




Kubernetes深入了解Pod
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是Pod,Pod是最小的,管理,创建,计划的最小单元。
1、yaml格式的Pod配置文件内容及注解
深入Pod之前,首先我们来了解下Pod的yaml整体文件内容及功能注解。
如下:
|
2、Pod基本用法:
在使用docker时,我们可以使用docker run命令创建并启动一个容器,而在Kubernetes系统中对长时间运行的容器要求是:其主程序需要一直在前台运行。如果我们创建的docker镜像的启动命令是后台执行程序,例如Linux脚本:
nohup ./startup.sh &
则kubelet创建包含这个容器的pod后运行完该命令,即认为Pod执行结束,之后根据RC中定义的pod的replicas副本数量生产一个新的pod,而一旦创建出新的pod,将在执行完命令后陷入无限循环的过程中,这就是Kubernetes需要我们创建的docker镜像以一个前台命令作为启动命令的原因。
对于无法改造为前台执行的应用,也可以使用开源工具supervisor辅助进行前台运行的功能。
****Pod可以由一个或多个容器组合而成
例如:两个容器应用的前端frontend和redis为紧耦合的关系,应该组合成一个整体对外提供服务,则应该将这两个打包为一个pod.
配置文件frontend-localredis-pod.yaml如下:
|
属于一个Pod的多个容器应用之间相互访问只需要通过localhost就可以通信,这一组容器被绑定在一个环境中。
使用kubectl create创建该Pod后,get Pod信息可以看到如下图:
#kubectl get gods NAME READY STATUS RESTATS AGE redis-php 2/2Running 0 10m |
可以看到READY信息为2/2,表示Pod中的两个容器都成功运行了.
查看pod的详细信息,可以看到两个容器的定义和创建过程。
|
3、静态Pod
静态pod是由kubelet进行管理的仅存在于特定Node的Pod上,他们不能通过APIServer进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对他们进行健康检查。静态Pod总是由kubelet进行创建,并且总是在kubelet所在的Node上运行。
创建静态Pod有两种方式:配置文件或者HTTP方式
1)配置文件方式
首先,需要设置kubelet的启动参数"--config",指定kubelet需要监控的配置文件所在的目录,kubelet会定期扫描该目录,冰根据目录中的 .yaml或 .json文件进行创建操作
假设配置目录为/etc/kubelet.d/配置启动参数:--config=/etc/kubelet.d/,然后重启kubelet服务后,再宿主机受用docker ps或者在Kubernetes Master上都可以看到指定的容器在列表中
由于静态pod无法通过API Server直接管理,所以在master节点尝试删除该pod,会将其变为pending状态,也不会被删除
#kubetctl delete pod static-web-node1 pod "static-web-node1"deleted #kubectl get pods NAME READY STATUS RESTARTS AGE static-web-node1 0/1Pending 0 1s |
要删除该pod的操作只能在其所在的Node上操作,将其定义的.yaml文件从/etc/kubelet.d/目录下删除
#rm -f etc/kubelet.d/static-web.yaml #docker ps |
4、Pod容器共享Volume
Volume类型包括:emtyDir、hostPath、gcePersistentDisk、awsElasticBlockStore、gitRepo、secret、nfs、scsi、glusterfs、persistentVolumeClaim、rbd、flexVolume、cinder、cephfs、flocker、downwardAPI、fc、azureFile、configMap、vsphereVolume等等,可以定义多个Volume,每个Volume的name保持唯一。在同一个pod中的多个容器能够共享pod级别的存储卷Volume。Volume可以定义为各种类型,多个容器各自进行挂载操作,讲一个Volume挂载为容器内需要的目录。
如下图:

如上图中的Pod中包含两个容器:tomcat和busybox,在pod级别设置Volume “app-logs”,用于tomcat想其中写日志文件,busybox读日志文件。
配置文件如下:
apiVersion:v1 kind: Pod metadata: name: redis-php label: name: volume-pod spec: containers: - name: tomcat image: tomcat ports: - containersPort: 8080 volumeMounts: - name: app-logs mountPath:/usr/local/tomcat/logs - name: busybox image:busybox command: ["sh","-C","tail -f logs/catalina*.log"] volumes: - name: app-logs emptyDir:{} |
