





在本专题的上一篇文章中笔者提到了分布式键值系统中间件之间的共识问题:如何让所有的中间件维护多个一致的哈希环。今天我们就来专门聊一下分布式系统中的共识问题(Consensus Problem)。可以毫不避讳地说,共识问题是分布式系统中最为棘手的问题之一。而本文将详细解释什么是共识问题,为什么需要解决共识问题,解决共识问题的难度以及如何通过raft协议来解决共识问题。
共识问题
简单来说, 共识问题就是:在一个分布式系统中,多台机器如何在各种错误(机器宕机,局部网络中断)都可能发生的情况下达成(agree on)一个或者多个相同的值。读者也许无法马上理解这是什么意思,不过笔者相信以下例子将会给出一个清晰的描述:
大部分后台程序都需要连接上数据库服务器,大部分人可能认为数据库服务器就是一台机器,当然在大部分情况下(课程作业或者小型项目)这是对的,但是在大型互联网公司的线上服务中,如果每个服务只连接上一台数据库服务器,这台机器的宕机将会导致整个服务的不可用,而这是对服务可用性(availability)要求极高的互联网公司们绝对无法容忍的,因为几分钟甚至几秒钟的宕机可以给公司带来巨大的收入损失。
于是如下图所示,主从结构的数据库集群架构被提出了。在master-slave的mysql集群中,master节点处理所有的写请求和部分关键读请求,slave节点则只能处理读请求。所有写入master节点的数据通过binlog异步同步至slave节点中(eventual consistency模型),当master节点因为磁盘错误或者软件错误宕机时,一个slave节点将会被选举(elect)为新的master节点。
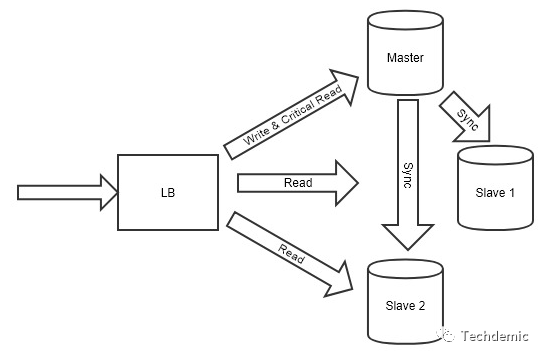
在以上例子中,就有一个明显的共识问题:所有节点都认定同一个节点作为master。如果我们把所有机器都编上一个号码,那么这个就等价于刚刚提到的“达成(agree on)一个或者多个相同的值”。一旦有超过一个节点认为自己是主节点,那就会出现严重的后果:数据会被写入不同的节点,造成不同的主节点维护着不一样的数据,导致数据不一致的问题,这被称为脑裂(brain split)现象。
我们可以来设计一个简单的节点选主算法:如下图所示,假设集群中有三个节点,他们想要选出一个master(或者leader),于是他们随即决定是否提名自己,如果提名自己,将给其他所有节点发送voting请求,每个节点收到来自其他节点的voting请求时将比较两个voting请求到达的时间,并将票投给请求较早到达的节点。在下图中,node 2和node 3通过随机算法决定自己参选。因为node 2的请求到达更早,node 1将票投给了node 2,node 2和node 3因为参选,将互相否决。此时node 2收到了node 1的票,于是获得两票(加上自己的一票)成为master节点。node 3因为被node 1和node 2否决知道自己竞选失败,可是他并不知道谁是新的master,所以node 2当选主节点后,会给node 1和node 3发送消息,告知它们自己已经成为master。最终三个节点达成了共识。这就是共识协议运用最多的选主问题(leader election)。
