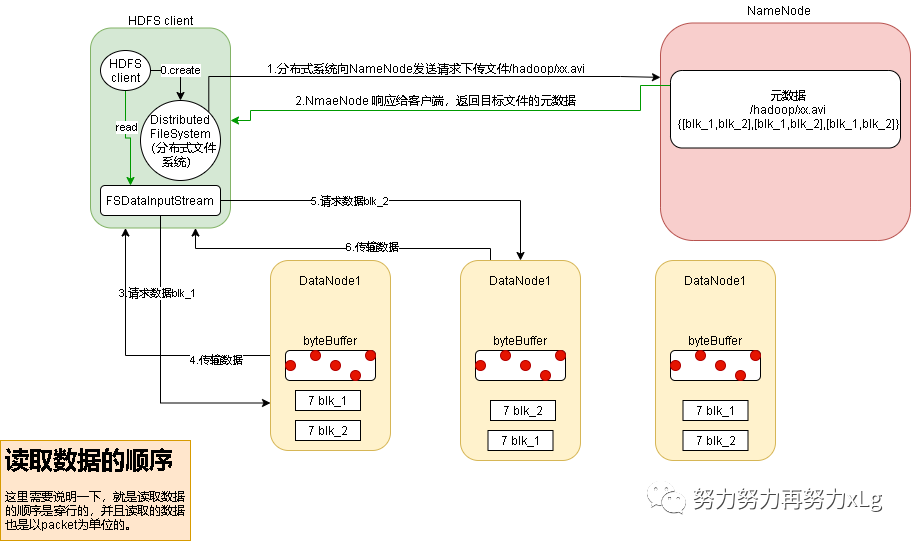
客户端通过 DistributedFileSystem 向 NameNode 请求下载文件, NameNode 通过查 询元数据,找到文件块所在的 DataNode 地址。 挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。 DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位 来做校验)。 客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
4、总结
在HDFS读写过程中,可以看得出开发者竟可能能提高了存储的新能和读取数据检索速率,并且天生自带的分布式也是非常好的高可用架构,但是任然存在问题,如果存放大量零碎的小文件,HDFS的基础架构很显然是不可以做到像MySQL这种毫秒级的反应的。
在写的过程中,HDFS也兼顾了数据的安全性,在写入数据时,会先缓存一份在本地内存中,还会将数据分发到一个应答队列中,该队列等待接受应答,如果长时间没有接收到应答,该数据包也可以重新投递。类似于RabbitMQ中的ACK模式。
在读写过程中,并没有采用并发思想,使用并发去同时操作多个NodeData,原因也很简单,这样会带来数据的不稳定,HDFS使用内存队列和数据分包的形式,解决了速度问题。(也算是折中的一种方案吧)

