前段时间跟大家分享了我们在KaggleDFDC比赛中用的解决方案。先解释一下,那个Top2%是Public LB的Top2%。就在上周三,Private LB放榜了,放榜现场跟05原油价格跌到负数一样让人大跌眼镜。很多Public LB的前排队伍都消失在了Private LB上。
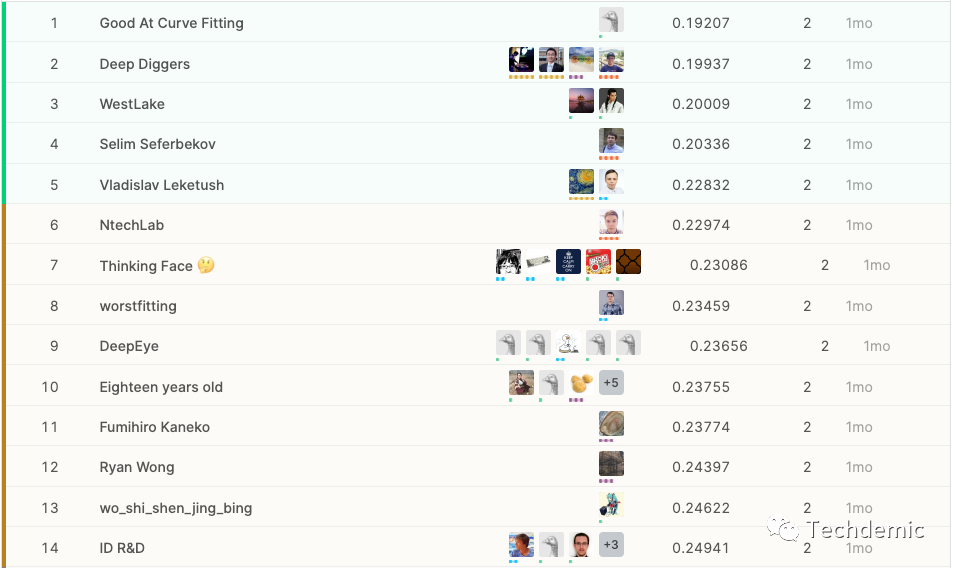
这个是Public LB的金牌区:
这是Private LB的金牌区:
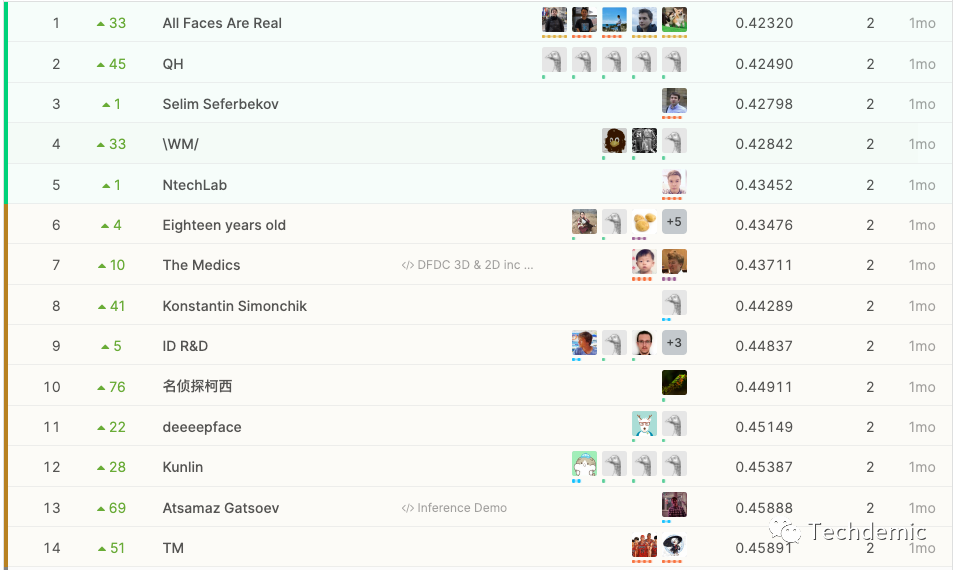
最后的金牌区14支队伍有10支都是从银牌区升上来的,也就是说10支Public LB金牌队伍都翻车了,也算是一次大地震了。后台也有朋友关心我们的成绩如何,实不相瞒,我们也从2%掉到了6%。
说不失落那是不可能的,不过还是决定复盘一下,查查原因。在Discussion里面我们看到了两篇金牌区的分享帖[1][2],分别是第三名和第八名的解决方案,也刚好一个是是没翻车的队伍,一个是逆袭的队伍。
第三名的方案是一个纯2D-CNN方案,也确实如作者所说:"Keep it simple"。
MTCNN提取人脸。
人脸检测框扩大30%。
1:1采样正负样本。
EfficientNet
模型层面足够简洁,干货都在预处理和后处理上。
训练的时候,采用了一系列常规augmentation:
Compression, Noise, Blur, Resize, Color jittering
def create_train_transforms(size=380):
return Compose([
ImageCompression(quality_lower=60, quality_upper=100, p=0.5),
GaussNoise(p=0.1),
GaussianBlur(blur_limit=3, p=0.05),
HorizontalFlip(),
IsotropicResize(max_side=size)
PadIfNeeded(min_height=size, min_width=size, border_mode=cv2.BORDER_CONSTANT),
