




GraphX简介
GraphX是构建在spark之上的图计算框架,是Spark推出的一种新的API,用于图和分布式图(graph-parallel)的计算(e.g,PageRank和Collaborative Filtering<协同过滤>)。在高层次上,GraphX通过引入弹性分布式属性图(ResilientDistributed Property Graph)而拓展了SparkRDD抽象,弹性分布式属性图是顶点和边均有属性的有向多重图。为了支持图计算,GraphX开发了一组基本的操作符(e.g,subgraph、joinVertices、mapReduceTriplets等)以及一个优化了的PregelAPI变体,除此之外,GraphX包含了一个快速增长的图算法和图构建器集合来简化图的分析任务。
图处理
随着网络的发展,信息的重要性和对各类数据的处理计算已经推动了许多分布式图计算系统的发展,如图1,分别是分布式数据计算系统(Hadoop,Spark)和分布式图计算系统(Pregel,GraphLab,Giraph)。
图1 分布式数据系统和分布式图系统
在性能方面讲,分布式数据计算系统的处理速度比不上分布式图系统,分布式图系统在执行复杂的图算法时,比GraphX这类的分布式数据计算要快很多,但是有利必有弊,由于分布式图系统是针对像PageRank这样的迭代算法进行优化的,因此它更适合图的处理,可是在典型的图处理流水线中,它并不很好的处理所有操作,例如,构造图、修改其结构,或者跨越多个图进行计算。更准确的说,分布式图系统提供的更窄的计算视图无法处理那些构建和转换图结构以及跨越多个图的需求。分布式图系统中无法提供的这些操作需要数据在图本体之上移动并且需要一个图层面而不是单独的顶点或边层面的计算视图。例如,我们可能想将我们的分析限制在几个子图上,然后比较结果,这种处理不仅需要改变图结构,还需要跨越多个图计算。GrpahX中的图处理流水线。如图2
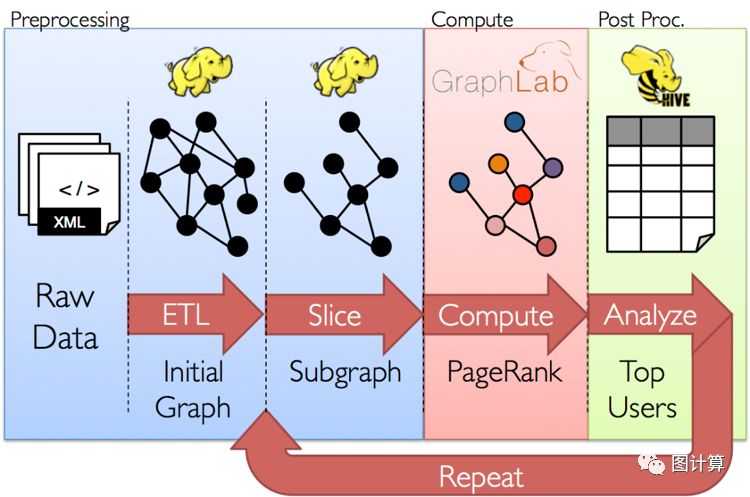
图2 GrpahX的图处理流水线
这个处理过程是,先获得元数据,然后根据元数据经过ETL(Extract-Transform-Load)即抽取、转换、加载三个步骤来初始化图,再利用图分割算法获得子图,在子图的基础上,对其进行下一步的目标操作,图例中采取的是PageRank算法,执行完计算操作后,我们对结算结果进行查看分析,获得排名靠前的数据信息。我们如何处理数据取决于我们的目标,有时同一原始数据可能会处理成许多不同表和图的视图,并且图和表之间经常需要能够相互移动。如图3
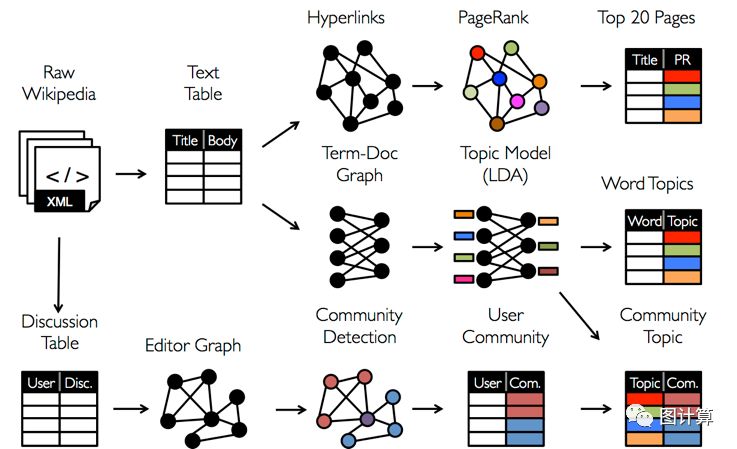
图3 实例