busybox容器可以通过kubectl logs查看输出内容
#kubectl logs volume-pod -c busybox |
tomcat容器生成的日志文件可以登录容器查看
#kubectl exec -ti volume-pod -c tomcat -- ls usr/local/tomcat/logs |
5.Pod的配置管理
应用部署的一个最佳实践是将应用所需的配置信息于程序进行分离,这样可以使得应用程序被更好的复用,通过不用配置文件也能实现更灵活的功能。将应用打包为容器镜像后,可以通过环境变量或外挂文件的方式在创建容器时进行配置注入。ConfigMap是Kubernetes v1.2版本开始提供的一种统一集群配置管理方案。
5.1 ConfigMap:容器应用的配置管理
容器使用ConfigMap的典型用法如下:
(1)生产为容器的环境变量。
(2)设置容器启动命令的启动参数(需设置为环境变量)。
(3)以Volume的形式挂载为容器内部的文件或目录。
ConfigMap以一个或多个key:value的形式保存在Kubernetes系统中共应用使用,既可以用于表示一个变量的值,也可以表示一个完整的配置文件内容。
通过yuaml配置文件或者直接使用kubelet create configmap 命令的方式来创建ConfigMap
5.2 ConfigMap的创建
举个小例子cm-appvars.yaml来描述将几个应用所需的变量定义为ConfigMap的用法:
# vim cm-appvars.yaml apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir:/var/data |
执行kubectl create命令创建该ConfigMap
#kubectl create -f cm-appvars.yaml configmap "cm-appvars.yaml"created |
查看建立好的ConfigMap:
#kubectl get configmap NAME DATA AGE cm-appvars 2 3s [root@kubernetes-master ~]# kubectl describe configmap cm-appvars Name: cm-appvars Namespace: default Labels: <none> Annotations: <none>
Data ==== appdatadir: 9 bytes apploglevel: 4 bytes [root@kubernetes-master ~]# kubectl get configmap cm-appvars -o yaml apiVersion: v1 data: appdatadir: /var/data apploglevel: info kind: ConfigMap metadata: creationTimestamp: 2017-04-14T06:03:36Z name: cm-appvars namespace: default resourceVersion:"571221" selfLink: /api/v1/namespaces/default/configmaps/cm-appvars uid: 190323cb-20d8-11e7-94ec-000c29ac8d83 |
另:创建一个cm-appconfigfile.yaml描述将两个配置文件server.xml和logging.properties定义为configmap的用法,设置key为配置文件的别名,value则是配置文件的文本内容:
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: key-serverxml: <?xml Version='1.0'encoding='utf-8'?> <Server port="8005"shutdown="SHUTDOWN"> ..... </service> </Server> key-loggingproperties: "handlers=lcatalina.org.apache.juli.FileHandler, ...." |
在pod "cm-test-app"定义中,将configmap"cm-appconfigfile"中的内容以文件形式mount到容器内部configfiles目录中。
Pod配置文件cm-test-app.yaml内容如下:
#vim cm-test-app.yaml
|
创建该Pod:
#kubectl create -f cm-test-app.yaml Pod "cm-test-app"created |
登录容器查看configfiles目录下的server.xml和logging.properties文件,他们的内容就是configmap“cm-appconfigfile”中定义的两个key的内容
