




最近在统计程序执行时长时发现程序的用户态时间和内核态时间竟然比实际执行时间还要长。看着time执行的结果,不知道到底哪个才是对的。
real 90m1.302suser 230m40.740ssys 127m54.292s
上面的程序输出结果可以使用下面两种方式获得:
$ time python3 pp.py$ usr/bin/time -p python3 pp.py
我们埋下两个问题,带着问题来找答案
直接执行time和使用绝对路径加参数执行,这两种方式有区别吗?
user 和 sys 比 real 还要大,难道 real 不是最终执行时长?按以前的习惯,real 一般比 user 和 sys 要大,出现上面的结果,一时不知道哪个才是真正需要统计的时长
直接执行time和执行/usr/bin/time -p的输出结果是一样的,可以理解它们的工作原理是一样的,但它们本身不是一个东西。
time 是 shell 中的一个关键字,可以理解成shell内置模块。可以使用type查看time的属性。
(base) root@it:~# type timetime is a shell keyword(base) root@it:~# which time/usr/bin/time(base) root@it:~# file usr/bin/time/usr/bin/time: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=60033044eb07a8df62bfb048ca13779990677416, stripped(base) root@it:~# type typetype is a shell builtin
我们可以查看bash的文档,并且可以找到bash中关于time使用相关的描述
(base) root@it:~# man bash
使用timeformat关键词搜索,可以查看time格式定制的部分
TIMEFORMATThe value of this parameter is used as a format string specify‐ing how the timing information for pipelines prefixed with thetime reserved word should be displayed. The % character intro‐duces an escape sequence that is expanded to a time value orother information. The escape sequences and their meanings areas follows; the braces denote optional portions.%% A literal %.%[p][l]R The elapsed time in seconds.%[p][l]U The number of CPU seconds spent in user mode.%[p][l]S The number of CPU seconds spent in system mode.%P The CPU percentage, computed as (%U + %S) %R.The optional p is a digit specifying the precision, the numberof fractional digits after a decimal point. A value of 0 causesno decimal point or fraction to be output. At most three placesafter the decimal point may be specified; values of p greaterthan 3 are changed to 3. If p is not specified, the value 3 isused.The optional l specifies a longer format, including minutes, ofthe form MMmSS.FFs. The value of p determines whether or notthe fraction is included.If this variable is not set, bash acts as if it had the value$'\nreal\t%3lR\nuser\t%3lU\nsys\t%3lS'. If the value is null,no timing information is displayed. A trailing newline is addedwhen the format string is displayed.
我们来简化一下,bash自带的time的执行可以通过TIMEFORMAT变量来控制。在什么都不做的情况下,TIMEFORMAT所使用的变量值就是$'\nreal\t%3lR\nuser\t%3lU\nsys\t%3lS',我们可以通过调整变量来控制显示样式。从man文档中,我们也可以看到这三个时间的定义。
real 实际程序执行时间,也就是我们说的花了多久程序才结束
user 程序在用户态的时间
sys 程序在内核态的时间
因为我们最关心的是实际执行时间,所以我们可以对TIMEFORMAT变量进行定制来缩短显示内容,我们用例子来说明一下怎么用:
# TIMEFORMAT=$'\nreal\t%3lR'# time pwd/rootreal 0m0.000s
可以看到我们通过改变变量TIMEFORMAT的值,time输出变短了,当前只显示real 即实际执行时间。我们再看一下这几个值在文档中的定义:
%% A literal %.%[p][l]R The elapsed time in seconds.%[p][l]U The number of CPU seconds spent in user mode.%[p][l]S The number of CPU seconds spent in system mode.%P The CPU percentage, computed as (%U + %S) %R.
