




书接上回,本文也是Google Research出品,与EfficientNet一脉相承。文章提出了两个Object Detection的挑战。挑战1:高效的多尺度特征融合(FPN);挑战2:模型scaling(跟EfficientNet类似)。这两个问题是能否高效且精准的进行目标检测的关键。EfficientDet延续了YOLO为代表的One-stage Detection的检测逻辑。
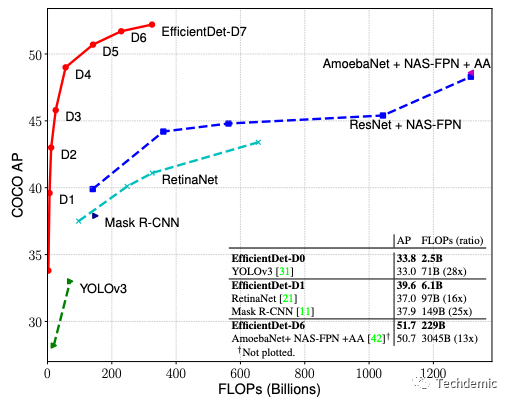
先上结果:
跨尺度融合
随着做了越来越多的分割、检测任务,慢慢发现分割里面的encoder,检测里面的FPN某种程度上来说就是一回事,他们的作用都是特征提取,而为了丰富特征表达能力,需要对不同尺度的特征进行融合,这就是encoder和FPN做的事情。如下图所示:
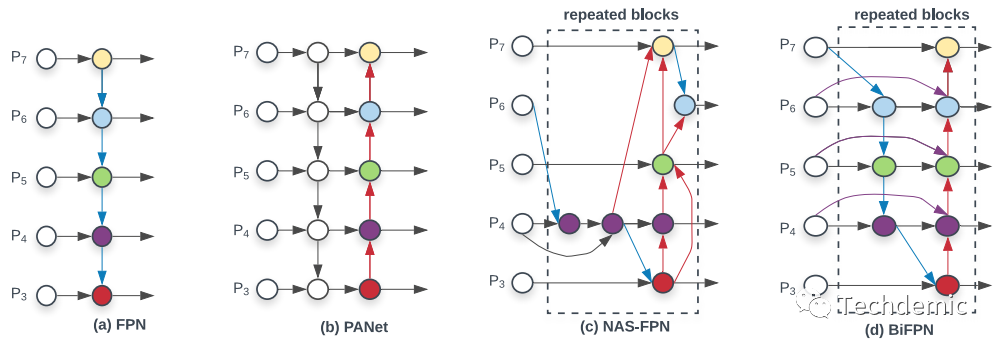
图a是原始的FPN,P3-P7表示从低阶特征到高阶特征的5个stage,可以看到原始的FPN只有从高阶特征到低阶特征的单方向融合(top-down),那么对于高阶特征的输出,其实是没有获得低阶的细节特征信息的。下面的公式说明了FPN如何融合不同尺度的特征:
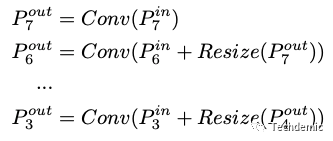
其实就是把不同尺寸的特征resize到相同尺寸,然后输入一个卷积层。
图b是PANet中的双向(top-down & bottom-up)FPN,这样就让高阶特征输出中也有了低阶细节特征信息,使得特征提取更有效,不过双向融合相应的也带来了更大的计算量。
图c是NAS-FPN,顾名思义是用NAS搜索出来的FPN网络,网络结构让人看得摸不着头脑,而且针对特定任务搜出来的网络,泛化能力也不一定好。不过可以注意到其中有很多跳级的连接(cross-scale connections)。
图d就是EfficientDet提出来的BiFPN,它其实是图b和图c的融合,去糟取精。他去掉了图b中的一些不必要的连接,减少计算量,保持了图b中的双向融合;去掉了图c中没有章法的连接,保留了跳级连接。
加权特征融合
这样BiFPN的结构就定下来了,但是作者观察发现,特征融合过程中,不可能每个feature map都有相同的贡献,因此更合理的做法是做加权平均融合而不是单纯的平均融合。这个加权平均的权重是一个可以学习的参数,这样BiFPN的计算公式就成了:
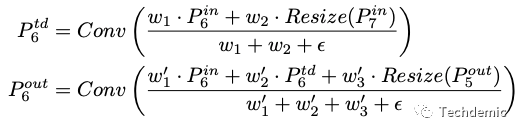
最后,为了更强的特征表达能力以及让网络扩展性更强,BiFPN还被设计成了一个可重复的block,类似ResNet中的bottleneck,EfficientDet可以选择让BiFPN重复多次。