这个实例展现的是同一种元数据,根据目标的不同,选择的视图不同,采用的计算算法也不同,但是这些操作都是可以在GraphX中完成的,既有分布式数据计算,也有分布式图计算。GraphX将graph-parallel和data-parallel统一到一个系统中,并提供了一个唯一的组合API,GraphX允许用户把数据当做一个图和一个集合(RDD),而不需要数据移动或者复制。也就是说GraphX统一了Graph View和Table View,可以非常轻松的做pipeline操作,这就大大的提升了分布式图系统的性能。
GraphX中的视图
GrpahX中的核心抽象就是弹性分布式属性图,它拓展了Spark RDD的抽象,有表(Table)和图(Graph)两种视图,但是只有一份物理存储,每种视图都有其独立的操作符,用户既可以单独使用其中一种视图,也可以在需要的时候,组合使用这两种视图,保证了操作的灵活性和执行的高效率。从存储结构上来讲,我们也可以认为GrpahX有三种视图,如图4,有顶点(Vertex)、边(Edge)和边三元组(EdgeTriplet)三种视图,在这个里面,Vertex和Edge视图属于Table视图,EdgeTriplet属于Graph视图。
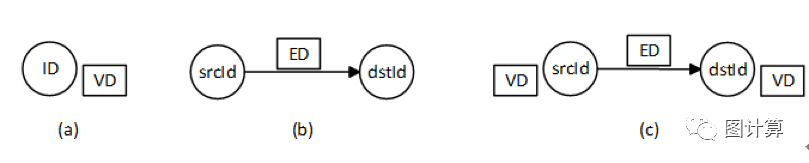
图4 GrpahX的三种视图
图(a)是顶点ID和顶点数据VD的集合,在存储时表示VertexTable[ID,VD];
图(b)是边的存储,源顶点ID、目标顶点ID以及边上携带的数据ED集合,在存储时表示为EdgeTable[srcID,dstId,ED];
图(c)是顶点和边形成的边三元组EdgeTriplet。
Table视图将图看成是顶点属性表(VertexProperty Table)和边属性表(Edge Property Table)的组合, 这些Table继承了SparkRDD的API(filter,map等),而Graph视图上包括reverse、subgraph、mapV(E)、joinV(E)、mrTriplets等操作。在Graphx中,对Graph视图的所有操作,最终都会转换为与其关联的Table视图的RDD操作来完成。如图5,是Table视图的一个实例:
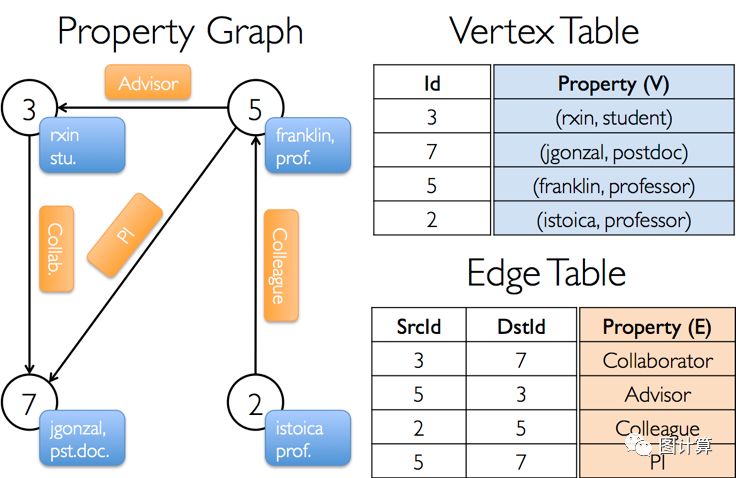
图5 Table视图实例
分割方式
一般的图分割方式分为边割和点割,如图6,而GrpahX借鉴了powerGraph,使用的是Vertex_Cut(点分割)方式分割和存储图,旨在减少通信和存储代价,这种存储方式特点是任何一条边只会出现在一台机器上,每个点有可能分布到不同的机器上。
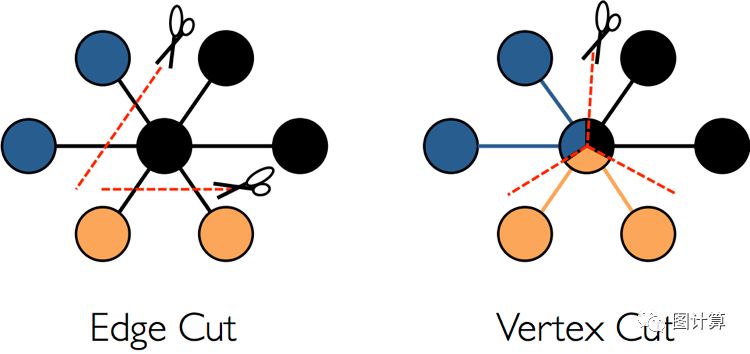
图6 点割和边割
图存储