我们只关心第二行,实际执行时间的值由%3lR来控制,其中R代表了实际执行时间,U代表用户态时间,S代表内核态时间,pl代表以float类型来显示时长。p的值在0-3之间,用于控制精度,我们把格式和输出集中一下给大家看下控制效果:
# TIMEFORMAT=$'实际执行时间:%0lR' ; time echo实际执行时间:0m0s# TIMEFORMAT=$'实际执行时间:%1lR' ; time echo实际执行时间:0m0.0s# TIMEFORMAT=$'实际执行时间:%2lR' ; time echo实际执行时间:0m0.00s# TIMEFORMAT=$'实际执行时间:%3lR' ; time echo实际执行时间:0m0.000s# TIMEFORMAT=$'实际执行时间:%lR' ; time echo实际执行时间:0m0.000s
输出的格式是 MMmSS.FFFs,即 分:秒.毫秒,最大精度是千分之一秒,即毫秒。当p的值为0时,精度为秒,p的值最大为3即精度为毫秒,默认精度为毫秒,也就是说p可以不写,当然也可以写成3,大于3无效。
常用时间单位换算
1 纳秒 = 1000皮秒
1,000 纳秒 = 1微秒 μs
1,000,000 纳秒 = 1毫秒 ms
1,000,000,000 纳秒 = 1秒
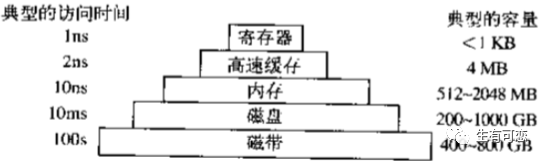
比较老的计算机组成原理书本上给出来的访问硬件所使用的时间数量级关系如下,仅作参考:
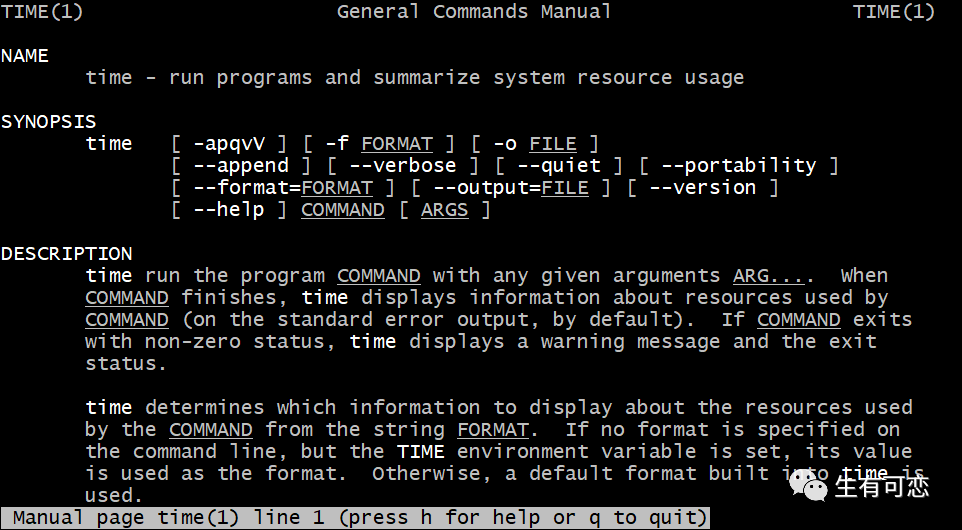
对于/usr/bin/time这个二进制文件,它不是shell内置keyword,它是一个程序。它有完整的man文档,我们查一下它的文档。
它比shell自带的time要复杂,可以干很多活,甚至可以查内存占用,但在这儿我们只对它时间统计的部分感兴趣。它可以用 -p 来兼容 bash 的 time 输出格式,也可以通过 TIME 变量来定制格式,或者通过 -f 指定格式。我们把文档摘出来,就不多说了。
-p, --portabilityUse the following format string, for conformance with POSIXstandard 1003.2:real %euser %Usys %SDemo:time -f "\t%E real,\t%U user,\t%S sys" ls -Fsexport TIME="\t%E,\t%k" ; time ls -Fs
第一个问题已经解释清楚了,第二个问题是关于数字的,当程序执行完,我看到这个时间统计时以为自己看错了。
real 90m1.302suser 230m40.740ssys 127m54.292s
real 是实际执行时间,也就是我们可以通过掐表算出来的时间。但后面两个时间为什么会比实际时间还要大?
