




2.1、基于Redis 实现的延迟队列
添加延迟任务
多层时间轮
前言
前段时间,在对公司项目做完技术选型,其中针对超时订单有一个定时关单的业务。需要使用到延时队列进行自动的定时关单。
针对当前业务,我们敲定使用RabbitMQ的死信队列+TTL实现定时关单。(但是如果在整个项目中,没有使用到消息中间件,为了实现延时队列这一功能去引入一项新的技术,从而面临更多的技术问题,显然是得不偿失的。)
就此,我对延时队列的几种实现做了简单的调研。记录一下
1、应用场景
在订单系统中,如果用户在规定时间内,并没有完成订单,那么就需要自动取消 针对当前需求,当然很简单的就可以想到,一个定时任务,去扫表,来实时的监控订单或者其他业务的状态。(显然,是非常消耗性能,并且该功能有可能影响到主程序的主要功能) 安全工单超过24小时未处理,则需要自动拉取,通知相关负责人。 外卖,用户下订单后,超过10分钟未支付,或者外卖小哥超时等等
以上对于数据量比较少,并且时效性要求并不那么高的场景,可能我会采用定时扫表的方式,因为数据并不高,所以对数据库的压力也并不会太大。
但是如果数据量大,时效性要求比较高的数据,比如淘宝每天的所有新建订单15分钟内未支付的自动超时,自动关单。数量级高达百万甚至千万,这时如果还用轮训的方式扫表。估计第二天就不用来公司上班了。
以上数据量大,时效性要求高的情况下,就需要使用到延迟队列了。延迟队列为我们提供了一种高效的处理大量需要延迟消费信息的解决方案。下面探讨一下常见的几种延迟队列的解决方案。
2、Redis ZSet
利用redis的有序集合的数据结构ZSet,ZSet中每个元素都有一个对应Score,ZSet中所有的元素都是按照其Score进行排序的。
入队操作: ZADD KEY timestamp task
, 我们将需要处理的任务,按其需要延迟处理时间作为 Score 加入到 ZSet 中。Redis 的 ZAdd 的时间复杂度是O(logN)
,N
是 ZSet 中元素个数,因此我们能相对比较高效的进行入队操作。起一个进程定时(比如每隔一秒)通过 ZREANGEBYSCORE
方法查询 ZSet 中 Score 最小的元素,具体操作为:ZRANGEBYSCORE KEY -inf +inf limit 0 1 WITHSCORES
。查询结果有两种情况: a. 查询出的分数小于等于当前时间戳,说明到这个任务需要执行的时间了,则去异步处理该任务; b. 查询出的分数大于当前时间戳,由于刚刚的查询操作取出来的是分数最小的元素,所以说明 ZSet 中所有的任务都还没有到需要执行的时间,则休眠一秒后继续查询; 同样的,ZRANGEBYSCORE