OneOf([RandomBrightnessContrast(), FancyPCA(), HueSaturationValue()], p=0.7),
ToGray(p=0.2),
ShiftScaleRotate(shift_limit=0.1, scale_limit=0.2, rotate_limit=10, border_mode=cv2.BORDER_CONSTANT, p=0.5),
]
)
为了防止过拟合,提高模型泛化能力,他们使用了domain specific augmentations,根据MTCNN的面部关键点删除人脸的部分区域(半边脸,嘴巴,眼睛或者鼻子)。除此之外,还针对真脸和假脸做了SSIM,把不同区域作为关键特征,确保在删除区域的时候不会删除关键特征。这一步应该是整个pipeline的点睛之笔,既提高了泛化能力,也变相的将模型注意力放在了真脸假脸的区别上,需要很强的数据处理能力。他们做的结果如下(结合了参考资料[3]和[4]):
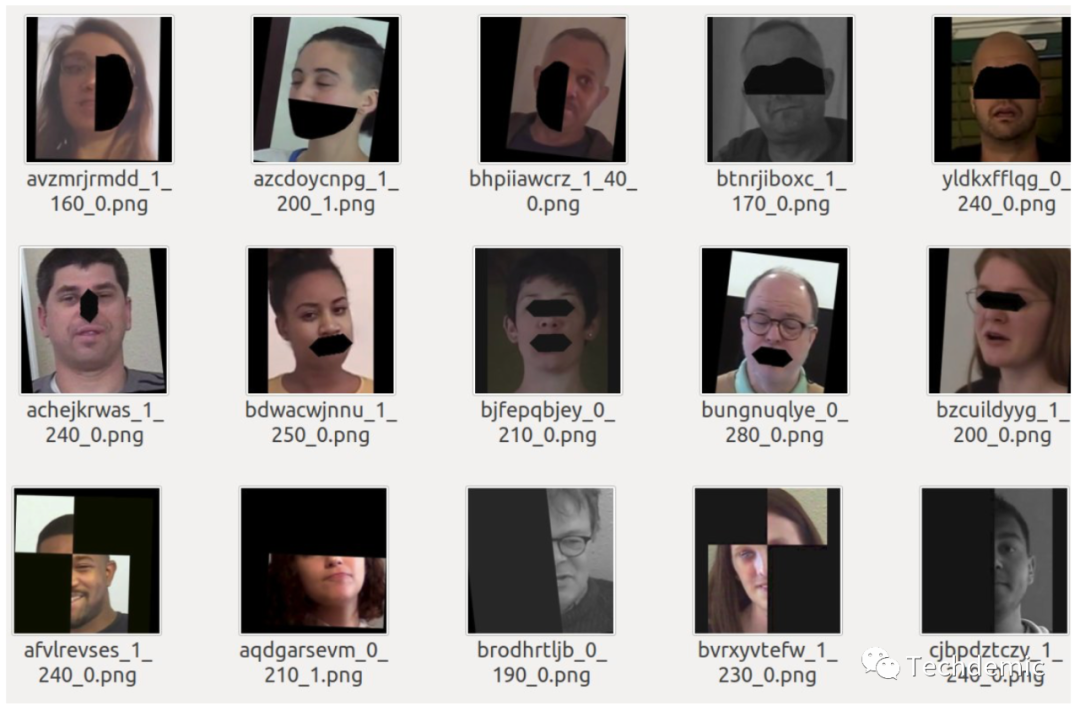
预测时,每个视频取32帧。这里还有个sao操作,人为设置了一个规则来做average predict:
def confident_strategy(pred, t=0.87):
pred = np.array(pred)
size = len(pred)
fakes = np.count_nonzero(pred > t)
if fakes > size // 3 and fakes > 11:
return np.mean(pred[pred > t])
elif np.count_nonzero(pred < 0.2) > 0.6 * size:
return np.mean(pred[pred < 0.2])
else:
return np.mean(pred)
也就是说只选择一些非常确信的预测结果来获得平均预测结果,这就解决了我们之前在做average predict时遇到的得分普遍在0.3-0.8之间的问题。当时我们想到用中位数或者其他分位数来代替均值,但也没想到还能这样处理,确实学到了。
第八名的方案,则是一个纯Video解决方案,他们用了3D CNN(I3D, 3D ResNet等)融合了一个2DCNN模型,一共8个模型。
