




前面(一,二,三和VENUS)已经对GraphChi[1]做了全面的介绍,本篇则做个简单的总结和测试体验。GraphChi衍生于GraphLab项目,是CMU和华盛顿大学的合作成果。GraphChi之所以引起广泛关注,是因为它仅在单个PC上就能处理大规模的图数据,性能还远远高于很多著名的分布式系统,如Hadoop,Spark,Stanford GPS (Pregel), Pegasus和分布式GraphLab等。
项目源码[1]中的介绍https://github.com/GraphChi/graphchi-cpp/wiki/Introduction-To-GraphChi,将图分割为P个包含边数量几乎相等的shards,采用Parallel Sliding Windows (PSW)实现顺序读写的方式从磁盘中加载图数据到内存中进行execution intervals计算。具有以顶点为中心的计算模型,能异步的,并行的执行图算法,支持选择调度等特性。能高效处理用于边数量达billions级别的图,允许动态修改图结构,无依赖的单机环境使得它极易安装和简化开发维护。
GraphChi runs vertex-centric programs asynchronously (i.e changes written to edges are immediately visible to subsequent computation), and in parallel.
1 例子
下图是一个简单的例子[2],它展示了两个execution intervals。原图中有6个顶点,被分割为三个数量相等的intervals:1-2, 3-4和5-6。对应的三个shards结构分别包含了若干条边,每个shard中边的数量几乎相等,且严格按照源顶点编号升序排列。图(a)显示了三个shards的初始内容。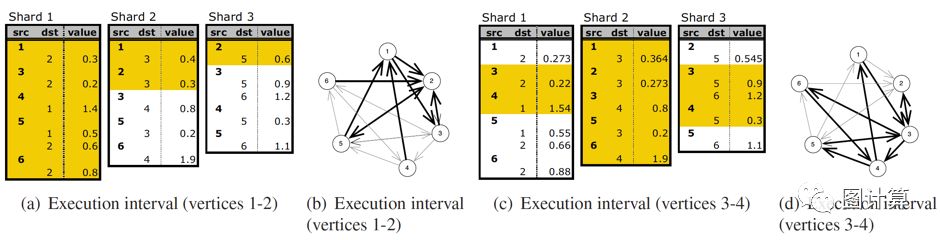
PSW从execution intervals 1开始,并加载包含在图(b)中以粗体显示的边的子图。Shard 1是内存分片,它被完全加载,包含顶点1和顶点2的所有入边,以及出边的子集。Shard 2和3是滑动部分,窗口从Shard的第一条边开始。Shard 2包含顶点1和2的两个出边,shard 3只有顶点2的一个出边。如图(a)中黄色标注区域。
将图加载到内存后,PSW运行顶点1和2的更新函数。执行更新后,修改的部分将写入磁盘,更新的值可以在图(c)中立即被使用。
PSW然后移动到第二个区间execution intervals 2即顶点3和4,图(d)以粗体显示了相应的边,图(c)黄色区域显示了加载的区块。现在Shard 2是内存分片,对于Shard 3,我们可以看到第二个区间的块紧接着在第一个块中加载的块之后出现。因此,PSW只是在shard中向前“滑动”一个窗口。
2 运行GraphChi
GraphChi的开源在Github上[1]上(也有java版本:graphchi-java),我们使用CentOS 7在email-EuAll数据上运行PageRank算法,来简单的测试/体验它[3]。
# git clone https://github.com/GraphChi/graphchi-cpp.git
# cd graphchi-cpp
# make all
1 输入数据与预处理
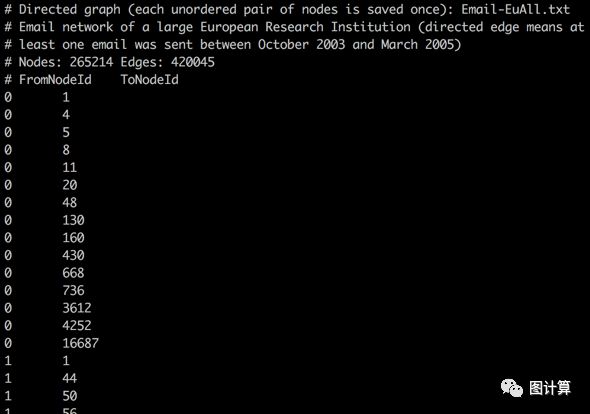
之前的文章[4]中介绍了公开的图数据,这里http://snap.stanford.edu/data/也给出了不同大小的图数据供测试。GraphChi需要对数据进行预处理,不同的applications可重复使用预处理后的数据。现有的example_apps在执行前会自动检测数据是否已被分割,并视情况执行Preprocessing,此处我们使用email-EuAll [5]数据集。
wget http://snap.stanford.edu/data/email-EuAll.txt.gz
gzip -d email-EuAll.txt.gz
cp email-EuAll.txt path/graphchi-cpp
2 运行前可以根据系统资源和数据规模进行简单的配置
# vim conf/graphchi.cnf
loadthreads = 4
niothreads = 2
membudget_mb = 800 # 可供GraphChi使用的内存大小
cachesize_mb = 0
io.blocksize = 1048576
mmap = 0 # Use mmaped files where applicable
metrics.reporter = console,file,html
