




SSTable 是 Sorted String Table 的简称,是大名鼎鼎的 Bigtable 底层的数据存储格式。 SSTable 文件是用来存储一系列有序的 KeyValue 对的,Key 和 Value 都是任意长度的字节串, KeyValue 对根据固定比较规则有序地写入到文件中,文件内部分成一系列的Blocks(Block 不会太大,可自定义,默认4KB,常见的是 64KB ),同时具有必要的索引信息。这样 就既可以顺序地读取内部 KeyValue 记录,也能够根据某个 Key 值进行快速定位。
在了解RocksDB数据的读写流程前,掌握SSTable的数据存储格式是非常有必要的,学习SSTable的数据存储格式可以类比Mysql InnoDB的表空间存储结构以及数据页结构,通过对比学习,体会RocksDB和InnoDB针对不同应用场景的设计考虑及其设计的精妙之处。
首先看下SSTable的数据检索过程:
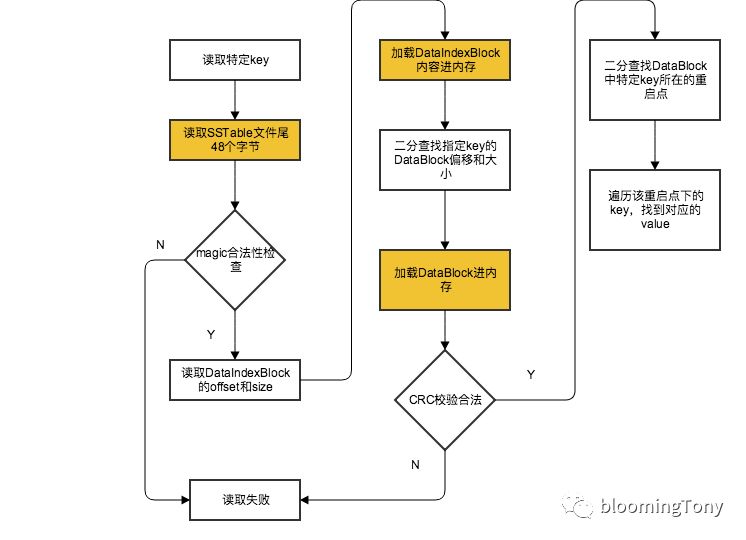
黄颜色的流程块可能涉及磁盘随机IO(未命中cache)。
其次看下SSTable的存储格式:
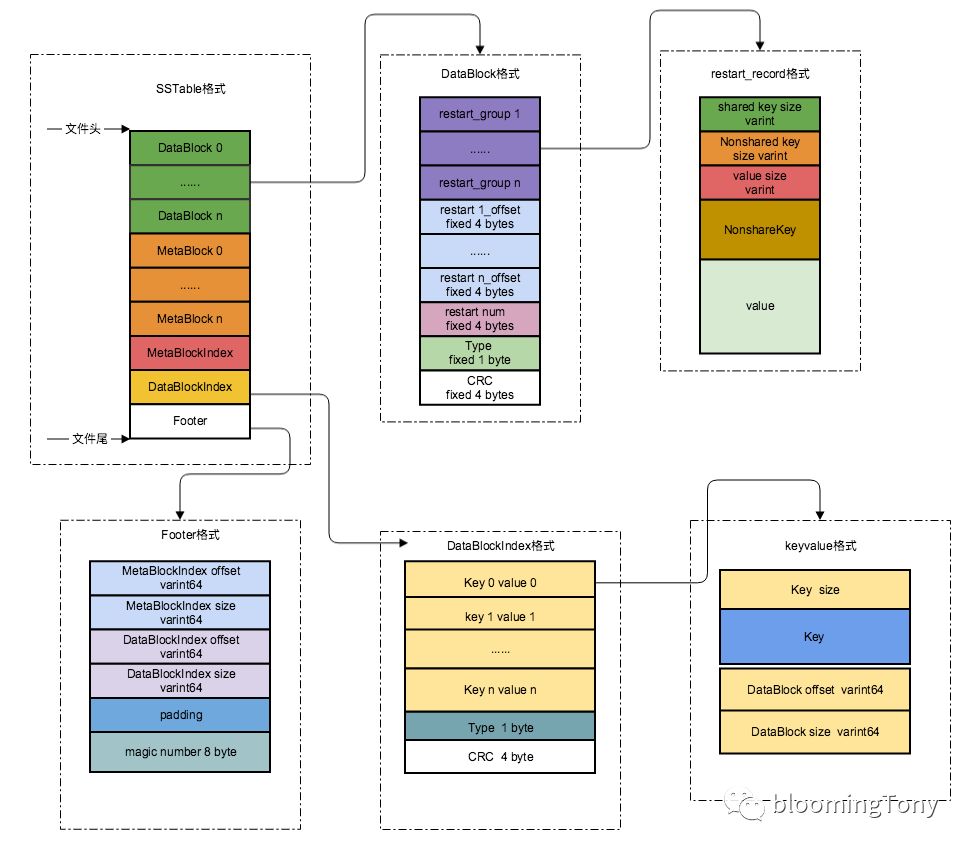
SSTable格式:
包括 DataBlock(可能多个)、MetaBlock(可能多个)、MetaBlockIndex(占用1个block空间)、DataBlockIndex(占用1个block空间)、Footer(固定48个字节);
Footer格式:
Footer固定48个字节大小,位于SSTable文件尾部;MetaBlockIndex和DataBlockIndex的offset和size组成BlockHandlel类型,用于寻址MetaBlockIndex和DataBlcokIndex的块所在的位置,size和offset采用varint变长编码,以节省空间,offset和size最少占用1个字节长度、最多占用9个字节长度,因此MetaBlockIndex和DataBlockIndex的offset和size最多占用4*9=36个字节,通过padding补齐到40个字节(8字节对齐);
比如DataBlockIndex.offset = 64、DataBlockIndex.size=216,表示DataBlockIndex位于SSTable文件的第64个字节至280个字节;
DataBlockIndex格式:
DataBlockIndex包含DataBlock索引信息,用于快速定位到包含特定key的DataBlock;DataBlockIndex首先是一个block,因此包含三部分KeyValue、Type(固定1字节)、CRC检验码(固定4字节);Type标识该部分数据是否采用压缩算法,CRC是KeyValue + Type的检验码;key的取值是大于等于其索引block的最大key,并且小于下一个block的最小key;value也是BlockHandle类型,由变长的offset和size组成;这里有两个问题:
为什么key不是采用其索引的DataBlock的最大key?
