







了解图数据库系列之
异常交易识别
RegTech 未来
。。。。。。
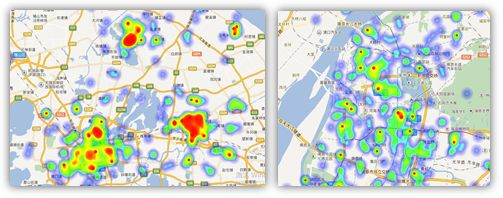
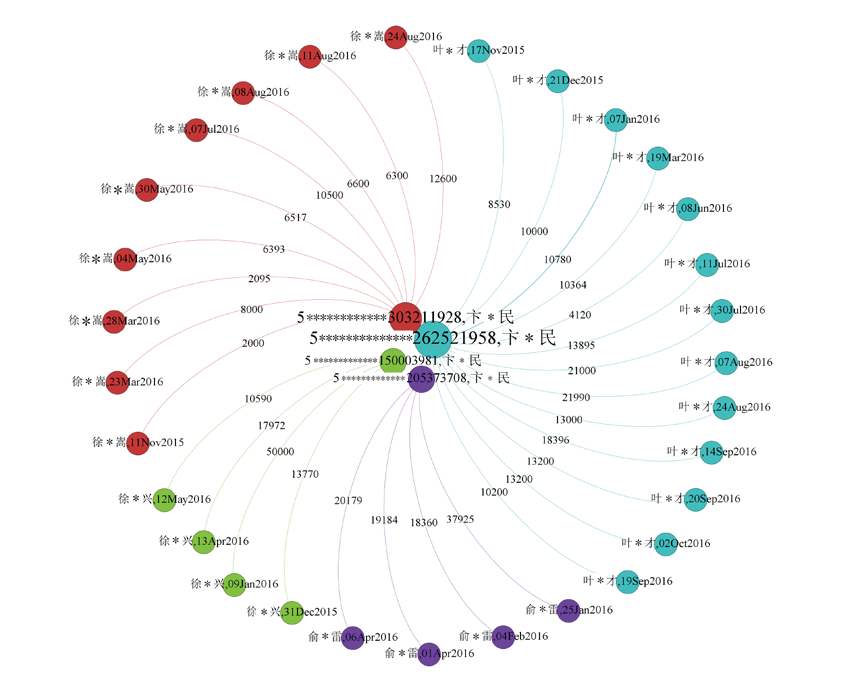
以新技术与海量数据为驱动的风险管理的模式已经得到快速发展,但在实际的风险管理中,互联网客户的欺诈行为也较为严重,其中比较突出的现象之一,是以贷款归集现象为表现的异常交易行为,为商业银行的风险管理带来了新的挑战。
