




运维经验是资深运维人员最宝贵的财富,运维经验一直是积累在专家的脑子里的。作为企业,当然希望运维经验能够成为企业或者团队的财富,而不仅仅是个人的财富。企业积累运维经验的方法比较单一,建立所谓的运维知识库,这种知识库往往是一些文本或者预案,使用起来十分不便,积累起来更是麻烦。记得十多年前的时候,几个朋友在一起讨论如何把一些资深DBA的运维经验变成一个工具,如果做出这样一个工具是否可以卖大价钱。有一家移动公司被这个想法打动,于是当时还是ORACLE最资深的员工的刘向东就带着几个弟兄开发了一个程序,主要是把几个工作了十多年的DBA的一些分析问题的思路梳理成了几个分析流程,当用户遇到问题的时候,可以根据软件提供的流程去做相关的分析。这套系统做的不算成功,最主要的是现场遇到的问题十分复杂,哪些工作要套用哪个流程比较难以确定,而且这个工具中给出的分析流程也具有一定的局限性,不同的系统,不同的数据库版本,都存在巨大的不确定性。
事实上,所有的系统或者工具都是死的,都无法实现真正的运维经验的积累。而以知识库模式建立的运维经验库,其顶峰模板就是Oracle公司的Metalink,现在叫MOS了。建立MOS这样的知识库成本是十分高的,一般的企业无法做到,而且MOS对于普通的运维人员来说还是太高深了,面对我们现在的海量系统运维,依靠这种重型的知识库是不行的。
按照健康管理的思路,运维经验的积累不能完全依靠死的工具,而是要依靠生态。首先工具平台是搭平台搭一个大家可以在上面任意挥洒的平台,建立运维经验工具化的基础工具集和调用协议。并不断的更新相关的知识点,运维经验的发现更大程度需要依靠一线运维人员的发现。同时某地新发现的运维经验可以很快工具化并广泛共享,只有建立这样的生态,运维经验才能变成一潭活水。下面我们通过一个案例来进一步阐述这个观点。
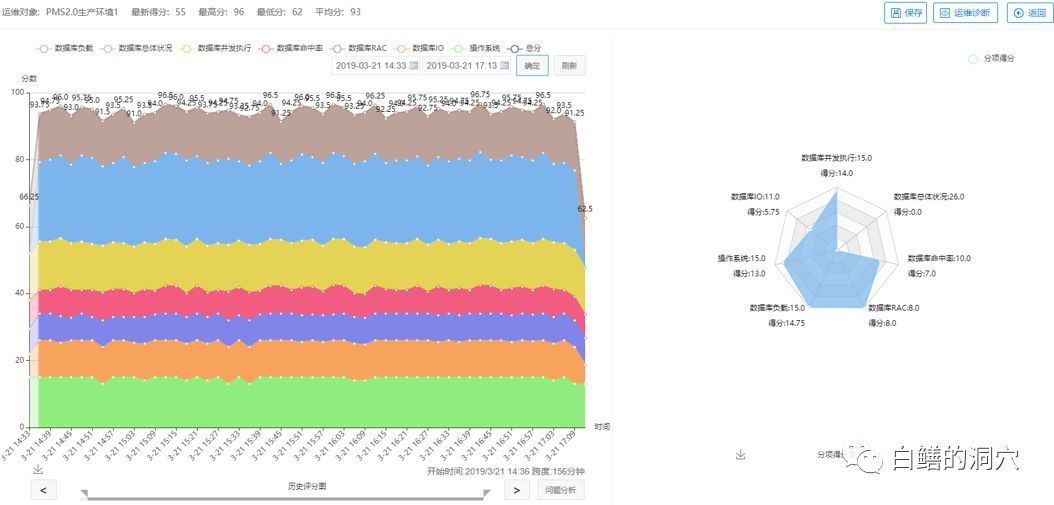
某省PMS系统的健康指标突然严重下降,多项指标严重失分。通过雷达图发现数据库IO和数据库并发方面丢分严重,从而导致数据库总体健康维度分数突降。下面是本次事件的处置过程:

由于现场的运维人员自己感觉无法处置此次故障,D-SMART也没有提供此类问题的运维诊断工具,于是现场运维人员将状态巡检报告导出为WORD文档,发给了三线专家。三线专家在10分钟内就定位了这是一个我们运维经验库中还没有包含的系统故障,是由于DBLINK访问某张缺乏索引的大表触发某个BUG引起的DFS LOCK HANDLE等待。提出的处置方案是必须重启数据库实例,同时对于那张表需要建索引。于是当天晚上在检修窗口中完成了此次操作,第二天系统恢复正常。

通过这件事,我们这个用户积累了第52号运维经验,后端的专家团队很快完成了类似运维经验的诊断路径梳理,工具组在2天后就完成了诊断工具相关的知识点开发,并将知识点下发到各个运维单位。运维单位利用知识点很快就完成了本运维经验的构建,下回再发生类似问题的时候,不需要通过健康模型报警,运维经验就会自动产生报警,并提醒运维人员使用该运维经验去完成诊断分析,定位故障原因了。
