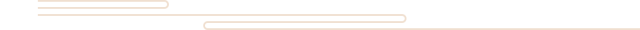文/应用开发六部 孟庆龙


随着业务发展,数据量和关联深度不断增加,传统的关系型数据库无法满足海量的数据处理需求,且灵活多变的需求往往迫使数据模型进行调整,导致系统维护升级成本较大,而图数据库恰好具有善于处理深度数据和模型灵活的特点。本文主要介绍两类数据库的差异,和基于图数据库Neo4j的建模。
图数据库简介
图数据库基于图理论,也可称为面向/基于图的数据库,对应的英文是Graph Database。图数据库的基本含义是以“图”这种数据结构存储和查询数据。它的数据模型主要是以节点和关系(边)来体现,如图1所示。
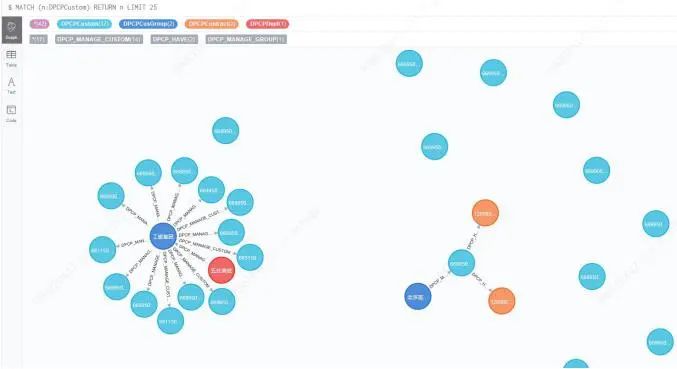 图1 图数据库示例
图1 图数据库示例
与关系模型差异
图数据库中的每个节点都直接包含一个关系列表,关系列表中存放此节点与其他节点的关系记录,运行类似关系数据库的连接(Join)操作时,图数据库都将使用此列表来直接访问连接的节点,无须进行记录的搜索、匹配计算操作。
将关系预先保存到关系列表中的这种能力使Neo4j能够提供比关系数据库高几个数量级的性能,特别是对于复杂连接的查询,Neo4j能够实现毫秒级的响应。
如图2所示,使用关系数据库创建一个客户合约动账跟踪的存储结构,必须为客户、合约、账户、用户单独创建表结构,各个表结构之间通过外键约束相互关联,对于多对多的复杂关系还须创建“中间表”(如Observe表),这消耗了大量的系统资源。
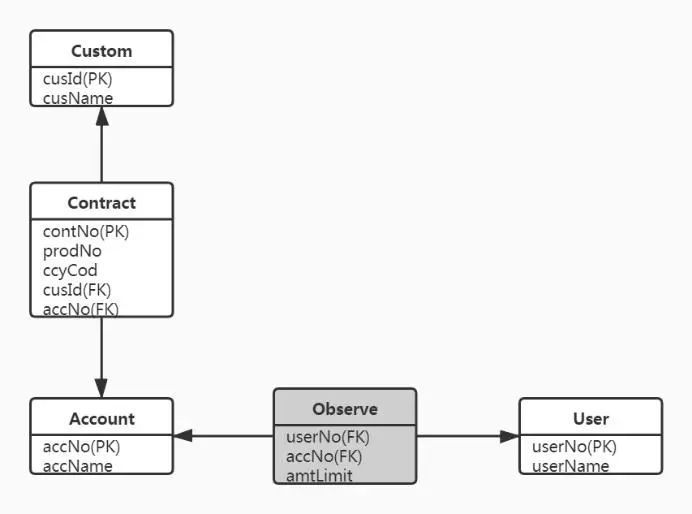 图2 关系数据库模型示例
图2 关系数据库模型示例
如果采用图数据库创建则容易得多,只需要为客户、合约、账户、用户创建节点,并且节点不需要主键、外键,也不需要中间表,只保留必要的属性即可。各个节点直接通过关系指向来表达节点之间的复杂关系,如图3所示。
 图3 图数据库模型示例
图3 图数据库模型示例
Neo4j有一个重要的特点,就是用来保证关系查询的速度,即免索引邻接属性,数据库中的每个节点都会维护与它相邻节点的引用。因此每个节点都相当于与它相邻节点的微索引,这比使用全局索引的代价要小得多。这就意味着查询时间和图的整体规模无关,只与它附近节点的数量成正比。在关系型数据库中使用全局索引连接各个节点,这些索引对每个遍历都会增加一个中间层,因此会导致非常大的计算成本。
比如还以图2的模型为例,查询某个用户关注的所有账户:
