




经过七篇以翻译为主的漫长的,对分布式In-memory图计算系统Pregel的介绍,主要目的如下:(1)Pregel是一个具有代表性的图计算系统,深入研究它能带来创新启发和全面的了解图计算及其历史发展。(2)做研究或者获取最新的技术发展成果,必须要有从文献中获得知识的习惯。(3)了解一篇好的paper是什么样的,包括文章的结构组织、内容和词句表达,这对自己写文章很有帮助。(4)万事开头难此为首例,后续介绍图计算系统的文章将不会如此详细,将会只说重点。
本篇来对Pregel系统做一个全面的总结,结合其演讲PPT来说明是个不错的方法。
1. ABSTRACT和Introduction 部分
图计算的数据对象和常见应用:
类似于web图,社交图,由于规模(billion级别的顶点或trillion级别的边)极大而很难被高效处理。最短路径, 各种类聚, PageRank, 最小切分和连通图等,这些算法通常对应到现实世界中的问题求解。

图计算主要的挑战:
(1)图算法多为迭代计算,内存访问局部性较差
(2)每个顶点的计算量很少
(3)并行度随着顶点的出/入度变化
(4)分布式系统本地性问题
(5)分布式系统出错率高
(6)目前还没有能实现任意算法处理任意大规模图数据的通用的分布式计算系统
所以传统的单机系统或者分布式MapReduce模型无法高效处理图计算问题。
通用的图计算系统/引擎的要素:
(1)计算模型
(2)编程模型和系统编程接口
(3)系统架构
(4)系统容错
(5)伸缩性(数据规模/集群规模)
(6)负载均衡
(7)算法/应用库
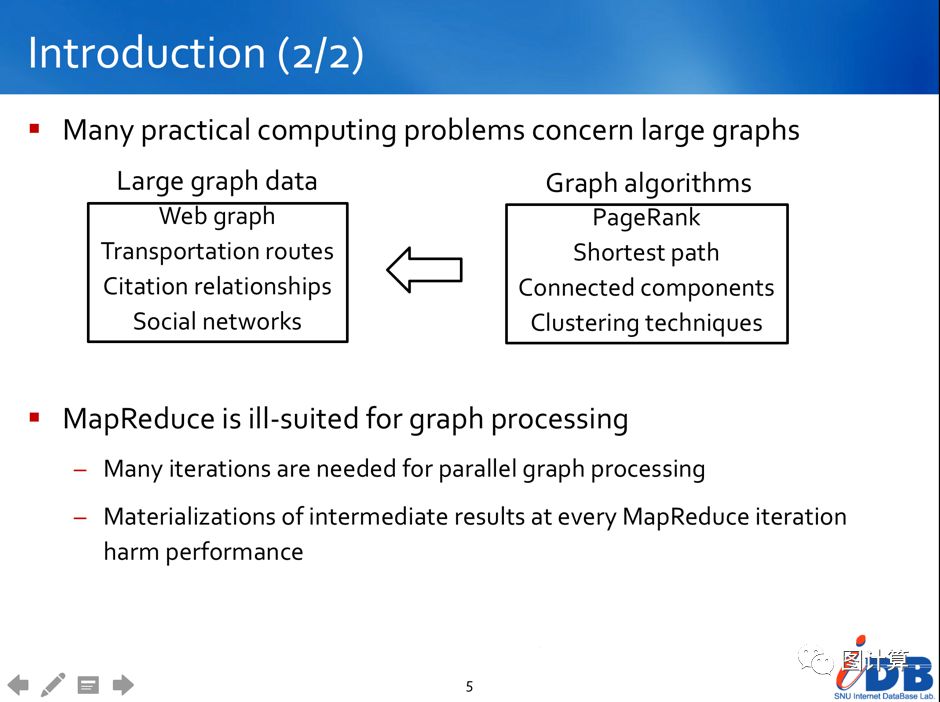
2. 以顶点为中心的编程模型和基于BSP框架的计算模型
由于图数据的主要信息都存储在顶点上,主要的计算工作也集中于顶点数据的更新,故以顶点为中心的图计算编程模型更容易交付给用户。
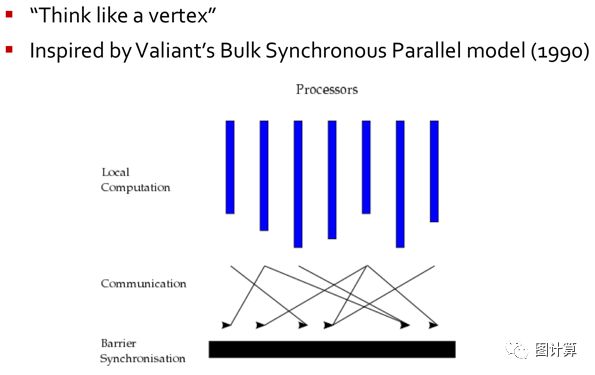