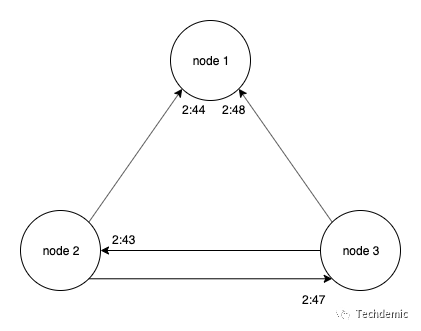
以上算法其实描述的是最简单的一种情况:在没有错误发生的同步(synchronous)系统中的共识算法。为什么说是同步呢,因为以上例子中的三个节点都不约而同地发起了投票,并且请求的发送到接受不会无限延期,就好像有一个全局时钟在协调他们。而真实的分布式系统都是异步(asynchronous)的,请求可能丢失,请求的发送到接受也可能无限延期。并且,如果存在多轮选举,节点无法得知收到的拉票请求是否属于本轮,从而导致混乱。
最重要的是,并不是所有的节点都可以当master,而是只有同步了最新数据的节点才能成为master。GitHub曾经出现过一次严重的线上事故,其起因是线上的mysql集群master节点宕机了,一台还没有同步最新数据的slave节点顶替了上去(之前提到过mysql集群的master-slave replication是通过binlog异步同步的)。同时,数据库中的user表的主键采取了 autoincrement
模式,因为新的master比旧master延后,新master的当前主键值也比旧master的最新主键值小,导致最新插入的行的主键与旧master的数据重复,然而旧master节点的最新数据通过主键保存在了Redis缓存中,这导致了新master节点中刚刚添加的行会在redis中获得不属于它的数据,这最终导致了用户看到了不属于自己的repository,造成了严重的安全问题。
然而如何判断一个节点同步了最新数据是一个很难的问题,因为每个节点甚至都不知道自己是否同步了最新数据,判断其他节点是否同步了最新数据更是困难。
Paxos协议
为了解决异步系统中的共识问题,Leslie Lamport在1989年发表了论文 ThePartTimeParliament
并提出了Paxos协议,并在数学上证明了算法的正确性。自此Paxos算法成为了分布式共识的代名词。然而,不仅Lamport的论文晦涩难懂,这个算法也很少有人能够彻底掌握,甚至到现在也没有一个 multiPaxos
(Paxos的拓展算法,用来多次达成共识,只有multi Paxos才在真正的系统中有意义)的开源实现。已知Google Chubby与阿里巴巴的OceanBase是基于 multiPaxos
的,但是它们都没有开源。
Raft协议
为了解决Paxos协议晦涩难懂并且工程上难以实现的问题, DiegoOngaro
与 JohnOusterhout
在2014年发表了论文 InSearchof anUnderstandableConsensusAlgorithm
并提出了 Raft
算法,其以简单易懂和易于实现而被广泛接受,并应用在了包括Etcd,PolarDB以及TiDB等多个开源分布式数据存储系统中。
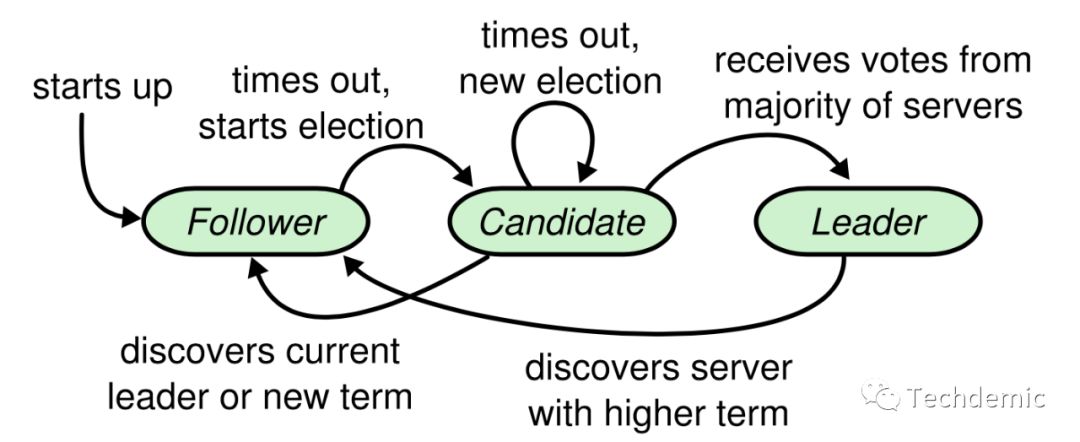
