




某业务系统的数据库实例在早上业务高峰期还未到来时突然宕机,运维人员发现后重启了系统,整个系统恢复运行。这种情况似乎在我们的运维工作中经常出现,很多时候我们甚至无法追溯问题发生的原因,因为系统重启过,很多证据都缺失了。而且在纷繁的数据中,要去找一个有问题的指标也是工作量十分大的。今天给大家分享的案例就是一个类似的事情。
这套系统还是一套建设阶段未转运行的系统,在绝大多数企业里,这类系统属于三不管系统,一般都是开发商代管,而开发商又没有专业的运维团队在做专业的运维,因此系统出故障想要溯源是十分困难的。在分析故障原因的时候,数据库厂商、服务器厂商、网络厂商的原厂工程师互相推诿,无法定位问题。幸运的是,在几个月前,这套系统上部署了D-SMART健康管理工具,于是现场运维人员把脱敏后的监控数据发送到三线专家组手里。
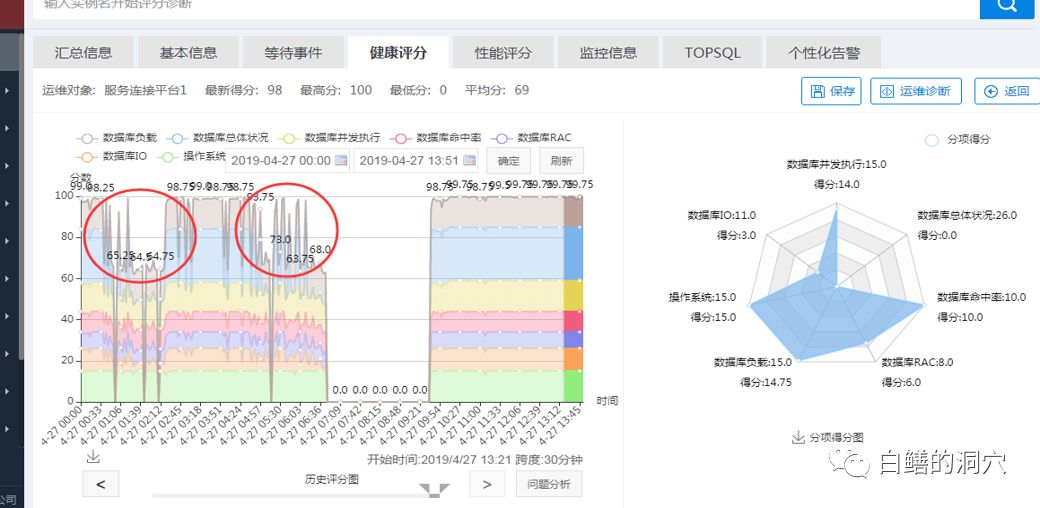
首先我们来看健康模型,从时序上看,早上6点36分后到9:54这段时间数据是缺失的,这段时间可能就是本次故障的系统宕机时段,或者该时段数据库已经出现了严重的问题,监控探针都无法登录数据库采集指标了。宕机时间从6:35分之后,从监控管理的告警数据可以看到7:18左右数据库发生了宕机,在ALERT LOG中也确认了这个信息。系统恢复的时间是9:51-9:54之间。
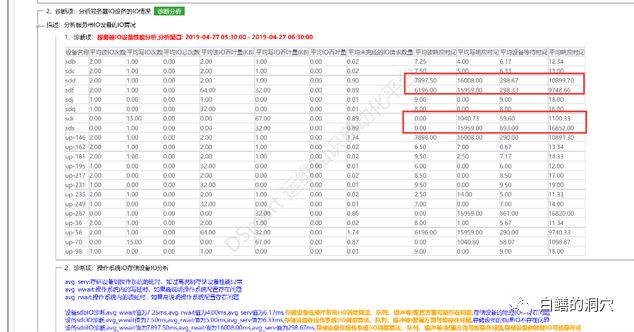
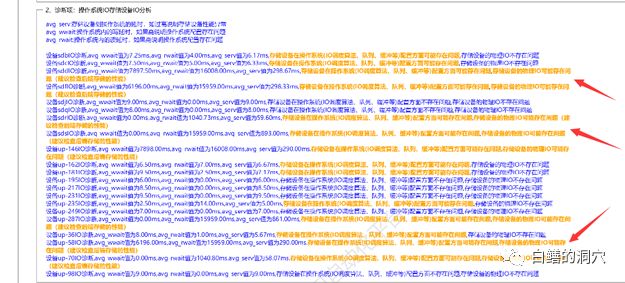
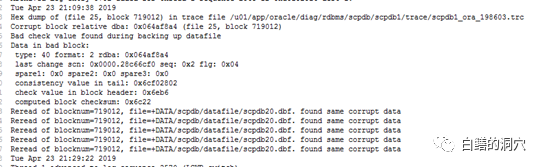
通过IO分析工具检查,发现系统IO存在较为严重的问题,问题可能来自于后端存储。于是我们要求存储厂商检查SAN网络与后端存储的情况。存储厂商坚称存储没问题。于是我们又扩大了排查范围,在前一天晚上21点左右的时候发现了一个日志告警的信息,通过ALERT LOG确认,是在数据库做全备的时候出现了一个报错:
文章转载自 白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