(1)SQL语句:
SELECT accName FROM Account
LEFT JOIN Observe
ON Account.accNo = Observe.accNo
LEFT JOIN User
ON User.userNo = Observe.userNo
WHERE User.userNo = "user1"
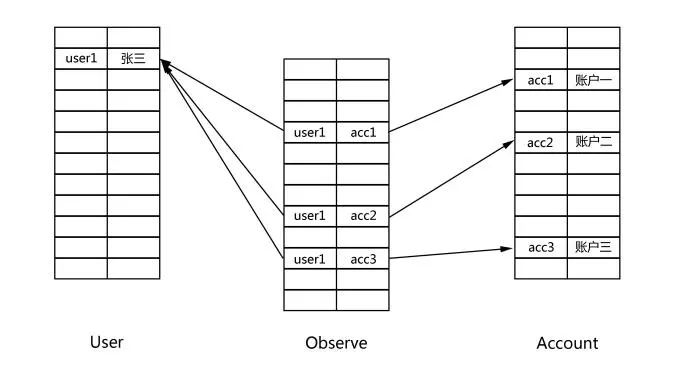 图4 关系数据库查询示意图
图4 关系数据库查询示意图
图4展示了在关系数据库中的查询方式。要查找user1关注的所有账户,首先要执行关系表的索引查询,时间成本为O(log(n)),n为索引表的长度。
(2)Neo4j的Cypher语句:
match(u:User{userNo:'user1'})-[:Observe]->(a:Account)
return a.accName
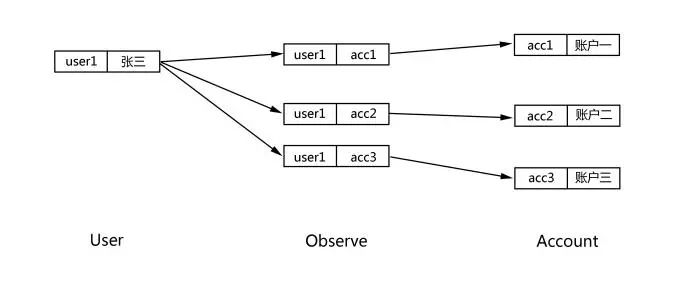 图5 图数据库查询示意图
图5 图数据库查询示意图
图5展示了同样场景下Neo4j的查询方式。使用免索引邻接机制,每个节点都有直接或间接指向其相邻节点的指针。要查找user1关注的账户,只需要在user1的关系链表中遍历,每次遍历的成本仅为O(1)。
考虑一个更复杂的场景,user1关注的账户还被哪些用户关注了,在关系数据库中,找到user1关注的账户的时间成本为O(log(n)),找到每个账户被哪些用户关注的时间成本为O(n),假设user1关注了m(m远小于n)个账户,那么总的时间复杂度为O(m*n*log(n))。而在图数据库中,时间复杂度仅为O(m),其中m远小于n,这相比关系数据库占有绝对的优势。
迁移和优化
通过对比发现,图数据库节点不需要主键、外键,也不需要中间表,只保留必要的属性,使用图数据库可以更加简洁、明确地描述数据间的复杂关系,且查询效率更高,总结以下从关系数据库迁移至图数据库的原则:
(1)表到节点标签:关系模型中的每个实体表都成为图模型中节点上的标签。
(2)行到节点:关系实体表中的每一行都成为图中的一个节点。
(3)列到节点的属性:关系表上的列(字段)成为图中的节点属性。
(4)添加约束/索引:为业务主键添加唯一约束,为频繁查找属性添加索引。
(5)关系的外键:用关系替换另一个表的外键,然后将其删除。
(6)连接表到关系:将连接表转换为关系,这些表上的列成为关系的属性。
