




单点问题
单点问题,有两个层次:
服务单点:服务故障无其它节点顶替,导致服务不可用,此时单点故障;
访问单点:没有出故障,即便出现也有其它节点顶替提供服务,但是访问始终落在单个点上,单个点有瓶颈,这也是一种单点问题。
redis-cluster
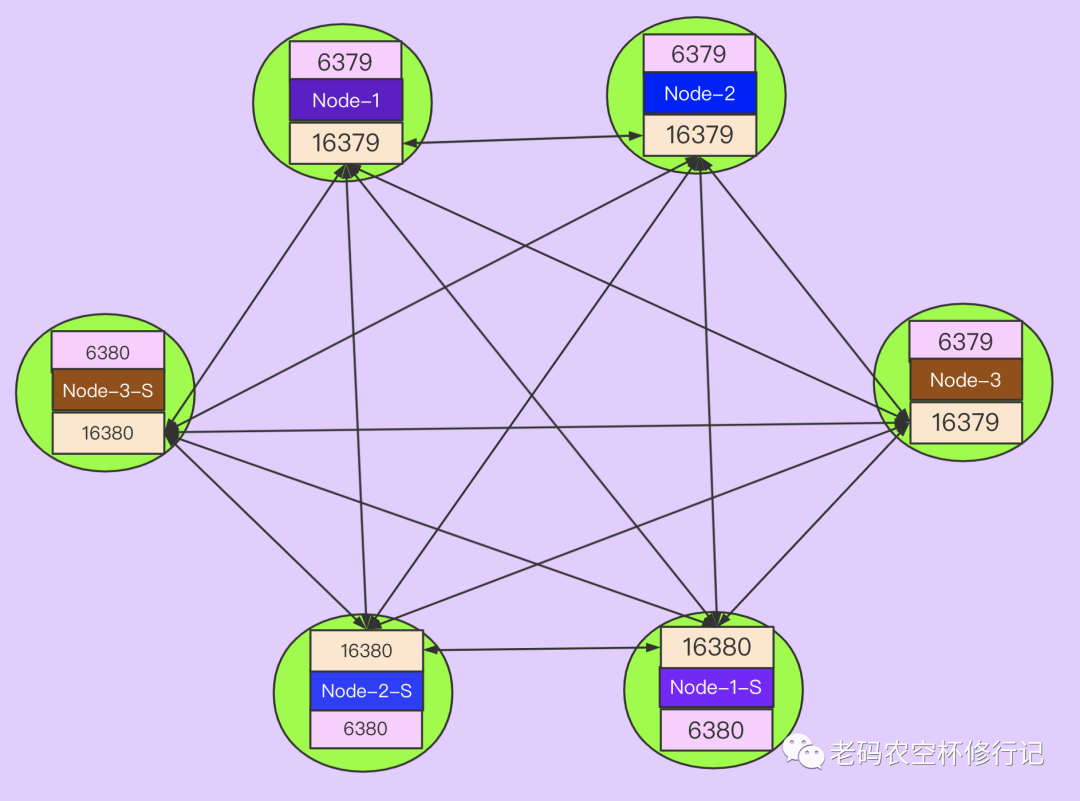
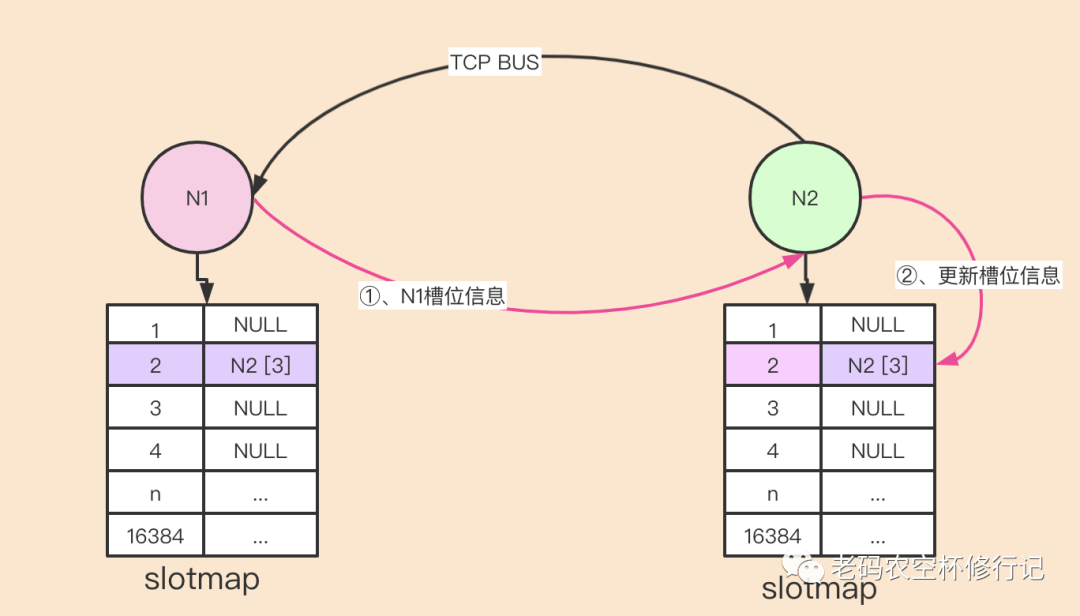