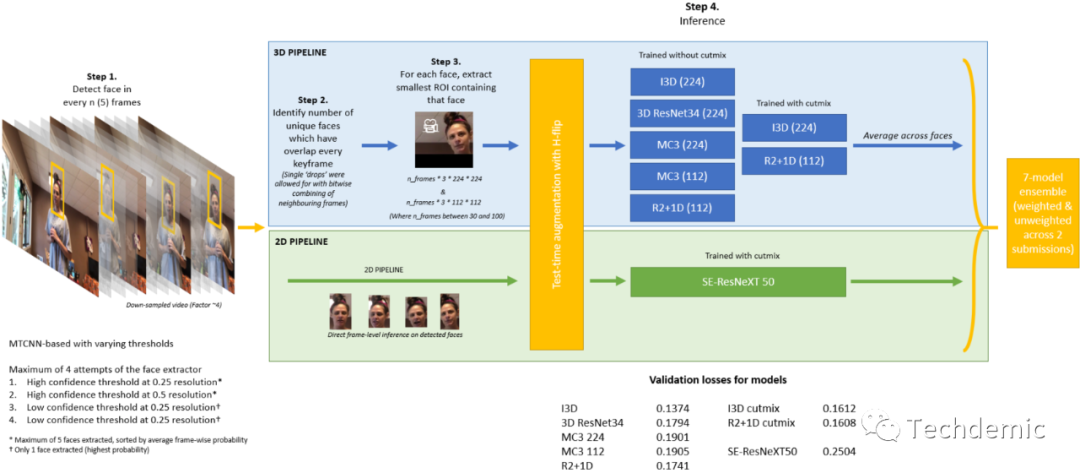
原贴没有说太多关于数据处理的细节,所以我们也没法很好的去对比和评价。因为这个比赛最大的难度现在来看是如何有效提高泛化能力,抛开数据单纯谈论模型,没有太大意义。
这个比赛给我带来的最大感触是,不要尝试一味地拟合Public LB。回想当时我们在刷分的时候,唯一的目标就是提高Public LB的分数,忽视了泛化能力的提升。当时的想法还是Public LB的分布理应是跟Private LB分布差不多的。现在看来趋势就是要让model能在现实世界中使用,而不是只活在数据集中,因此分布一致的假设还是不应该再有了,尽力提高泛化能力才是王道。某种程度上来说,这是一件好事,一个好的趋势,可以让未来比赛的产出更加直接,甚至可以直接被工业界使用。
另一个感触就是,Data Science的比赛,终究还是数据为王,在整个比赛过程中,我见过前排队伍说LSTM有用,也见过说LSTM没用的;见过说3D CNN有用,也见过说3D CNN没用的;当然,也见过说average predict有用和没用的。但是仔细想来,这些方法在正确的数据下,应该都是可行且有用的,产生这些不一致结果的根本原因是不同的输入数据。在我看到的这些高分开源方案中,基本都对数据做了细致的分析和处理,这部分应该是我以后的比赛中最需要提升的。
[1] https://www.kaggle.com/c/deepfake-detection-challenge/discussion/145721
[2] https://www.kaggle.com/c/deepfake-detection-challenge/discussion/140364
[3] Chen, Pengguang. "GridMask Data Augmentation." arXiv preprint arXiv:2001.04086 (2020).
[4] Li, Lingzhi, et al. "Face X-ray for More General Face Forgery Detection." arXiv preprint arXiv:1912.13458 (2019).