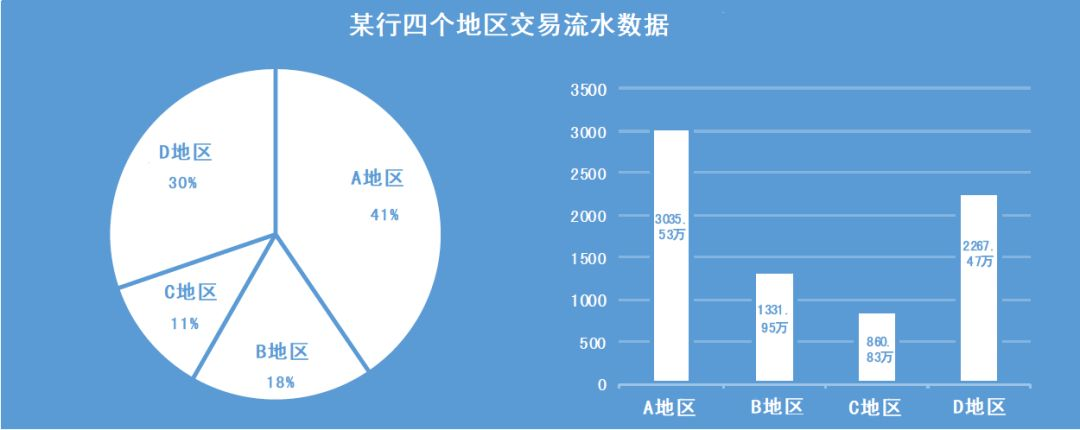
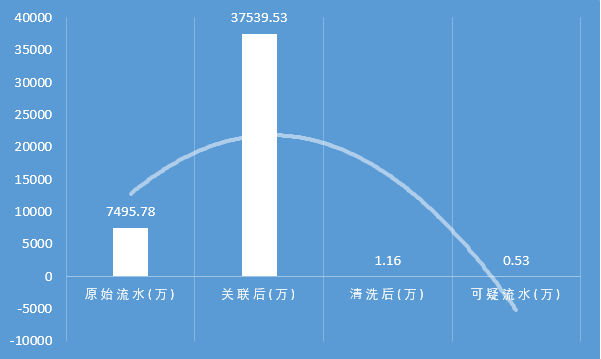
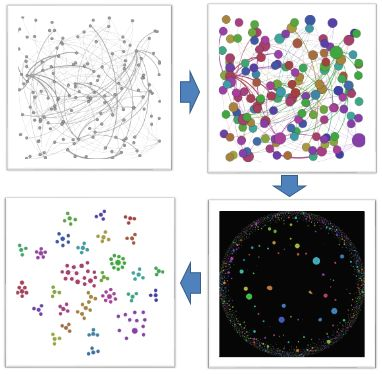
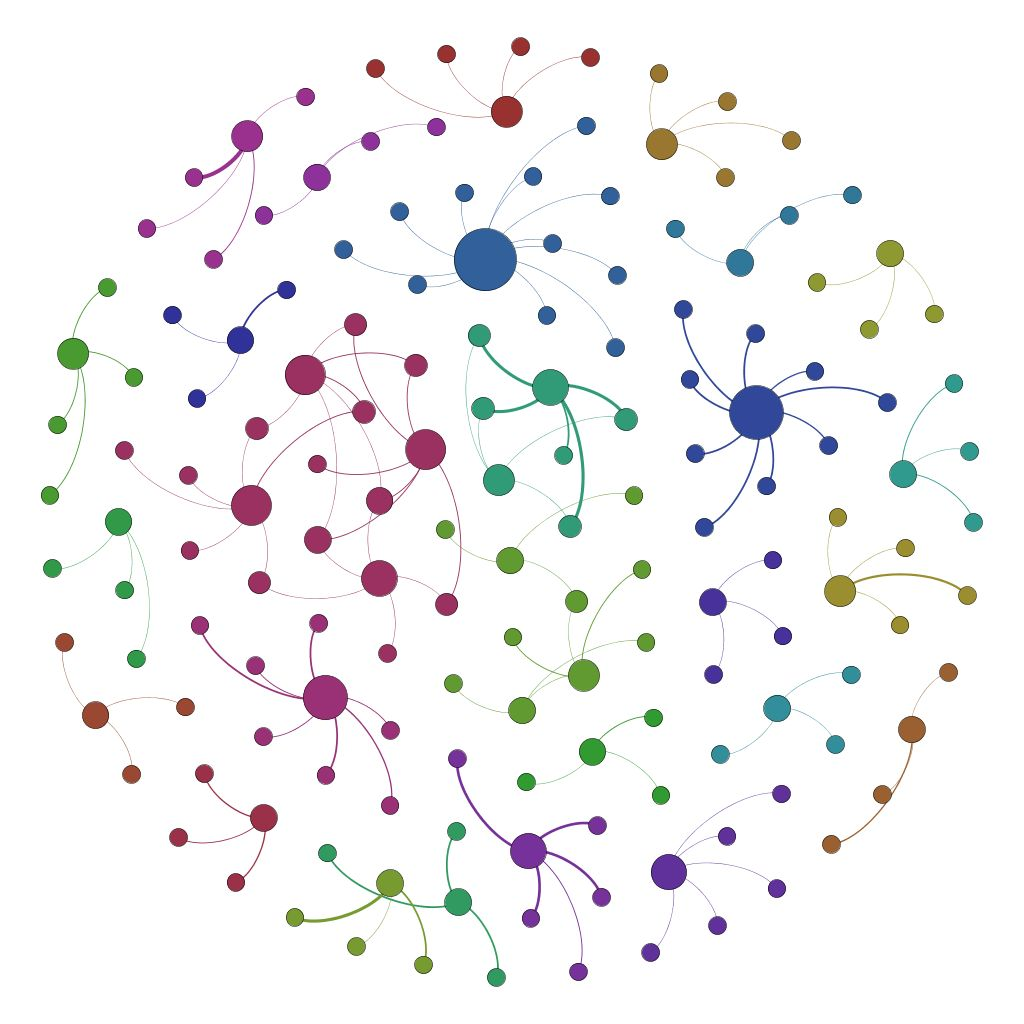
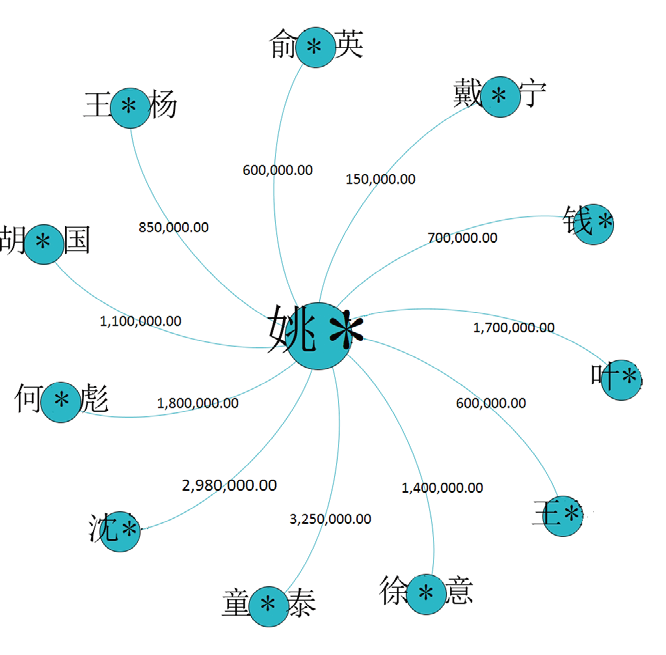
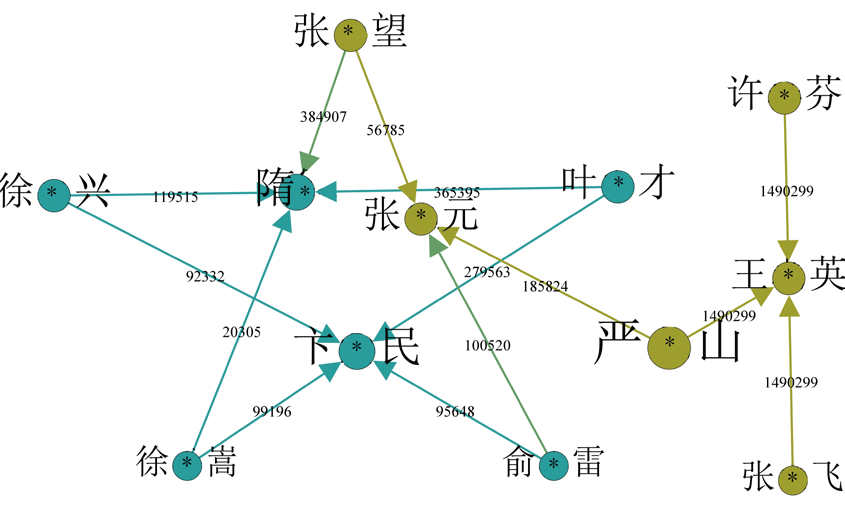