redis 集群是去中心化网状结构,集群中无论是否主从关系,都需要与集群中的其它节点建立连接,这个连接叫做TCP总线(内部连接端口是在对外提供请求的端口之上加10000,比如对外6379,则总线端口为16379)。建立连接之后集群内部都通过该总线进行交流(槽位节点映射表、配置信息等)。
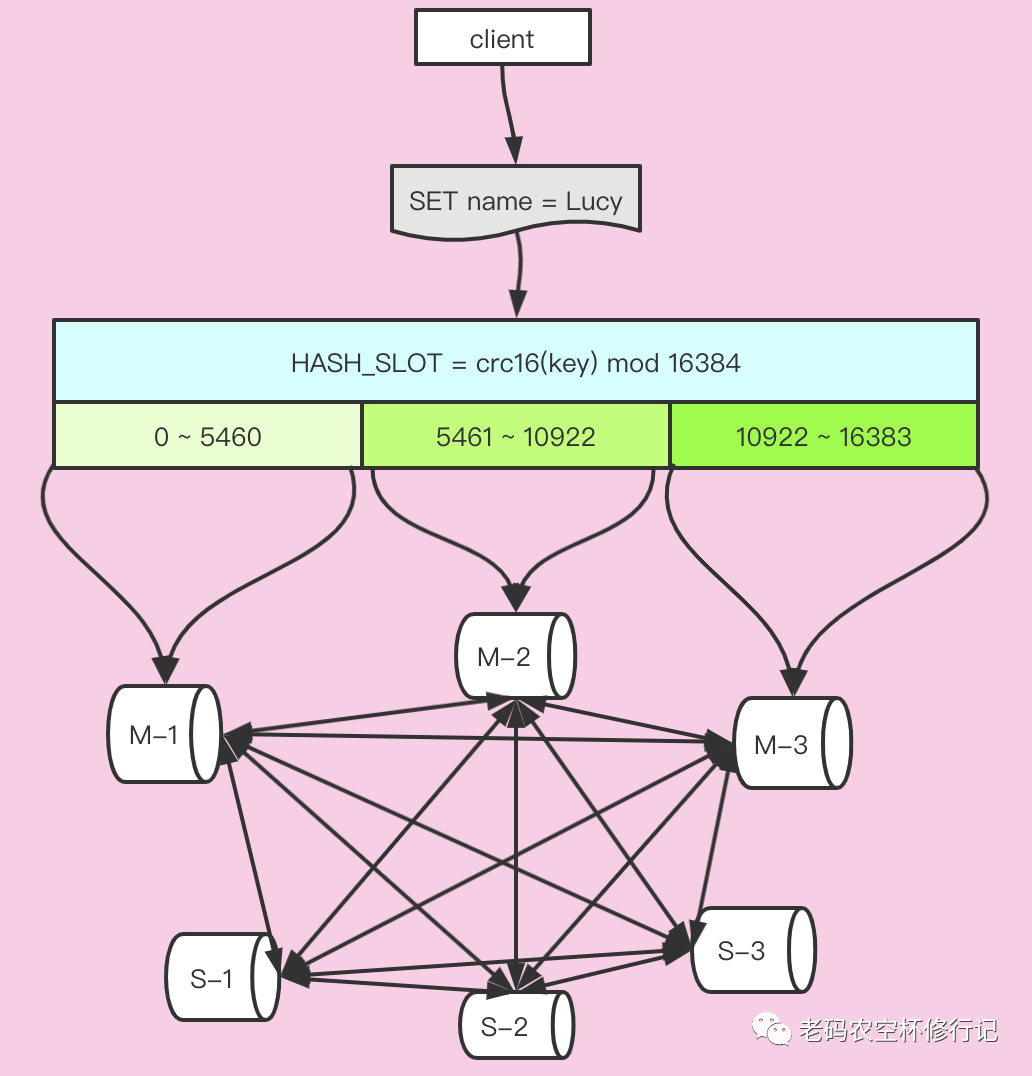
读写原理
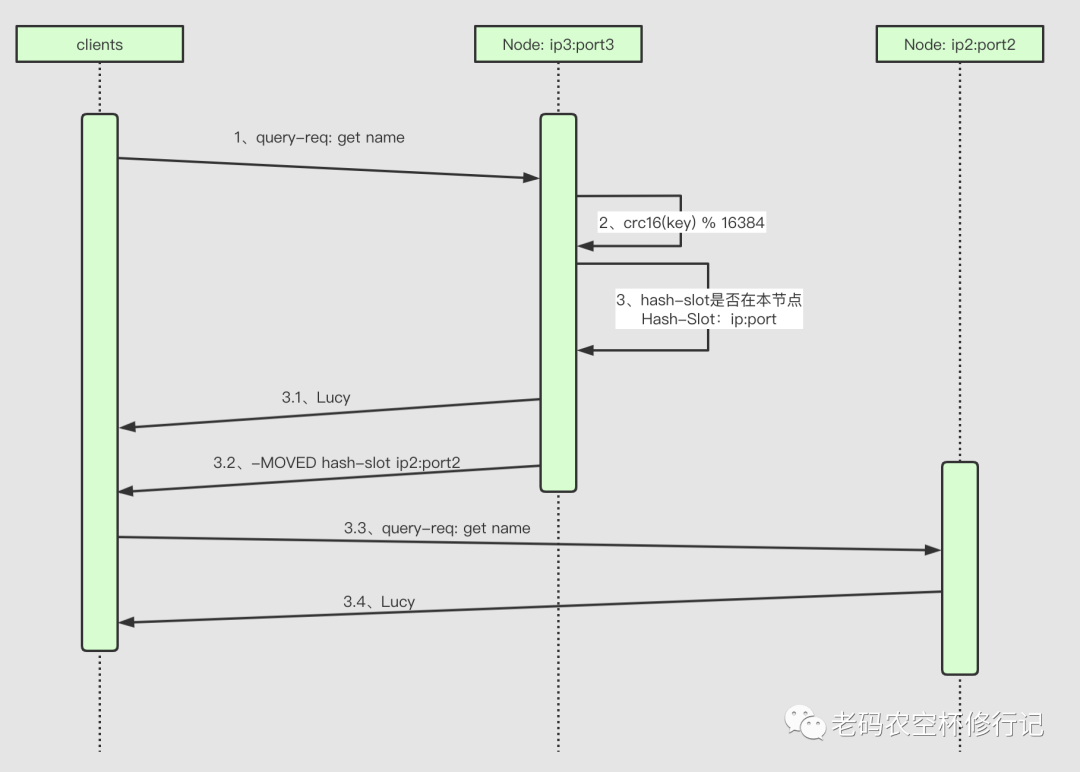