计算模型的设计首先要考虑输入数据和输出数据,都加载于内存中,故Pregel是分布式In-memory图计算系统,计算过程中没有多余的内外存交换开销。然后再详细规定计算模型的具体执行流程,Pregel采用BSP计算模型,它是典型的同步模型,优点是简单易于实现,明显的缺点是其有固定的同步Barrier,这对性能影响很大。计算模型定义了顶点的有限状态机,通过初始化和消息通知的方式改变顶点状态,消息则在超步之间传递。每个超步中的计算是并行的执行顶点函数,顶点的消息接收自入边,若有新的消息则通过出边发出至下一个超步。
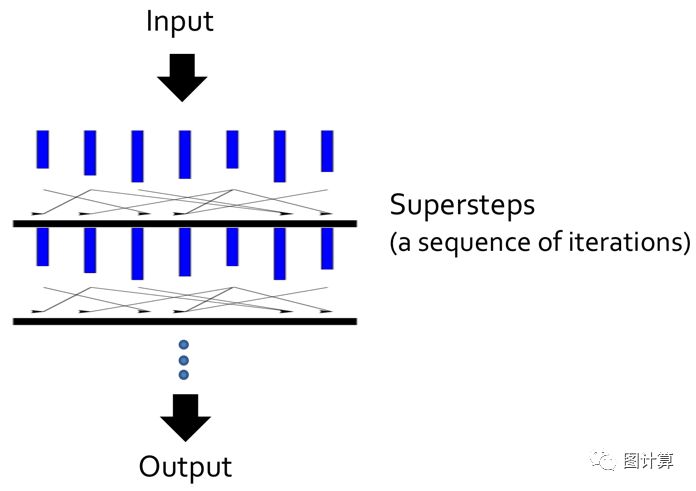
这样纯粹的消息传递模型的一个特点是隐藏了远程”读”操作(获得其它worker上顶点的属性值)由消息代替,具有内容由算法指定,因为用户更清楚需要传递什么信息;而”写”操作(更新顶点的属性)都是本地执行。整体上看超步推进的运行方式更适用于图的迭代算法。

当然系统计算模型的不足和优化空间也是可以通过编程模型的帮助来实现,其中Combiners可以将顶点V的几个消息合并成一个消息,这样可减少消息的数量(可节约传输时间和缓存空间)。Aggregators聚合器是全局通信,监测和数据的一种机制,使用reduction操作合并每个超步中顶点的相关值,可用于统计,全局协调等来加速算法完成。

Topology Mutations的缺陷:一些图算法需要改变图的拓扑,在一个超步内多个顶点可能会存在请求冲突问题(例如两个请求都是添加顶点V,并且初始值都不同)。使用部分有序化和处理程序两种方法来实现决断。[如何解决数据争用问题]
3. 系统架构和实现
Pregel架构上采用Master-Worker的集群模式,这点与MapReduce相同,所以也存在Master单点失效的风险,并且Master的情况也会限制集群的最大规模。优点是系统实现比较简单,Master会通过调度作业来优化集群资源的使用率或迁移任务。计算过程中数据均存储于集群的内存中,临时文件存储在节点的本地外存上,持久化数据存储在分布式文件系统中。则借助HDFS的实现提供了存储支撑,使用MapReduce实现BSP模型提供了计算支撑,所以早期有很多基于Hadoop的Pregel开源实现系统。