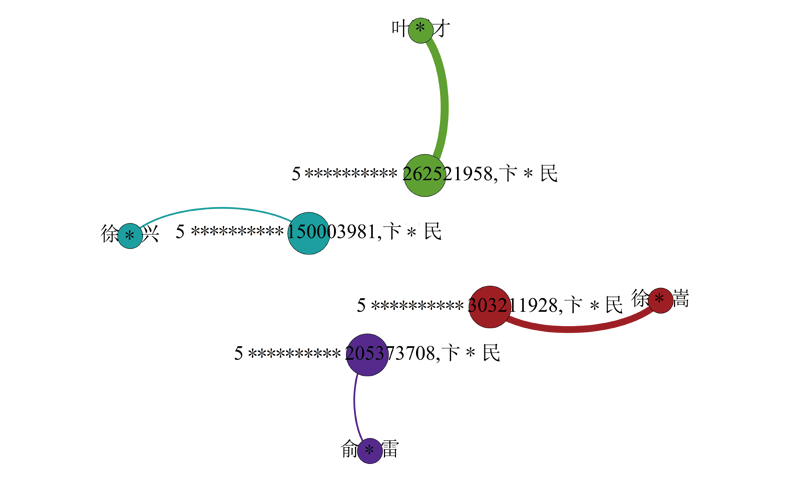
如何从海量的数据中筛选出异常交易的数据呢?异常交易的突出特征是资金的异常归集行为,通过挖掘海量的数据中蕴含的特征信息,对人工分析难以捕捉的价值信息进行自动化识别,可提高精确识别能力。



RegTech 未来
文章转载自RegTech未来,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