操作的时间复杂度为O(logN + M)
,其中N
为 ZSet 中元素个数,M
为查询的元素个数,因此我们定时查询操作也是比较高效的。
这里有一套网上比较优秀的延迟队列后端架构
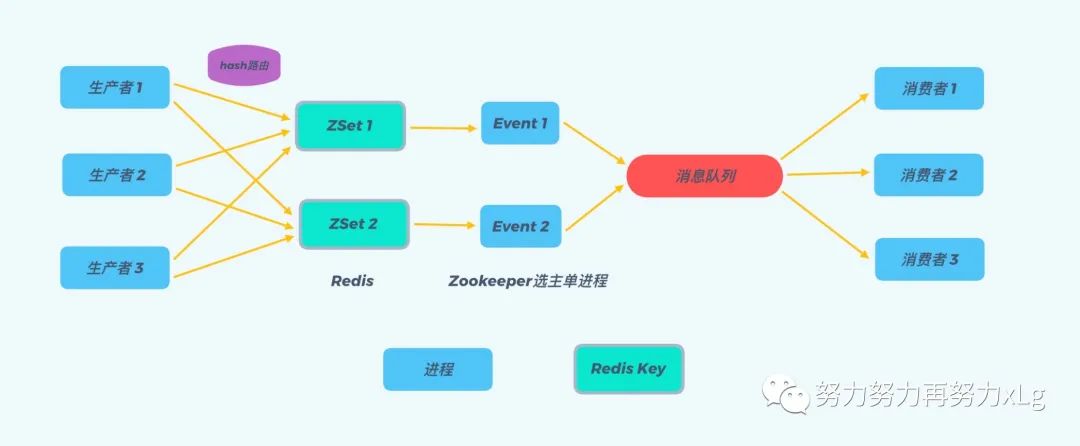
其核心设计思路:
将延迟的消息任务通过 hash 算法路由至不同的 Redis Key 上,这样做有两大好处: a. 避免了当一个 KEY 在存储了较多的延时消息后,入队操作以及查询操作速度变慢的问题(两个操作的时间复杂度均为 O(logN)
)。 b. 系统具有了更好的横向可扩展性,当数据量激增时,我们可以通过增加 Redis Key 的数量来快速的扩展整个系统,来抗住数据量的增长。每个 Redis Key 都对应建立一个处理进程,称为 Event 进程,通过上述步骤 2 中所述的 ZRANGEBYSCORE 方法轮询 Key,查询是否有待处理的延迟消息。 所有的 Event 进程只负责分发消息,具体的业务逻辑通过一个额外的消息队列异步处理,这么做的好处也是显而易见的: a. 一方面,Event 进程只负责分发消息,那么其处理消息的速度就会非常快,就不太会出现因为业务逻辑复杂而导致消息堆积的情况。 b. 另一方面,采用一个额外的消息队列后,消息处理的可扩展性也会更好,我们可以通过增加消费者进程数量来扩展整个系统的消息处理能力。 Event 进程采用 Zookeeper 选主单进程部署的方式,避免 Event 进程宕机后,Redis Key 中消息堆积的情况。一旦 Zookeeper 的 leader 主机宕机,Zookeeper 会自动选择新的 leader 主机来处理 Redis Key 中的消息。
从上述的讨论中我们可以看到,通过 Redis Zset 实现延迟队列是一种理解起来较为直观,可以快速落地的方案。并且我们可以依赖 Redis 自身的持久化来实现持久化,使用 Redis 集群来支持高并发和高可用,是一种不错的延迟队列的实现方案。
参考引用
2.1、基于Redis 实现的延迟队列
这里我是基于有赞延迟队列设计进行的代码落地!
其中有三个角色
Job Pool 用于存放所有的job的元信息,在Redis中是以Map的数据类型存储的 Delay Bucket 是一组以时间为维度的有序队列,用来存放所有需要延迟的/已经被reserve的Job(我只记录了JobId),一个有序队列 ZSet Ready Queue存放于Ready状态的Job(也是只存放Job Id),提供给消费者消费,则普通的list或者队列都行 能够满意以上丰富的数据类型,只有redis莫属了。
