




在一中我们知道X-Stream是单机图计算系统,In-memory和Out-of-core方式都支持,在三中介绍了其在Out-of-core情形下的流处理方法,本文则详细介绍其In-memory Streaming 图处理引擎。
In-memory Streaming Engine
In-memory引擎一般是用来处理规模较小的图,它的顶点、边和运行时的更新集都能放入内存的情况。而设计上重点考虑的是并行性,需要使所有可用的core来达到内存的峰值流带宽。除此之外,并行是为了充分利用所有可使用的计算资源(例如浮点计算单元)。因此,我们讨论了内存流引擎中并行性的重要构建块。第二个问题是In-memory引擎必须处理比Out-of-core流引擎更多的分区。这需要使用§4.2中描述的多级shuffler。
In-memory引擎在选择流分区数量时考虑CPU cache大小,即每个分区的顶点数据能放入CPU的cache中。跟磁盘不同,我们不能直接控制block在cache上的分配。In-memory流引擎必须考虑引入额外的数据,而不会移动顶点。观察到边和更新必须引用顶点而不将其从高速缓存中移出,因In-memory流引擎将顶点footprint为顶点数据大小,边大小和更新集大小的总和。然后,它将图中所有顶点的总占用空间除以可用CPU高速缓存的大小,以得出最终的流分区数。
引擎需要额外三个stream buffers,一个用于存放图的边,一个用于存放生成的更新集,另一个用于shuffle阶段使用。对于每个流分区,我们先加载边到input stream buffer,并shuffling它们到一个边chunk。然后处理一个接着一个的流分区在Scatter阶段生成的更新集。所有生成的更新都被append到一个output stream buffer中。最后output stream buffer开始shuffle每个流分区的更新块,并在收集阶段被使用。
Parallel Scatter-Gather
我们并行化的Scatter-Gather方法是基于这样一个观察,即不同的流分区的处理是可以独立完成的。支持并行的Scatter-Gather需要了解共享cache(计算流分区数量)。我们假设底层核心使用共享缓存的份额相等。
线程执行不同的流分区依然要求append它们的更新到一个相同的chunk数组中。每个线程首先写到一个私有的8K大小buffer中,该缓冲区会被刷新到共享输出块数组,先原子地更改共享输出块数组的末尾值,然后再附加私有缓冲区的内容到对应位置。
并行的处理流分区会导致严重的负载不均衡,因为每个分区会分到不同数量的边。因此,我们在X-Stream中实现Work-Stealing,允许线程去“偷”其它流分区的任务。这使X-Stream可以避免线程负载不均衡问题,需要In-memory[44]或Out-of-core[31]图处理系统的专用解决方案。
Parallel Multistage Shuffler
In-memory引擎与Out-of-core相比必须处理大量的划分,这是由于CPU的cache空间远小于内存空间和并且现代的架构也意味着cache的大小也不会迅速增长。重复3.4的分析,对于1TB的顶点数据(系统的内存大于1TB)和1MB的CPU cache,我们需要至少1M个分区,来保证能在每个分区的cache中随机访问顶点数据。shuffle大量分区会对维持我们利用内存顺序访问带宽的设计目标带来巨大挑战。
由于两个原因,来自CPU内核的顺序访问为内存提供了更高的带宽。第一个是多核处理器硬件及的预取特性可以跟踪多个流。预取用于输入和输出流上,有利于隐藏对存储器的访问的延迟(对于顺序访问而言较高带宽的主要来源)。不断增加的流意味着我们会失去硬件预取带来的好处。顺序访问的第二个好处是由于最大的空间局部性,因为每个cache line在被驱逐之前会被完全使用。只有当我们可以从输入流和缓存中的所有输出流中调整高速缓存行时,才能实现这一点。由于分区数量较多,因此不再是这种情况(最靠近核心的SRAM缓存通常只能容纳512到1024个64字节的缓存行)。