不同于Paxos的weak leader,Raft采取的是strong leader的模式,也就是同一时间集群中只能有一个合法的leader,而这个leader则是通过选举产生的。如下图所示,每个节点可以存在三个状态:Leader, Follower以及Candidate。Leader通过定时ping所有节点来维护自己的leader地位,而当某个Follower节点在一段时间内没有收到leader的ping请求时将会认为leader已经宕机,转化为Candidate并给其他所有节点发送 RequestVote
拉票请求。当获得过半票数时,自己将会成为新的leader。
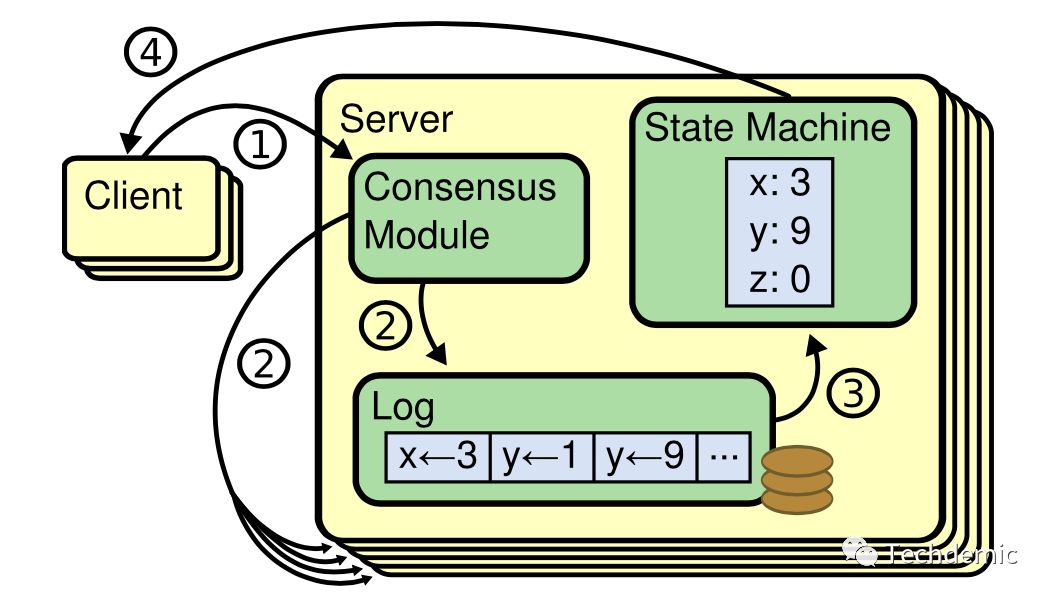
如下图所示,Raft协议将数据库视为一个状态机,每个节点都会维护一个状态机与一个持久化在磁盘中的log,当leader收到来自客户端的写请求时,先将请求中的指令append在log中,然后并行给所有的follower发送 AppendEntries
的RPC请求,follower收到请求时将entries append到自己的log中并回复确认,当达到半数的follower回复确认之后,主节点会commit 最新的log entry并将其apply到状态机上。Raft将其称为 ReplicatedStateMachine
问题。由于Raft的quorum机制(多数同意视为生效),一个Raft集群可以在小于一半节点宕机的情况下继续运行(5个节点的Raft集群允许最多2个节点宕机),提供了非常高的可用性。
Raft协议的所有细节都在以下四张图中,其细致程度甚至达到了伪代码级别,也就是说能根据他们直接写代码来实现raft。可以暂时掠过,之后的两个论证会用到他们。




解释一下raft集群中每台机器维护的几个核心数据结构:
term
term
基于Leslie Lamport的论文 Time,clocks,andordering of eventsin adistributed system
。因为分布式系统中时间的不确定性和时钟的不可靠性,需要一个逻辑时钟(logical clock)来确定事件的先后顺序,而 term
就是raft中的逻辑时钟,每次集群中有节点推选自己当leader时,这个节点会将自己保存的term加一,然后把它附在 RequestVote
请求中。当每个节点收到来自其他节点的 RequestVote
拉票请求时,如果 RequestVote
请求中携带的term小于本节点的term,那么这个拉票请求将会被拒绝并被告知本节点最新的term,发送 RequestVote
请求的节点会通过附着在回复中的term来更新自己的term。同样,如果 AppendEntries
请求的term小于本节点的term,这个请求也会被拒绝。因此在Raft集群中的每个节点上,term是一个单调递增的整数,实现了逻辑时钟的效果。这解决了我们之前提到的节点不知道拉票请求来自哪一轮投票造成的混乱。
votedFor
votedFor
记录了每个节点在当前 term
投票给了哪一个节点,这是防止节点在同一个term给多个节点投票的关键数据。
log[]
log[]
是raft维护的最为核心的数据结构。其可以被看成是一个append-only的数组,每条log包含了一条会改变状态机的指令(例如 seta=1