图计算其中的一个重要问题是图分割。Pregel采用典型的切边法,将图分割成许多的partitions,每一个partition包含了一些顶点和以这些顶点为起点的边(出边)。默认的partition函数为hash(ID) mod N,N为所有partition总数,但是用户可以替换掉它。切边法往往会带来巨大的通信开销,因为自然图中边的数量要远远大于顶点的数量,后续讲解PowerGraph时将会给出数学公式证明,一般结论是切点法比切边法能使图计算系统获得更好的性能。
用户也可根据具体的数据和算法自定义图分割的实现,来优化加速具体图计算应用。而Pregel程序的具体执行过程请参考分布式内存图计算系统之Pregel(五)这里不再赘述,Master和Worker具体的分工则由上图所示。
4. 系统容错、负载均衡以及测试实验
Pregel容错是通过check-pointing来实现的,在每个超步的开始阶段,master命令worker让它保存它上面的partitions的状态到持久存储设备,包括顶点值,边值,以及接收到的消息。Master自己也会保存aggregator的值。Master与Worker之间通过ping消息监测心跳决定是否执行恢复,通过消息日志则可加速恢复。
总体来说容错作为分布式系统的完整性,实现方面都比较常规。而Pregle中似乎没有提及负载均衡的问题,需要说明的是图分割对系统负载均衡问题影响很大。实验方面也没有关于容错和系统负载情况的展示。
文中实验运行在300节点的集群中,数据是随机生成的二叉树和自然图(均不是现实世界中的图),系统表现了较好的数据规模和集群规模的伸缩性。性能上的比较也较少,但明显强于Hadoop,且与Parallel BGL的△-stepping算法结果相当。
5. 相关工作、总结以及未来工作
(1)Pregel是一个分布式编程框架,专注于为用户编写图算法提供自然的API,同时将消息机制和容错等底层分布式细节隐藏起来。它实现了一个有状态的模型,在这个模型中进程会一直存活着,不断地进行计算,通信和修改本地状态等等,这与数据流模型不同,在数据流模型中进程只是在输入数据上进行计算,然后产生输出数据再交由其他进程处理。
(2)Pregel借鉴了BSP模型的思想,比目前已经存在大量的普通BSP库实现具有更好的可扩展性和容错性。需要说明的是1990年的BSP模型,并不是首先被Pregel系统使用,可能Parallel Boot Graph Library和CGMGraph才是Pregel的主要创新灵感。
(3)Pregel能处理顶点规模达到billions的图数据,在集群规模和资源配比很低的情况下,与很多传统的运行于专用的大型机(即非传统的商业服务器)的性能相当。还指出单机系统通过扩展内存磁盘来处理1B个顶点规模的图要花几个小时。
未来工作方面:
(1)Pregel可用性方面的改进,比如关于Pregel程序执行过程的详细信息的状态页面,unit testing框架,以及用来帮助用户进行快速原型开发和debug的单机运行模式。
(2)也提到希望Pergel可以支持规模太大以至于内存无法完全存下的情况,即分布式Out-of-core图计算系统,这也是我的研究方向,A22D Graph就是当前的成果。
(3)性能方面的提升,比如通过改善图分割减少通信开销,特别是稀疏图。

Pregel有很多开源的实现,比如基于Hadoop的Hama 和Giraph,基于Spark的Bagel等,后期将请东南大学刘子健同学与大家分享他在Giraph方面的研究工作。
本文内容仅个人观点,如有错误和不足之处还望大家雅正,如果对您有所帮助则是我的荣幸,如需本文相关资料请发邮件到zhangguoqingas@gmail.com或留言!