bucket的数据结构就是redis的zset,将其分为多个bucket是为了提高扫描速度,降低消息延迟。
设计不足的地方就是,timer 时间轮是由一个线程的无限循环中实现的,再没有Ready Job 的时候,非常消耗CPU性能。
整个代码运行的效果图
使用的技术栈:Spring Boot + Redis(其中使用了Jedis做客户端,Redisson实现各种分布式问题)+利索应当的使用的Spring 的Schedu实现时间轮。
代码:delay-queue
3、RabbitMQ
这是此次我们项目中敲定的一种实现方案,使用了RabbitMQ的死信队列+TTL来实现的延迟队列。并且在RabbitMQ的整体配置中,为了避免消息不丢失,不会重复消费等问题,我们将RabbitMQ设置为手动ACK模式,并且在确保RabbitMQ的消息可靠性,我们自定义了RabbitTemplate,将失败的信息记录到数据库,定时任务重发。
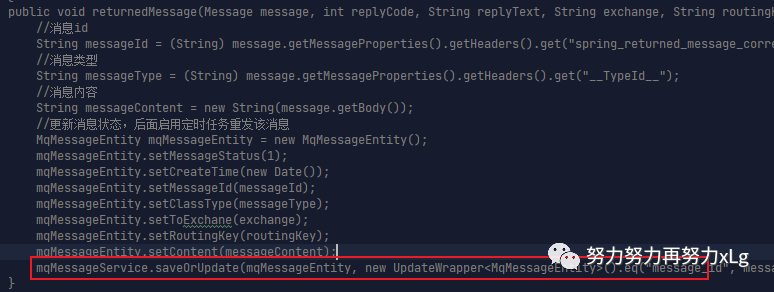
以上是一段伪代码。在消息没有正确抵达指定的队列时,进行回调。
如果消息正确到达指定的队列。将状态更新到数据库中。确保项目整体的健壮。
使用RabbitMQ实现延时队列,相对比较容易,只需要开始将一个队列的输出对象设置为一个新的队列,并且该队列不能有订阅者。既死信队列。并且在消息超时之后,消息会路由到指定的队列,那么当前队列的所有消费者将会进行消费,实现延迟队列的功能。
4、TimeWheel
TimeWheel时间轮算法,是一种实现延时队列的巧妙且高效的算法,Neety、Zookeeper、Kafka等框架都有应用
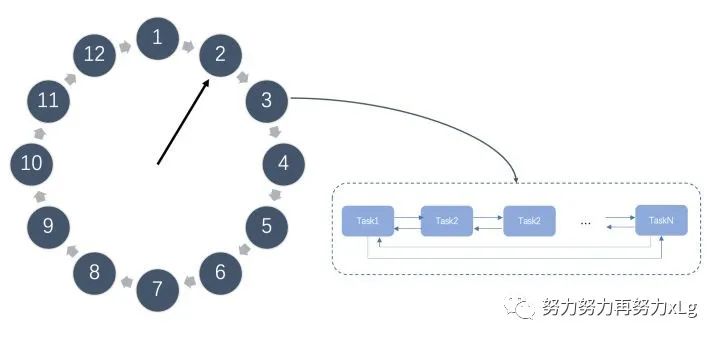
如上图所示,时间轮是一个存储延迟消息的环形队列,其底层采用数组实现,可以高效循环遍历。这个环形队列中的每个元素对应一个延迟任务列表,这个列表是一个双向环形链表,链表中每一项都代表一个需要执行的延迟任务。
时间轮会有表盘指针,表示时间轮当前所指时间,随着时间推移,该指针会不断前进,并处理对应位置上的延迟任务列表。
添加延迟任务
由于时间轮的大小固定,并且时间轮中每个元素都是一个双向环形链表,我们可以在O(1)
的时间复杂度下向时间轮中添加延迟任务。
如下图,例如我们有一个这样的时间轮,在表盘指针指向当前时间为 2 时,我们需要新添加一个延迟 3 秒的任务,我们可以快速计算出延迟任务在时间轮中所对应的位置为 5,并添加到位置 5 上任务列表尾部。
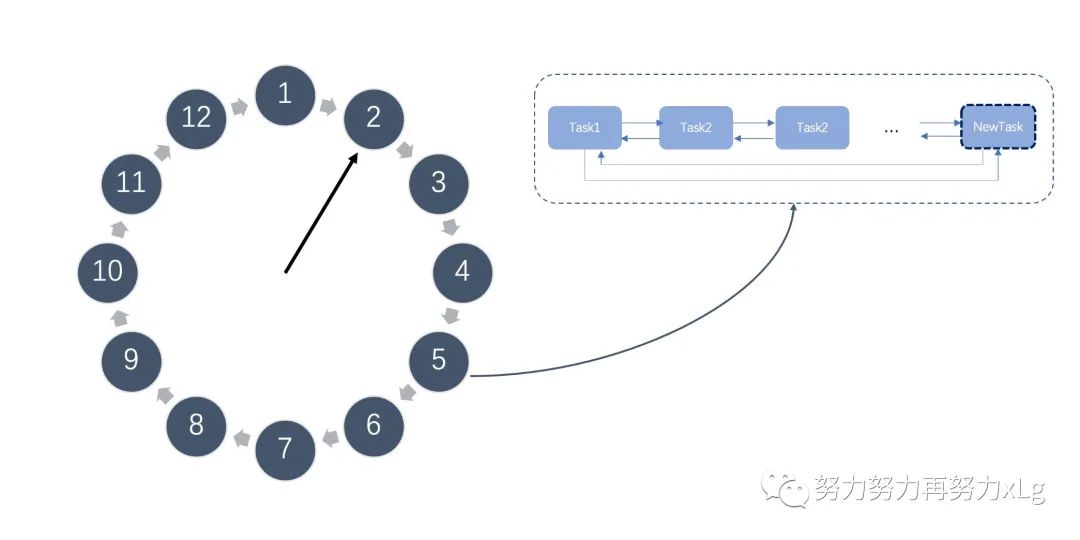
多层时间轮