),在log中的位置log index,以及append这条log时的term。其中log index和term用来让节点们判断 RequestVote
和 AppendEntries
请求是否可以接受。
通过以上四张图描述的复杂的机制,Raft得以实现一下五条特性:

其中的 LeaderCompleteness
解决了之前我们遇到的在旧master宕机的情况下新master没有同步到最新数据的问题:如果说在一个term中有一条log entry被commit了,也就是被append到了大部分节点的log里,那么以后就算append这条log entry的leader节点宕机了,那么接替它的新leader的log中也一定会有这一条entry。
笔者将在本文中尝试通过以上四张图中描述的raft算法,来证明这一条特性。不过,在证明 LeaderCompleteness
之前,需要先证明 LogMatching
。
Log Matching
LogMatching
说,如果两个节点的log在相同的log index有着相同term的entry,那么从这条entry开始往前所有entry都相同。
描述 AppendEntriesRPC
图(第二张图)中写到:AppendEntries
请求中包含了 prevLogIndex
与 prevLogTerm
这两个参数来让follower节点做consistency check。当follower节点收到 AppendEntries
请求时,会查看自己log[]中 prevLogIndex
处的term是否等于 preLogTerm
,如果相等,那么follower节点将接受 AppendEntries
请求。通过这个机制,我们可以用数学归纳法来证明 AppendEntries
请求可以维持 LogMatching
:
初始情况:两个follower的log[]都为空, LogMatching
自然被满足了。
迭代至n的情况:假设两个follower的log[]都不为空,并且到index n为止所有entry都一模一样(满足 LogMatching
),此时leader节点发出如下 AppendEntires
请求:
AppendEntriesRequest {prevLogIndex = n;prevLogTerm = t;entires = [newEntry]}
两个follower分别执行consistency check,比较自己log[]在index为n处的term是否为t,发现相等,于是将请求中的newLog append进自己的log,因为从0到n的log entry都相同,所以新的两个log[]也是相同的,此时两个log[]从0到n + 1也是一模一样的(满足Log Matching)。
Leader Completeness
最后,我们终于开始证明最重要的 LeaderCompleteness
了,相比 LogMatching
,这是一个比较艰难的任务,我们将用反证法来证明它。
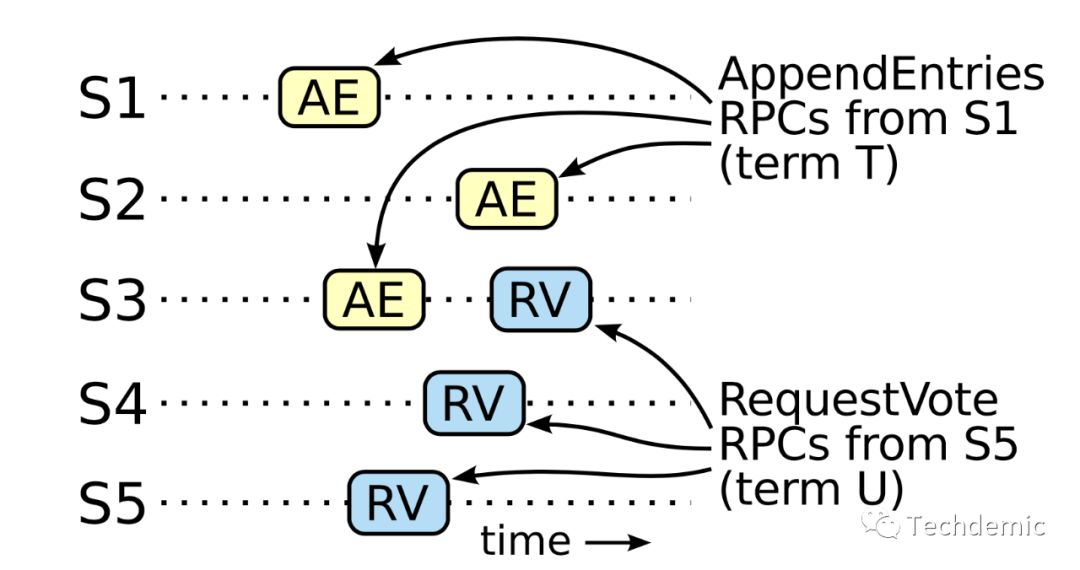