#kubectl exec -ti cm-test-app -- bash root@cm-rest-app:/# cat configfiles/server.xml root@cm-rest-app:/# cat configfiles/logging.properties |
5.3使用ConfigMap的条件限制
使用configmap的限制条件如下:
configmap必须在pod之间创建
configmap也可以定义为属于某个Namespace,只有处于相同namespaces中的pod可以引用configmap中配额管理还未能实现;kubelet只支持被api server管理的pod使用configmap,静态pod无法引用在pod对configmap进行挂载操作时,容器内部职能挂载为目录,无法挂载文件。
6.Pod生命周期和重启策略
Pod在整个生命周期过程中被定义为各种状态,熟悉Pod的各种状态有助于理解如何设置Pod的调度策略、重启策略
Pod的状态包含以下几种,如图:
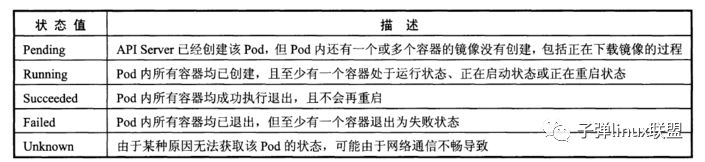
Pod的重启策略(RestartPolicy)应用于Pod内所有的容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某哥容器异常退出或者健康检查石柏师,kubelet将根据RestartPolicy的设置进行相应的操作
Pod的重启策略包括Always、OnFailure及Nerver,默认值为Always。
kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5分钟,并且成功重启后的10分钟后重置该事件。
Pod的重启策略和控制方式息息相关,当前可用于管理Pod的控制器宝库ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod),每种控制器对Pod的重启策略要求如下:
RC和DaemonSet:必须设置为Always,需要保证该容器持续运行
Job:OnFailure或Nerver,确保容器执行完成后不再重启
kubelet:在Pod失效时重启他,不论RestartPolicy设置什么值,并且也不会对Pod进行健康检查
7、Pod健康检查
对Pod的健康检查可以通过两类探针来检查:LivenessProbe和ReadinessProbe
LivenessProbe探针:用于判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,则kubelet杀掉该容器,并根据容器的重启策略做响应处理
ReadinessProbe探针:用于判断容器是否启动完成(ready状态),可以接受请求。如果ReadinessProbe探针探测失败,则Pod的状态被修改。Endpoint Controller将从service的Endpoint中删除包含该容器所在的Pod的Endpoint。
kubelet定制执行LivenessProbe探针来诊断容器的健康状况。LivenessProbe有三种事项方式。
(1)ExecAction:在容器内部执行一个命令,如果该命令的返回值为0,则表示容器健康
例:
a
|
(2)TCPSocketAction:通过容器ip地址和端口号执行TCP检查,如果能够建立tcp连接表明容器健康
例:
|
(3)HTTPGetAction:通过容器Ip地址、端口号及路径调用http get方法,如果响应的状态吗大于200且小于400,则认为容器健康
例:
|
对于每种探针方式,都需要设置initialDelaySeconds和timeoutSeconds两个参数,它们含义如下:
initialDelaySeconds:启动容器后首次监控检查的等待时间,单位秒
timeouSeconds:健康检查发送请求后等待响应的超时时间,单位秒。当发生超时就被认为容器无法提供服务无,该容器将被重启
8.玩转Pod调度
在Kubernetes系统中,Pod在大部分场景下都只是容器的载体而已,通常需要通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度和自动控制功能。
8.1 RC、Deployment:全自动调度
RC的主要功能之一就是自动部署容器应用的多份副本,以及持续监控副本的数量,在集群内始终维护用户指定的副本数量。
在调度策略上,除了使用系统内置的调度算法选择合适的Node进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node进行调度。
1)NodeSelector:定向调度
Kubernetes Master上的scheduler服务(kube-Scheduler进程)负责实现Pod的调度,整个过程通过一系列复杂的算法,最终为每个Pod计算出一个最佳的目标节点,通常我们无法知道Pod最终会被调度到哪个节点上。实际情况中,我们需要将Pod调度到我们指定的节点上,可以通过Node的标签和pod的nodeSelector属性相匹配来达到目的。
(1)首先通过kubectl label命令给目标Node打上标签