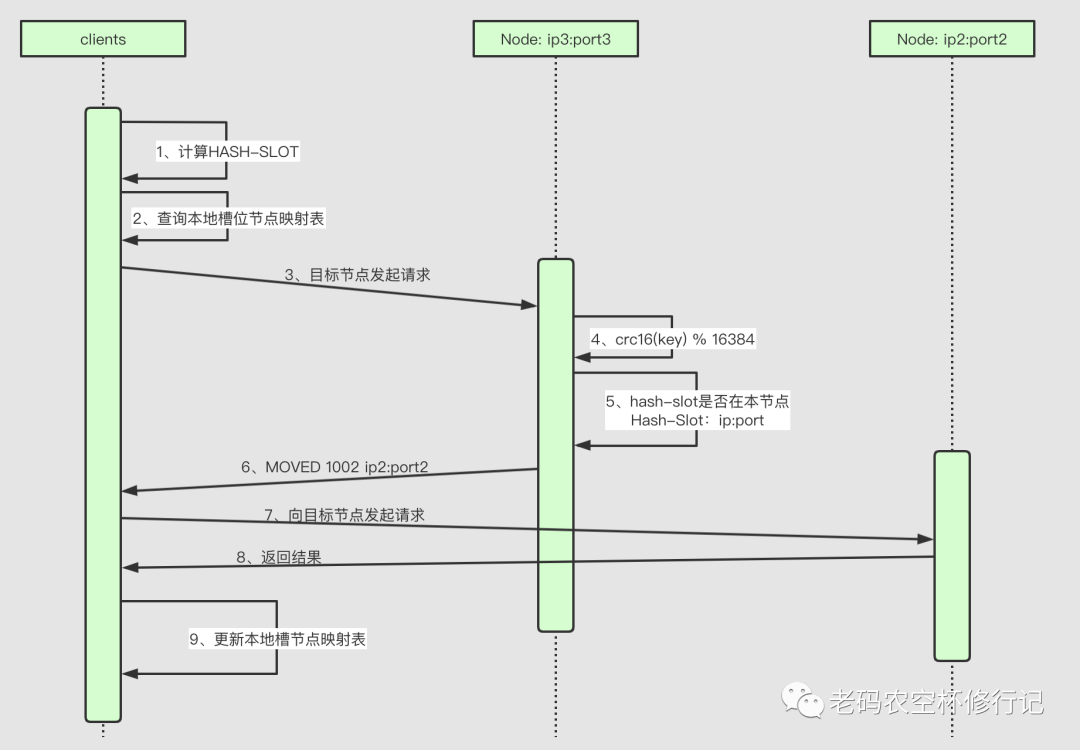
客户端连接任意一个节点 客户端发送请求,比如:get name 节点计算 name 的 HASH-SLOT: crc16(name) mod 16384= 5798 节点查询本节点槽位节点映射表,发现是自己,则处理请求并返回 节点查询本节点槽位节点映射表,发现是槽位归其它节点,则返回重定向MOVED 信息(MOVED 槽位 ip:port) 