到现在为止一切都非常棒,但是细心的同学可能发现了,上面的时间轮的大小是固定的,只有 12 秒。如果此时我们有一个需要延迟 200 秒的任务,我们应该怎么处理呢?直接扩充整个时间轮的大小吗?这显然不可取,因为这样做的话我们就需要维护一个非常非常大的时间轮,内存是不可接受的,而且底层数组大了之后寻址效率也会降低,影响性能。
为此,Kafka 引入了多层时间轮的概念。其实多层时间轮的概念和我们的机械表上时针、分针、秒针的概念非常类似,当仅使用秒针无法表示当前时间时,就使用分针结合秒针一起表示。同样的,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中,如下图所示: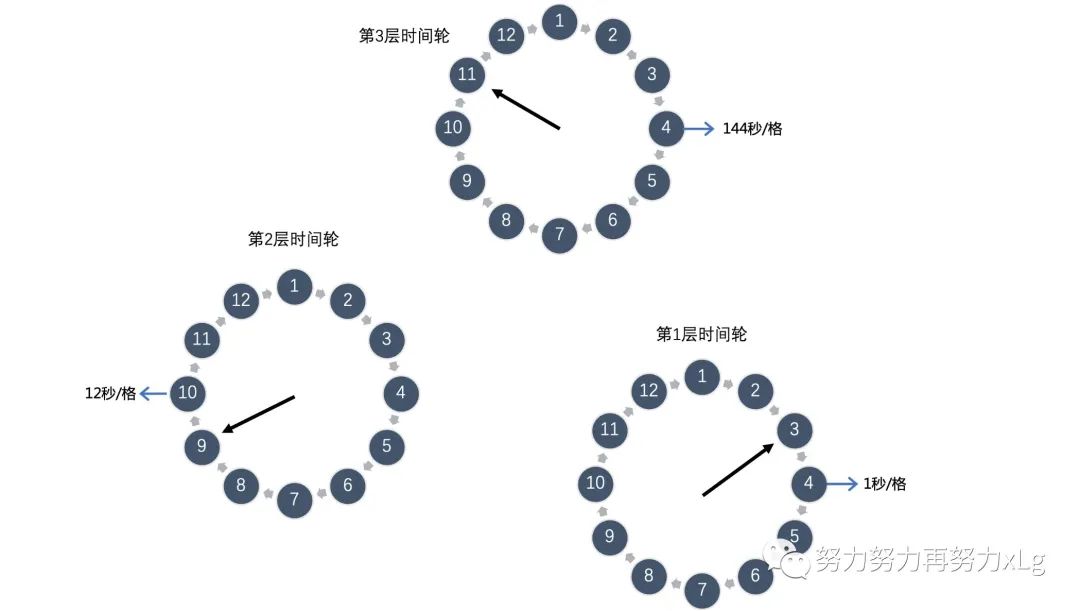
第一层时间轮整个时间轮所表示时间范围是 0-12 秒,第二层时间轮每格能表示的时间范围是整个第一层时间轮所表示的范围也就是 12 秒,所以整个第二层时间轮能表示的时间范围即 12*12=144 秒,依次类推第三层时间轮能表示的范围是 1728 秒,第四层为 20736 秒等等。
比如现在我们需要添加一个延时为 200 秒的延迟消息,我们发现其已经超过了第一层时间轮能表示的时间范围,我们就需要继续往上层时间轮看,将其添加在第二层时间轮 200/12 = 17 的位置,然后我们发现 17 也超过了第二次时间轮的表示范围,那么我们就需要继续往上层看,将其添加在第三层时间轮的 17/12 = 2 的位置。
Kafka 中时间轮算法添加延迟任务以及推动时间轮滚动的核心流程如下,其中 Bucket 即时间轮中的延迟任务队列,并且 Kafka 引入的 DelayQueue 解决了多数 Bucket 为空导致的时间轮滚动效率低下的问题:
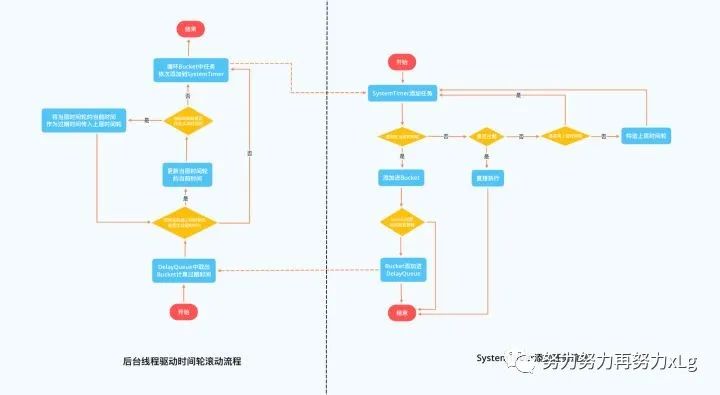
使用时间轮实现的延迟队列,能够支持大量任务的高效触发。并且在 Kafka 的时间轮算法的实现方案中,还引入了 DelayQueue,使用 DelayQueue 来推送时间轮滚动,而延迟任务的添加与删除操作都放在时间轮中,这样的设计大幅提升了整个延迟队列的执行效率。
总结
延迟队列在实际的开发业务中使用的非常广泛,以上三种实现方式从易到难。
redis 本身Redis是基于内存的,也有自己的持久化方案,但是还是会存在数据丢失的可能性 RabbitMQ 基于本身的消息可靠发送,消息可靠投递,死信队列等特性,实现消息至少被消费一次,以及未被正确处理的消息不会被丢弃,让消息的可靠性有了保障。 Kafka 其中的时间轮算法,比较隐晦难懂,TODO:做一个深入的探讨。(Netty底层的时间轮算法)
引用:
你真的知道怎么实现一个延迟队列吗 ?
基于Redis实现延时任务