如上图所示,有一个包含五个节点的Raft集群(S1, S2, S3, S4, S5)。在term T中,leader S1将log entry E成功replicate到了S2和S3中,此时包括S1在内有超过集群大多数(三个)的节点append了E,于是S1将E commit。紧接着S1宕机,此时我们做出反证法的假设:在未来某个term中,leader的log[]中不包含E。可以令term U为leader不包含E的第一个term。假设term U的leader为S5,当S5被选举为leader时,包括他自己起码有3个节点给他投了票(quorum机制),由于三个节点超过了五个的大多数,那么起码有一个节点与当初接受了entry E的三个节点重合了!这一个节点将是我们反证法中最为关键的一环。假设这个节点为S3,在term U中,S3给S5投了票,根据 RequestVoteRPC
图(第三张图)的描述,S5的log[]肯定是 at leastasup-to-dateas
S3的log[]。根据Raft对 up-to-date
的定义,有两种情况:
如果S3和S5有着相同的last log term(最后一个log entry的term相同),那么S5的log肯定不比S3的短,那么S5肯定包含了S3的所有log entries,包括E,这就违反了我们之前的假设:term U的leader不包含E。
如果S3和S5有着不同的last log term,那么S5的last log term一定大于S3的last log term,同时又因为S3包含了E,S3的last log term一定不会小于T,于是我们可以推出S5的last log term一定是大于T的。继续推理,在term U之前给S5 append了这个last log entry的leader一定包含了E,因为我们已经假设term U是第一个leader不包含E的term。于是根据
LogMatching
,S5也一定包含了E。这又违反了我们之前的假设:term U的leader不包含E。
以上就完成了 LeaderCompleteness
的证明,通过反证法,我们证明了一旦一个leader commit了一条log entry,那么在以后所有的leader中这条entry都会出现,避免了leader宕机情况下新选举的leader数据没有同步至最新的情况。
总结
笔者在本文中介绍了共识协议的重要性以及Raft算法的概要,如果读者对Raft算法感兴趣,一定要去读一下 InSearchof anUnderstandableConsensusAlgorithm
这篇论文,论文简单易懂,对小白非常友好。
参考文献
[1] Martin Kleppmann, Designing Data-Intensive Applications.
[2] Leslie Lamport, Time, clocks, and ordering of events in a distributed system.
[3] Leslie Lamport, The Part-Time Parliament.
[4] Diego Ongaro and John Ousterhout, In Search of an Understandable Consensus Algorithm.