跟EfficientNet一样,EfficientDet也是在找一种可以统一调整网络深度,宽度,输入尺寸这3个维度的方法,从而达到用最少的计算量换取最大的精度提升的效果。
对于目标检测模型来说,模型的尺寸不止分类模型的3个维度,尺寸最终取决于:
backbone网络的深度,宽度,输入尺寸。
BiFPN网络的深度,宽度(输入尺寸由backbone决定)。
Box/class预测网络的深度,宽度(输入尺寸由BiFPN决定)。
这样要想最优化地改变整体网络的尺度,需要的搜索空间就非常大了,很难使用EfficientNet中的网格搜索来做,因此EfficientDet的选择是固定一些参数或者规则化一些参数,人工缩小搜索空间,然后使用启发式的方法来确定upscale的参数。说实话,这种方法不是一个很优美的解法,文章中也承认得到的参数并不一定是最优参数,但是架不住实验结果确实给力。
因为这部分参数的确定属实很暴力,直接人工给出一些规则,没有特别强的逻辑,所以就不仔细去盘了,拿来用就好,如果想知道具体的参数数值,可以直接参考原文。
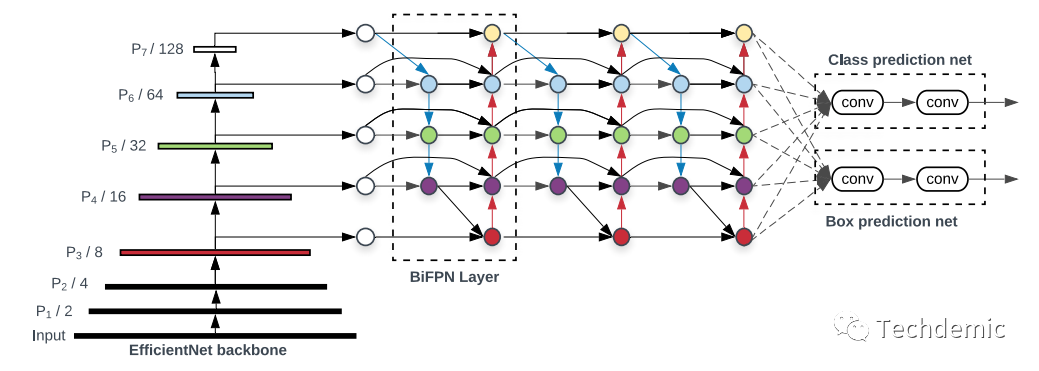
如图所示,EfficientNet+BiFPN+Box/Class Head,可以看到BiFPN部分是可以重复多次的。至于具体的训练过程以及正负样本采样,anchor选取等细节,文章说是与one-stage detector一样,没有过多笔墨在这里。因此这部分我会看过源码后再来补充。
下表是EfficientDet从D0到D7的参数配置细节:
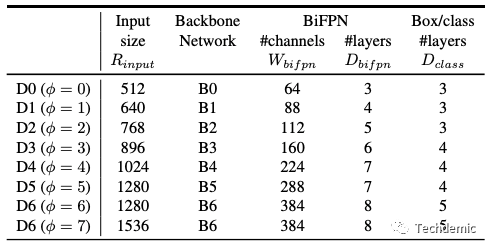
其中φ就是scaling系数,φ越大表示网络整体尺寸越大。
下表是EfficientDet在COCO数据集上的表现,无论从精度还是速度来看,效果都碾压了当时所有模型,当之无愧的SOTA。

有趣的是,如我在前文所说,FPN和分割网络中的encoder其实是一回事。EfficientDet也顺便做了语义分割,也在精度和速度上打败了著名的DeepLab v3.
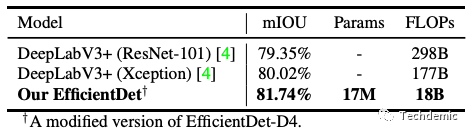
到这里算是彻底了解了EfficientDet的原理了,自己最近也尝试了一下这个算法,速度和效率确实体验不错,但是模型比较难训练,有些trick我并没有完全复现,因此我自己训练的模型精度表现没有文章中宣称的那么好,这也是在官方repo中被质疑比较多的问题。不过这些也不影响我们细品文章的逻辑和原理,细品Efficient系列也就此完结了,希望对大家有所帮助。