GraphX中用三个RDD存储图数据顶点RDD、边RDD和路由表RDD(RoutingTable)。顶点和边的RDD中存储顶点集合和边集合,而路由表中记录的是顶点和顶点涉及的分区。
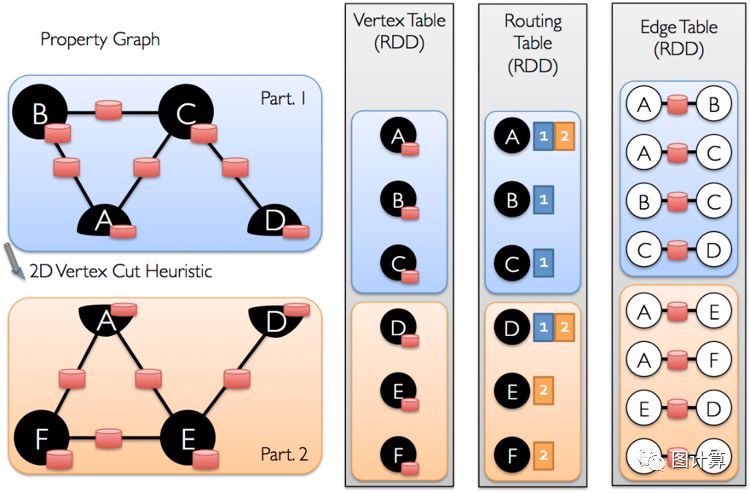
图7 分布式存储
图7中采用的具体分割策略是EdgePartition2D,这是一种二维的划分方法,能够将边划分至N个节点,尽可能的保持边分布的均匀性,从而保证计算负载的平衡。可以看到,按点割的方式将图分解之后得到Vertex Table RDD、Edge TableRDD和Routing Table RDD。GraphX在顶点RDD和边RDD的分区中以数组形式存储顶点数据和边数据,目的是为了不损失元素访问性能。GraphX在分区里建立了众多索引结构,高效地实现快速访问顶点数据或边数据。在迭代过程中,图的结构不会发生变化,因而顶点RDD、边RDD以及重复顶点视图中的索引结构全部可以重用,当由一个图生成另一个图时,只须更新顶点RDD和RDD的数据存储数组。索引结构的重用,是GraphX保持高性能的关键,也是相对于原生RDD实现图模型性能能够大幅提高的主要原因。
优缺点
优点:可以认为GraphX是Pregel和GraphLab在Spark上的重写及优化,综合了Pregel和GraphLab两者的优点:接口相对简单,又保证性能,采用的是点分割的图存储模式,能够进行符合幂律分布的自然图的大型计算,而GraphX最大的贡献就是,在Spark之上提供了一栈式数据解决方案,能够方便且高效地完成图计算的一整套流水作业。
缺点:GraphX API目前只能在scala中使用,在未来可能会发展出适合java和python操作的API。
实验操作
(1)GraphX Programming Guide
http://spark.apache.org/docs/1.0.0/graphX-programming-guide.html#eXamples
(2)Graph Analytics With GraphX
http://ampcamp.berkeley.edu/big-data-mini-course/graph-analytics-with-graphX.html
参考
GraphX: Unifying Data-Parallel andGraph-Parallel Analytics
Spark GraphX Source Analysis
Graph Analytics With GraphX
Spark GraphX原理介绍
本文内容仅个人观点,如有错误和不足之处还望大家雅正,如果对您有所帮助则是我的荣幸,如需本文相关资料/源码请发邮件到zhangguoqingas@gmail.com或留言!