主要目的是节省空间;假设其索引的block的最大key为"acknowledge",下一个block最小的key为"apple",如果DataBlockIndex的key采用其索引block的最大key,占用长度为len("acknowledge");采用后一种方式,key值可以为"ad"("acknowledge" < "ad" < "apple"),长度仅为2,并且检索效果是一样的。
为什么BlockHandle的offset和size的单位是字节数而不是block?
因为SSTable中的block大小是不固定的,虽然option中可以指定block_size参数,但SSTable中存储数据时,并未严格按照block_size对齐,所以offset和size指的是偏移字节数和长度字节数;跟Innodb中的B+树索引block偏移有区别。这样做主要有两个原因:
(1)RocksDB可以存储任意长度的key和任意长度的value(不同于Innodb,限制每行数据的大小为16384个字节),而同一个key-value是不能跨block存储的,极端情况下,比如我们的单 个 value 就很大,已经超过了 block_size,那么对于这种情况,SSTable 就没法进 行存储了。所以通常,实际的 Block 大小都是要略微大于 block_size 的;
(2)从另外一个角度看,如果严格按照block_size对齐存储数据,必然有很多block通过补0的方式对齐,浪费存储空间;
MetaBlock格式:
由于数据的读取未涉及MetaBlock和MetaBlockIndex,本文暂不介绍Meta相关的内容。
DataBlock格式:
DataBlock是KeyValue数据存储块,跟DataBlockIndex一样包含三部分:KeyValue、Type、CRC校验;
KeyValue部分根据根据各个重启点划分了不同的restart_group;紧接着restart_group后面是每个restart_group的偏移量(restart_point)(固定四字节);最后是四个字节的restart_point num,指示该DataBlock的重启点的总数;
前缀压缩:
DataBlcok Key 的存储采用了前缀压缩机制,前缀压缩的概念很简单,就是对于 key 的相同前缀,尽量只存储一次以节省空间。但是对于 SSTable 来说它并不是对整个 block 的所有 key 进行一次性地前缀压缩,而是设置了很多区段,处于同一区段的 key 进行一次前缀压缩,每个区段的起点就是一个重启点。之所以设置很多区段是为 了更好的支持随机读取,这样就可以在 block 内部对重启点进行二分,然后再在单个区段内遍历即可找到对应 key 值的记录,所以分段压缩就承担了 block内部二级索引的功能。如果整体进行前缀压缩,那么就没法在 block 内进行二分,只能遍历,因为如果要恢复第 i+1 条记录需要知道第 i 条记录的 key,如果要恢复第 i 条记录需要知道第 i-1 条记录的 key,如此递归下去,意味着都要从第一条开始, 才能将 key 恢复出来。这样 block 内部的查找就必须是顺序的了。
前缀压缩机制导致每条记录需要记住它对应的 key 的共享长度和非共享长度。所 谓 key 的共享长度,是指当前这条记录的 key 与上一条记录的 key 公共前缀的长 度,非共享长度则是去掉相同部分后的不同部分的长度。这样当前这条记录只需要存储不同的那部分 key 的值即可。
同时分段压缩,又导致在 block 尾部需要用一个数组记录这些重启点的 offset, 同时 block 的最后 4 个字节则被固定用来保存重启点的个数,同时每个重启点都 是一个 4 字节的整数,这样知道了 block 起始地址及长度后,很容易就能计算出 restarts了。加上这些机制之后,导致解析过程变得比较复杂,但是解析速度还是很快的(按照重启点二分查找)。另外每条记录的 key 共享长度,key 非共享长度,value 长度本身进行 了 varint32 变长编码,这又是一个节省空间的优化。
SSTable中的key按顺序从小到大排序存储,相邻的key会有很长的公共前缀;比如三个key-value,
{
"apple_b" : "I am blue"
"apple_g" : "I am green",
"apple_y" : "I am yellow"
}
这三个key-value在"apple"这个重启点的存储样式:

总结
结合RocksDB的数据读取流程,分析完了SSTable的数据存储格式;上述的分析只是浅析,帮助大家从宏观上对SSTable有个大概的认识,还有很多细节,比如数据压缩、数据存取迭代器、布隆过滤器等,需要结合RocksDB的源码细细品味作者为提升RocksDB性能而做的各种优化。
