





一、图数据库工作流程
传统关系数据库在处理海量数据以及复杂网络问题上存在如下问题:模型构建复杂、海量关系与数据存储困难、复杂关系查询与分析效率低下、系统维护复杂、扩展性较差等,而图数据库则是处理关联关系的利器。首先,由于图数据库中存储的是带属性的实体与关系,能够更直接的表达现实世界,构建模型更容易。其次,图数据库可以高效的存储大量数据,总数据量可以达到百亿级。第三,在多层次、多关联查询方面,图数据库具有绝对的优势。
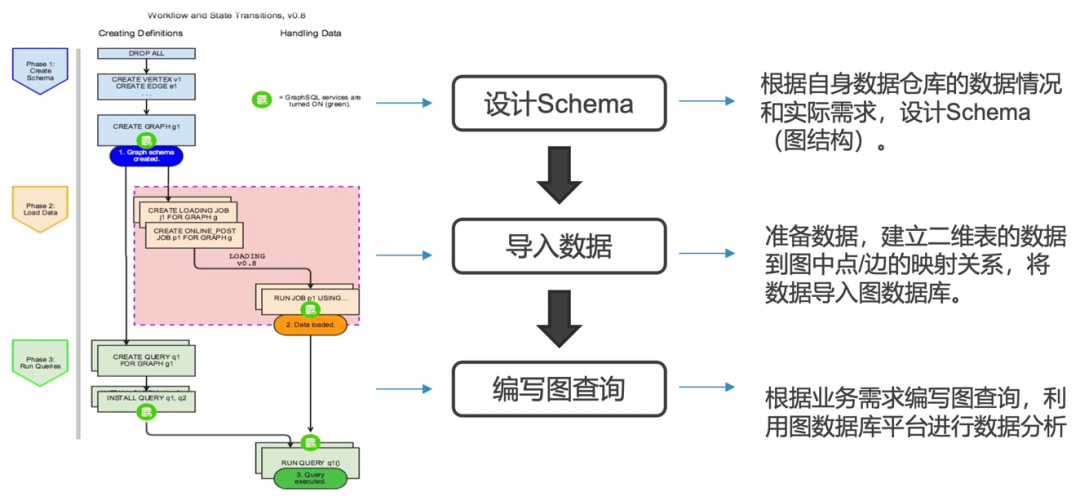
图数据库的工作流程
二、图数据库Neo4J安装与配置
1. 安装JDK:由于Neo4j是基于JAVA的图数据库,因此必须安装JAVA的JDK。在安装JDK时需要注意相关环境变量的配置,并使用java –version确定是否准确安装。
2. 安装Neo4j:安装neo4j并配置环境,同样需要注意环境变量的配置。并使用./neo4j start查看数据库是否正常打开。
3. Neo4j的config修改:使用sudo vim neo4j.conf打开Neo4j的配置文件,对其中的部分内容进行修改,使得后续的工作可以正常进行。包括CSV导入、网络设置、数据库名称修改等。
4. 重新启动Neo4j
三、数据导入
1. LOAD CSV语句:LOAD CSV可支持本地以及远程文件的导入,支持初始化导入以及增量更新。缺点是导入速度较慢、数据导入数量较小,当节点数量超过10万,导入效果会急速降低。
2. CREATE语句:CREATE语句可以实时插入数据、使用方便。缺点是处理速度慢、数据处理量不超过1万。
3. NEO4J-IMPORT语句:Neo4j-import语句可以支持本地和远程文件的导入,支持初始化导入。该语句的优势是数据导入量较大、导入数据速度快、效率高。缺点是在导入过程中需要停止Neo4j,并且不能在已存在的数据库中进行导入。
四、图Schema设计
构建监控资金流向系统中最重要的环节就是将业务系统知识转换为数据模型,好的Schema 设计可以准确、清晰的将业务知识展现出来。因此,图Schema的设计必须要业务人员与工程师共同参与。在设计Schema 的过程中,工程师与业务人员要进行多轮迭代,直到两者达到共识。具体的设计内容包括:
1. 顶点设计:该步骤包括顶点类型以及顶点属性设计。顶点属性可以从可检索、易可视化、易查询、更高效等方面去考虑。同时,为了避免超级节点的产生,需要避免从这些节点出发进行查询。
2. 边的设计:Neo4j中边表示两个实体之间的关系,建立何种类型的边、边是单向还是双向、无方向等,这些都需要业务与工程师仔细沟通。由于许多关系是自关联的,会使得许多实体之间存在多重关系,使得查询的效率较低或者遗漏。
3. 业务场景的设计:许多业务场景存在不同的Schema设计,有的顶点在某一个Schema中为顶点,而在另一个Schema中则是关系。因此,需要设计出合理的业务场景以及相对应的Schema,使得设计出的Schema具有更高效的查询效果。
五、验证与测试
当完成上述功能后,我们需要去验证和测试相关数据,主要包括以下内容:
1. 数据准确性:首先需要验证导入数据库中的数据是否以预期数据相同,包括数量、属性、关系、顶点等。
2. 是否符合业务需求:通过查询语句判断导入的数据与业务部门的需求是否一致。
3. 算法结果是否符合需求:算法计算出的结果通过与实际结果进行对比,如果结果不符合需求则需要修改算法参数或更换其他算法。
4. 性能测试:完成所有工作后需要做性能测试判断构建的数据库和算法在性能上是否能达到标准。
六、运维监控
运维监控是保证系统正常健康运营的基础,运维人员的主要工作包括:
1. 容量监控:由于数据库运行是一个实时的过程,新的数据导入随时都会发生。为了防止数据遗漏或者数据缺损,运维管理人员需要不定时的检查数据容量是否存在不足,如果数据存在疏漏则需要进行填补。
2. 扩容监控:当数据库中存在计算能力与数据容量不足时,运维人员需要及时进行扩容,已满业务的需求。
3. 负载均衡监控:在分布式数据库中,有时会存在数据不均衡现象,不同节点的负载容量存在较大差异。这时需要运维人员将负载较重的数据转移到负载较低的数据节点,使得业务不受到较大影响。
4. 数据备份与恢复:对于重要的数据,运维人员需要周期性的进行数据备份以防止事故发生后,不造成较大的损失。
5. 去除毛刺:由于图数据的特殊性,每次查询请求的性能取决这次查询遍历的总边数。