kubectllabel nodes <node-name> <label-key>=<label-value>
例:
#kubectllabel nodes k8s-node-1 zonenorth |
(2)然后在Pod定义中加上nodeSelector的设置
例:
|
运行kubectl create -f命令创建Pod,scheduler就会将该Pod调度到拥有zone=north标签的Node上。 如果多个Node拥有该标签,则会根据调度算法在该组Node上选一个可用的进行Pod调度。
需要注意的是:如果集群中没有拥有该标签的Node,则这个Pod也无法被成功调度。
2)NodeAffinity:亲和性调度
该调度策略是将来替换NodeSelector的新一代调度策略。由于NodeSelector通过Node的Label进行精确匹配,所有NodeAffinity增加了In、NotIn、Exists、DoesNotexist、Gt、Lt等操作符来选择Node。调度侧露更加灵活。
8.2 DaemonSet:特定场景调度
DaemonSet用于管理集群中每个Node上仅运行一份Pod的副本实例,如图
这种用法适合一些有下列需求的应用:
在每个Node上运行个以GlusterFS存储或者ceph存储的daemon进程
在每个Node上运行一个日志采集程序,例如fluentd或者logstach
在每个Node上运行一个健康程序,采集Node的性能数据。
DaemonSet的Pod调度策略类似于RC,除了使用系统内置的算法在每台Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围来进行调度。
8.3 批处理调度
9.Pod的扩容和缩荣
在实际生产环境中,我们经常遇到某个服务需要扩容的场景,也有可能因为资源精确需要缩减资源而需要减少服务实例数量,此时我们可以Kubernetes中RC提供scale机制来完成这些工作。
以redis-slave RC为例,已定义的最初副本数量为2,通过kubectl scale命令可以将Pod副本数量重新调整
#kubectl scale rc redis-slave --replicas=3 ReplicationController"redis-slave" scaled #kubectl get pods NAME READY STATUS RESTARTS AGE redis-slave-1sf23 1/1Running 0 1h redis-slave-54wfk 1/1Running 0 1h redis-slave-3da5y 1/1Running 0 1h |
除了可以手工通过kubectl scale命令完成Pod的扩容和缩容操作以外,新版本新增加了Horizontal Podautoscaler(HPA)的控制器,用于实现基于CPU使用路进行启动Pod扩容缩容的功能。该控制器基于Mastger的kube-controller-manager服务启动参数--horizontal-pod-autoscler-sync-period定义的时长(默认30秒),周期性监控目标Pod的Cpu使用率并在满足条件时对ReplicationController或Deployment中的Pod副本数量进行调整,以符合用户定义的平均Pod Cpu使用率,Pod Cpu使用率来源于heapster组件,所以需预先安装好heapster。
10.Pod的滚动升级
当集群中的某个服务需要升级时,我们需要停止目前与该服务相关的所有Pod,然后重新拉取镜像并启动。如果集群规模较大,因服务全部停止后升级的方式将导致长时间的服务不可用。由此,Kubernetes提供了rolling-update(滚动升级)功能来解决该问题。
滚动升级通过执行kubectl rolling-update命令一键完成,该命令创建一个新的RC,然后自动控制旧版本的Pod数量逐渐减少到0,同时新的RC中的Pod副本数量从0逐步增加到目标值,最终实现Pod的升级。需要注意的是,系统要求新的RC需要与旧的RC在相同的Namespace内,即不能把别人的资产转到到自家名下。
例:将redis-master从1.0版本升级到2.0
|
需要注意的点:
(1)RC的name不能与旧的RC名字相同
(2)在sele中应至少有一个label与旧的RC的label不同,以标识为新的RC。本例中新增了一个名为version的label与旧的RC区分
运行kubectl rolling-update来完成Pod的滚动升级:
#kubectl rolling-update redis-master -f redis-master-controller-v2.yaml |
另一种方法就是不使用配置文件,直接用kubectl rolling-update加上--image参数指定新版镜像名来完成Pod的滚动升级
#kubectl rolling-update redis-master --image=redis-master:2.0 |
与使用配置文件的方式不同的是,执行的结果是旧的RC被删除,新的RC仍然使用就的RC的名字。
如果在更新过程总发现配置有误,则用户可以中断更新操作,并通过执行kubectl rolling-update-rollback完成Pod版本的回滚。