根据3.1中的原则即可完成数据迁移,但在实际建模前,还可以结合具体需求对模型进行优化,判断哪些查询需要更高的性能,调整数据模型以充分发挥图数据库的优势。
如图6所示,需要经常查询所有币种为美元的合约,查询语句如下:
match (c:Contract)
where c.ccyCod='USD'
return c.contNo
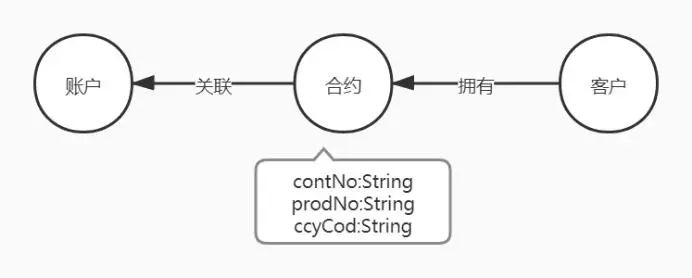 图6 合约节点优化前示意图
图6 合约节点优化前示意图
这样需要遍历所有的合约节点,逐个判断币种属性,可以优化为图7所示,将币种属性作为节点提出,合约指向币种节点,这样在查询时只需要从币种作为头节点查询关联的所有合约即可,利用Neo4j免索引邻接的特性,大大提升查询效率。
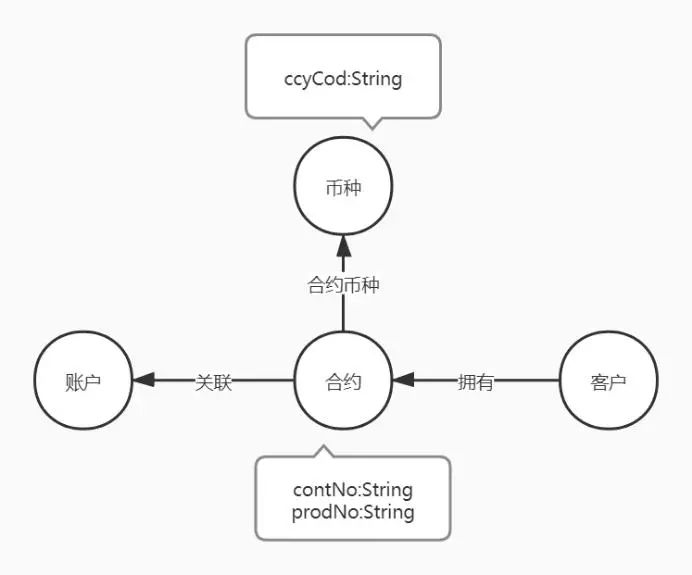 图7 合约节点优化后示意图
图7 合约节点优化后示意图
首先给币种节点的ccyCod属性创建唯一约束,避免创建重复的节点:
CREATE CONSTRAINT ON (ccy:Ccy)
ASSERT ccy.ccyCod IS UNIQUE
然后变合约的币种属性为币种节点,将合约指向币种节点,如果有很多节点需要更新,可以尝试批量提交:
CALL apoc.periodic.iterate(
'MATCH (contract:Contract) RETURN contract',
'MERGE (ccy:Ccy{ccyCod:contract.ccyCod}) MERGE (contract)-[:CONTRACT_CCY]->(ccy) REMOVE contract.ccyCod',
{batchSize:10000,iterateList:true,parallel:false}
)
优化模型后的查询语句如下:
match (ccy:Ccy)<-[:CONTRACT_CCY]-(cont:Contract)
where ccy.ccyCod='USD'
return cont.contNo
类似的场景可能在项目的初期不容易判断,Neo4j的优势就在于数据模型具有灵活性,能够根据需求的变化而更改。
总结
图数据库是大数据时代的一把利器,充分研究并应用到对公领域系统建设中,有助于提升服务品质和用户体验,通过科技赋能,不断为客户提供更优质的金融服务,助力数字化转型发展。
顾问:王振峰 刘建闽 刘文刚
主编:王皓瑜
副主编:田光辉 宋佳雨
审核:张大伟
编辑:孟庆龙