metrics.reporter.filename =graphchi_metrics.txt
metrics.reporter.htmlfile =graphchi_metrics.html
3 Pagerank算法,结束后打印Top 20的顶点ID和PageRank值
# bin/example_apps/pagerank file ./email-EuAll.txt niters 20
 根据边集文件选择类型,这里是边列表文本文件edgelist
根据边集文件选择类型,这里是边列表文本文件edgelist
根据系统资源配置构造shards(即预处理)和报告,可以修改配置看看shards数量,预处理时间等。由于email-EuAll.txt边列表文件仅4.8M,默认的shard数量是1,则可以修改membudget_mb = 2根据输出观察具体的执行过程:
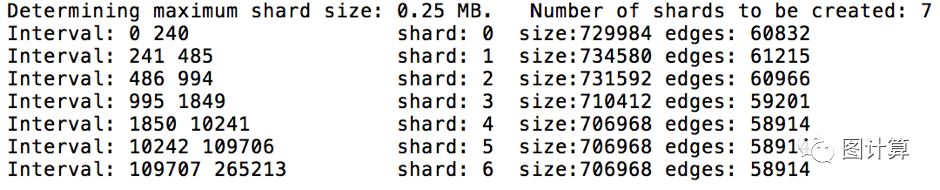 可以看出7个顶点interval的大小并不相等,而每个shard的大小几乎相同。
可以看出7个顶点interval的大小并不相等,而每个shard的大小几乎相同。
接下来就是20次迭代,每次迭代使用PSW依次遍历每个execution intervals,输出的信息比较完整,自行观察。

还可以在当前文件夹下看到很多中间辅助文件,metrics文件和结果文件email-EuAll.txt.4B.vout(4B表示结果的每个数值占4个字节)。
对于Pagerank算法,PSW没有必要加载out-edges,即没有读操作只有写操作,pagerank_functional则是一个改进版本。
# bin/example_apps/pagerank_functional file./email-EuAll.txt niters 20
但是运行结果不一样!
3 讨论与不足
(1)GraphChi的预处理,其shard中的边是否一定需要严格按照源顶点ID升序排列?因为这耗费大量的预处理时间。应该可以将每个shard分成P个区间,只要保证边的源顶点区间有序就行<有待测试>;
(2)PSW对计算密集型的算法更有利,因为内外存交换数据时所花费时间不可忽略,是否可以考虑计算和I/O并行,预加载,流处理等方式;
(3)构建子图时需要大量的随机访存,intervals的数量P值随着图的规模增大而增大,则磁盘I/O也随之增加,特别是随机读写;
(4)顺序地更新有共享边的顶点避免数据,解决数据争用的问题;
(5)即使采用选择调度特性,磁盘I/O读写操作,大部分都不是计算所需要数据;
(6)准确的说PSW的回写步骤是对“更新集”的操作,可以从回写数据量和回写方式两方面着手优化;
(7)没有从更细的Cache/Memory/Disk三层两级存储结构上考虑性能问题。
由于图算法的计算量是一定的,由此可见对于Out-of-core图计算系统,内外存交换的效率直接影响着系统的整体性能。华为的诺亚图计算系统VENUS则是在GraphChi基础上改进:(1)使用v-shard和g-shard结构分别存储vertices集和edges集;(2)把计算过程中的更新,集中到vertices数据上,并尽量将其存储在内存中,消除了更新集回写的步骤;(3)流式遍历g-shard中edges,可以预留更多的内存空间存储尽量多的顶点数据;(4)整体的遍历呈流水线式的并行I/O和计算。
虽然VENUS做了很多优化,性能提升显著(3至10倍),但更彻底的改进在GridGraph中体现的更全面,敬请期待对单机Out-of-core图计算系统GridGraph的剖析。
[1] C++版本GraphChi源码, https://github.com/GraphChi/graphchi-cpp
[2] Simple-Example , https://github.com/GraphChi/graphchi-cpp/wiki/Introduction-To-GraphChi#simple-example
[3] Example-Apps , https://github.com/GraphChi/graphchi-cpp/wiki/Example-Apps
[4] 常见的大规模图数据及其特点
[5] EU emailcommunication network, http://snap.stanford.edu/data/email-EuAll.html
[6] LiveJournal socialnetwork, http://snap.stanford.edu/data/soc-LiveJournal1.html
本文内容仅个人观点,如有错误和不足之处还望大家雅正,如果对您有所帮助则是我的荣幸,如需本文相关资料请发邮件到zhangguoqingas@gmail.com或留言!