real 实际程序执行时间,也就是我们说的花了多久程序才结束
user 程序在用户态的时间
sys 程序在内核态的时间
user 是用户态,sys是内核态,先不管是用户态还是内核态,为什么它们俩随便一个都比实际大?我查了文档,应该是出在多核上。
https://blog.csdn.net/q_l_s/article/details/54897684
作者:剑西楼 理解linux time命令的输出
单核程序执行可以简单理解 real ≥ user + sys
多核相当于干活的人多了,活干的更快了,用时当然更少了。但干活的人总花掉的时间增加了,相当于一个人需要干1天的活儿用十个人干,半天就干完了,但十个人一共花了合计5天的时长,每个人都干了半天的活。
再比如三十多个人开会,领导站在上面讲话,大家要按时到,每人节约一分钟,大家就节约出半个小时出来了。听起来好像很有道理,感觉大家的时间加起来,一年就变成了三十年。我们一年可以干一个人需要三十年才能干完的活,是不是超级震撼。但实际这种事并不存在,和CPU一样大部分时候都在空转,你有本事让CPU跑起来,这个时间才是有效的。
干一件事并不是人越多,活干的就越快。放在程序的世界里,就算是多线程,也不一定可以做到十个核总运行时长缩小十倍,也可能就只是缩小了一倍,虽然干活的CPU变成十个了,但IO等待、网络带宽以及十个核之间的任务切换、调度变复杂了,其它资源并没有增加,以前是一个人等,再在换成十个人等。
同样,如果出现 user + sys > real 的情况,只说明这个程序是多线程或多进程的,可以在多个核上跑。默认我们不会关心程序在哪个核上跑,如果想看可以用ps看。
ps -o pid,psr,comm -p <pid>
其中 psr 列 就是当前程序所在的核。
http://www.embeddedlinux.org.cn/html/xinshourumen/201601/30-5013.html
网站:ENBEDDED LINUX 判断Linux进程在哪个CPU核运行的4个方法
最后再说用户态和内核态
我们简单地理解用户态和内核态就是用户自己写的程序或函数就跑在用户态,如果是操作系统提供的功能就是内核态。
内核态主要针对用户无法操作的硬件部分,比如内存分配、中断处理。而系统调用则是用户操作底层硬件的唯一入口。
系统调用可以理解成一组操作硬件的汇编代码,以中断的形式让CPU执行。在DOS时代,可以通过写汇编就直接操作中断或系统调用。而到了现代操作系统,比如Linux,系统调用则是由Linux内核进行实现,因为Linux内核启动时,由实模式切换到了保护模式。也就是说只有Linux内核有权限执行相应的汇编代码,而用户态程序是不能直接像DOS一样直接调用系统调用。
也就是说以前在DOS时可以直接操作硬件的时候是不分用户态或内核态的,大家就在RING0上搞事情。有了高级操作系统之后,软硬分家了,硬件归操作系统管,用户要操作硬件要通过系统调用来让内核代替执行。
我们再捋一捋,由用户态到内核态的过程,用户程序通过使用 glibc 提供的库函数进行屏幕console输出,比如printf,printf再调用内核提供的系统调用实现sys_write,Linux内核把用户数据再加上预定义好的系统调用号存在寄存器中,然后通过int 80h中断给CPU发指令,数据已准备好,请发往屏幕。因CPU太快了,大部分时间CPU只和它自己的寄存器玩,只有需要和其它硬件打交道时才会用上中断。所谓中断就是打断,让CPU停停,要操作硬盘、键盘、内存等总线上的数据了,准备接收数据。
要深入理解中断、中断向量表、中断编号、中断处理程序以及Linux中的实现,请参考下面的链接。
参考:
【https://www.kancloud.cn/idzqj/customer/2138868 】
汇编语言系统调用(System Calls)【https://www.cnblogs.com/yungyu16/p/13024485.html】
汇编语言基础:寄存器和系统调用【https://www.jianshu.com/p/2b21cffda10d】
机器指令、汇编指令、系统调用(OS Kernel)、标准库、层次关系