客户端若得到错误响应,并且是重定向错误,则连接重定向的节点处理请求
连接节点是 SLAVE, 并且不是只读请求,必定重定向,SLAVE 默认不处理任何请求,只是故障时替代其对应 MASTER的作用 槽位不归本节点
客户端优化
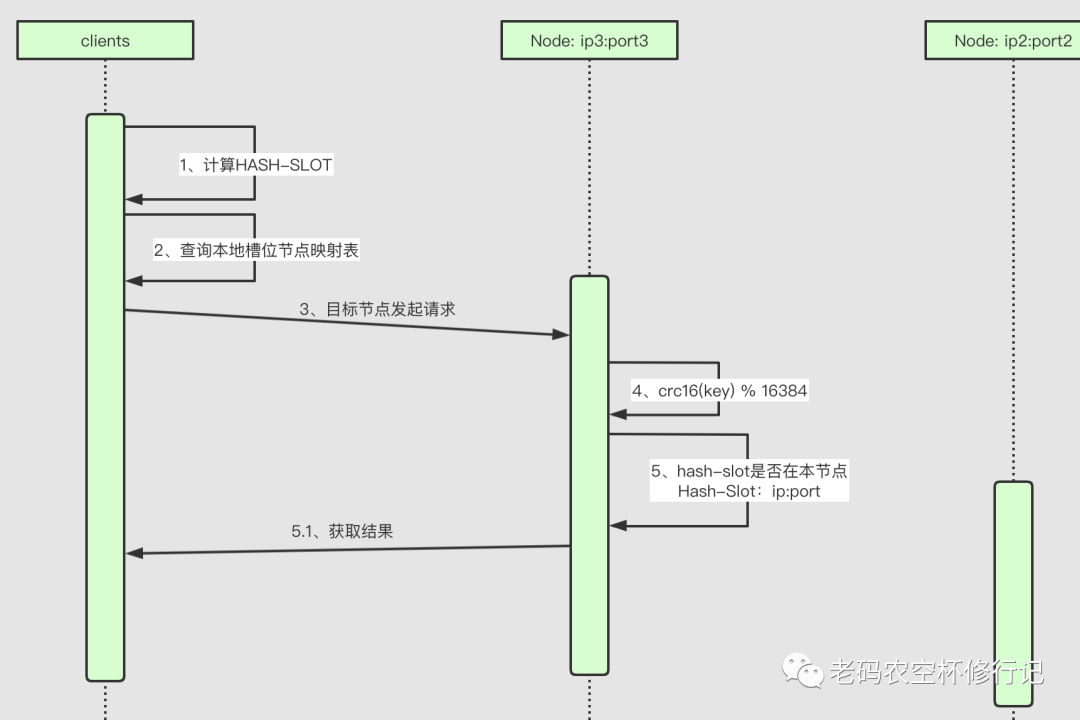
当然也有意外,比如服务端发生槽位迁移,此时则可以通过重定向更新,更新之后再刷新本地表
集群中的各个节点如何知道其它节点槽位信息?