受到cache-conscious排序[51]中类似问题解决方案的启发以及Phoenix [45]或tiles map-reduce [24]等系统的启发,我们为X-Stream中的内存引擎实现了一个多阶段shuffler。我们把划分分组成一个层次树结构,树的平衡因子为F. 这是在X-Stream中通过强制执行In-memory引擎的流分区数量为2的幂并且还将树的F设置为2的幂来完成的。然后通过使用分区ID的最高有效b位来隐式地维护树,以在具有2b个节点的树级别的分组之间进行选择。然后,我们为此树中的每个级别执行一个shuffle步骤。输入由一个流缓冲区组成,该缓冲区具有与树中该级别的节点一样多的块。每个输入块被shuffle到F输出块中。给定K个分区的目标,多级shuffle器可以将输入混合到以⌈logFK⌉步骤向下的K块中。我们在shuffle过程中使用了两个流缓冲区,在输入和输出角色之间交替使用它们。
可以设置F,记住上述约束。对于本文中的实验,我们将其限制为CPU缓存中可用的缓存行数。但是,在大多数情况下,我们也处于硬件预取中跟踪流数量的限制范围内,这是我们没有专门调整的微观架构细节。
我们观察到流缓冲区通常比分区携带更多的对象。我们的实验(§5)导致In-memory流中有超过十亿个对象,但从不需要超过1K的分区。即使有多个阶段,这也会导致改组比分类更便宜,这是我们在评估中回归的一点。
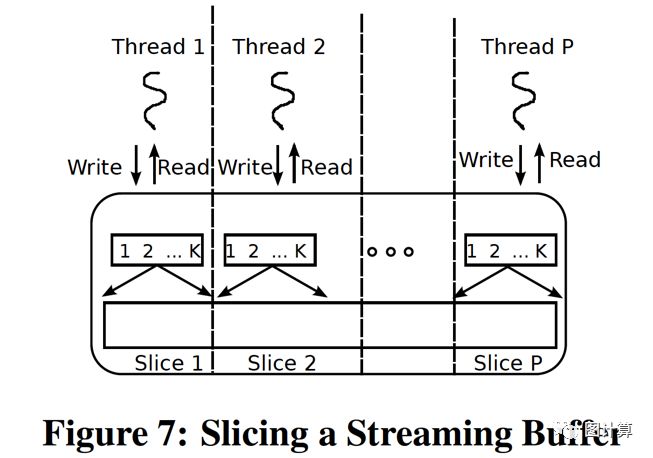
为了在多阶段shuffle器中启用并行性,我们需要能够让线程在流缓冲区上并行工作,而不需要同步。我们的解决方案是为X-Stream线程分配不相等的流缓冲区的大小切片。每个线程只接收一个切片。图7显示了如何跨线程切片流缓冲区。每个线程都有一个独立的索引数组,用于描述流缓冲区切片中的块。一个线程只允许在混洗期间访问自己的切片。我们通过指定每个线程来自动切换它自己的切片来并行化shuffle步骤。由于目标分区的数量在所有线程中是相同的,因此它们都在同一输出流缓冲区中以最终切片结束,此时它们会同步。
对应于流分区的块是来自所有片的对应块的并集。因此,线程可以在分散期间恢复块,并使用顺序访问加上最多P个随机访问从切片流缓冲区收集步骤,其中P是线程数。通常,线程数P远小于块中对象的数量,使得随机访问可忽略不计。
Layering over Disk Streaming
In-memory引擎在逻辑上分层在Out-of-core引擎之上。我们这样做是允许磁盘引擎独立选择流分区的数量。对于图6中的流循环的每次迭代,使用In-memory引擎处理加载的输入块,然后In-memory引擎独立地为当前磁盘分区选择进一步的内存区。
这使我们能够确保使用Out-of-core流引擎最大限度地利用内存带宽和计算资源。在所有情况下,较慢的磁盘仍然是瓶颈,即使使用较快的磁盘(如SSD)和在某些图形算法中使用浮点计算也是如此。

Paper: https://infoscience.epfl.ch/record/188535/files/paper.pdf
PPT: http://sigops.org/sosp/sosp13/talks/roy_xstream_se09_04.pptx
Videos: https://www.youtube.com/watch?v=3YkpUEnLW4s
Source code: https://github.com/epfl-labos/x-stream
本文内容仅个人观点,如有错误和不足之处还望大家雅正,如果对您有所帮助则是我的荣幸,如需本文相关资料请发邮件到zhangguoqingas@gmail.com或留言!