默认情况下,SLAVE 节点只是当做备份节点,一旦对应 Master 故障,SLAVE 被提升为 Master,其流程如下
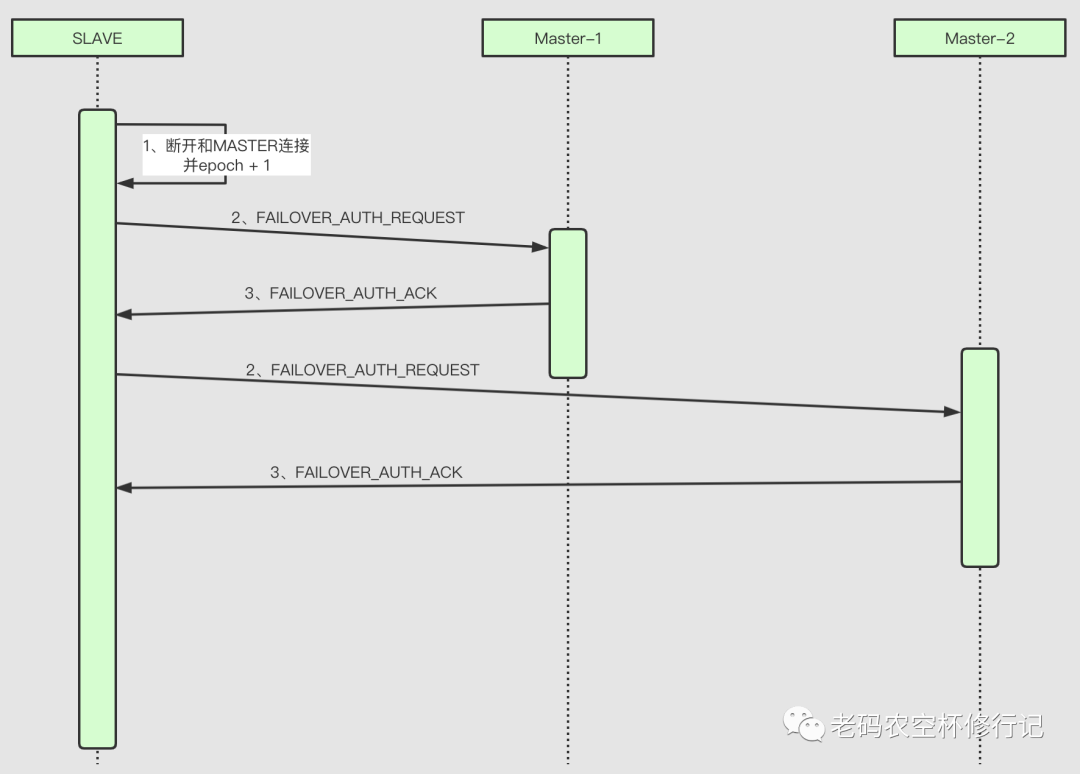
断开和主节点的链接
提升自己的配置版本 epoch + 1(比如:3+1)
向所有的 Master 节点发起 FAILOVER_AUTH_REQUEST 投票请求
在 2 * NODE_TIMEOUT 周期内若大部分 Master 回复 FAILOVER_AUTH_ACK,则竞选成功
触类旁通,为什么能触类旁通?原因是学东西有没有学到本质的东西,直达本质才发现很多都是相似,从而如同轻车熟路。人说你不开窍,我想不开窍不是因为笨,而是没有到本质。
存储中,无论redis、mysql,可能实现不同,应对场景不同,但是破局瓶颈时几乎都是类似的,已mysql和redis为例,无非通过以下几种方式:
高可用
主从结构,主宕机或故障,从节点提升为主
读性能瓶颈
写性能瓶颈
