




简单的说图计算就是研究在大规模图数据下,如何高效计算,存储和管理图数据等相关问题的领域。显然研究对象是大规模的图数据(Large-scale Graph-Structured Data),那么在我们的生活中有哪些比较常见的图数据呢?它们都有哪些具体的应用场景?图数据都有哪些特点?在进行图计算时都有哪些挑战?
哲学上说事物之间普遍存在联系,通常来说可以将事物看做图的顶点,事物间的联系看做图的边。对应于学术界的文献来说,每篇论文可以看做顶点,文献之间的引用关系可以看做边。对应于互联网来说,web页面可以看做顶点,页面之间的超链接关系可以看做边。对应于社交网络来说用户可以看做顶点,用户之间建立的关系可以看做边,关系的类别可以看做权重。对应于大型电商来说,用户和商品可以看做顶点(二部图),它们之间的购买关系可以看做边,购买次数可以看做权重。
则抽象出来的图数据就构成了研究和商用的基础,可以探究很多有趣的问题如:”权威节点(中心)”,”小圈子”,”世界上任意两个人之间的人脉距离”,”消息是如何传播的”等。而将这些有意思的现象用到商业领域,则底层的运算常常是图相关的算法。例如图的最短路径算法可以做好友推荐,计算关系紧密程度;最小连通图可以识别洗钱或虚假交易;Key person可以找到意见领袖,防止客户流失的群体效应;对图做PageRank可以做传播影响力分析,找出问题的中心,做搜索引擎的网页排名。虽然图计算的具体商业应用不是我所研究的问题,但后面可能会有具体的例子来详细介绍,敬请期待。

回到图计算的研究中,下表是在图计算研究领域中常用的开放数据集,前四个都是现实世界中抽象图数据,包括社交网络图和web图,其顶点或边的数量级达到million(百万,1000000,106)和billion(十亿,1000000000,109)。在研究中也会使用人工合成的图来测试图计算系统的相关特性,如trillion(万亿,1000000000000,1012)级别的图数据。需要说明的是trillion级别的图数据肯定是存在的,只是暂时没有看到公开的,并且随着社会的高速发展,那么billion级别的图也很快会达到trillion级别,甚至更大。
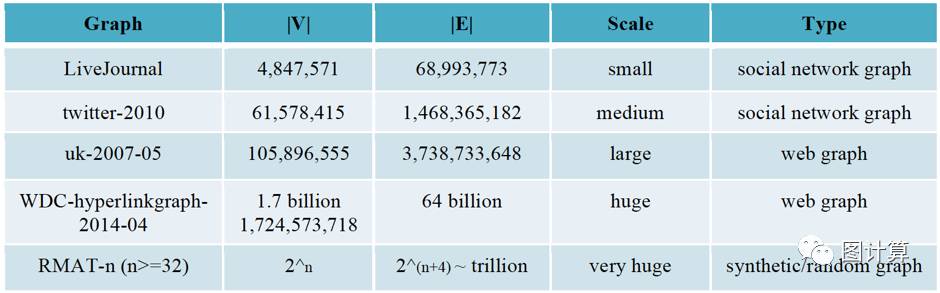
为了方便后面体验图计算系统和作为研究测试的基础,下面给出这些图的下载地址。其实寻找,整理和验证这些东西并不是件容易的事,望珍惜!其数据格式并不统一,后期将介绍如何处理这些图数据。
1 LiveJournal socialnetwork
http://snap.stanford.edu/data/soc-LiveJournal1.html
文本格式数据下载地址:
http://snap.stanford.edu/data/soc-LiveJournal1.txt.gz 1,080,598,042bytes (1.08 GB on disk)
2 twitter-2010
http://an.kaist.ac.kr/traces/WWW2010.html
压缩文本格式数据下载地址:
http://an.kaist.ac.kr/~haewoon/release/twitter_social_graph/twitter_rv.zip
twitter_rv.zip,4,859,337,443 bytes, MD5: 5f2399aac71c604ac5a100fb6ca7e297
3 uk-2007-05
http://law.di.unimi.it/datasets.php http://law.di.unimi.it/webdata/uk-2007-05/
graph格式数据下载地址:
http://data.law.di.unimi.it/webdata/uk-2007-05/uk-2007-05.graph
http://data.law.di.unimi.it/webdata/uk-2007-05/uk-2007-05.properties
4 WDC-HyperlinkGraphs-2014
http://webdatacommons.org/hyperlinkgraph/
http://webdatacommons.org/hyperlinkgraph/2014-04/download.html
http://webdatacommons.org/hyperlinkgraph/2014-04/data/
压缩文本格式数据下载地址:
wget -ihttp://webdatacommons.org/hyperlinkgraph/2014-04/data/index.list.txt
wget -i http://webdatacommons.org/hyperlinkgraph/2014-04/data/arc.list.txt
一共185GB左右,请做好心理准备。
以上所列都常被称为自然图(Natural Graph),其最明显的是Power-low[3]特性,即部分顶点的出度和入度极高,而绝大多数顶点的出入度极低。举例来说,在微博中有些大V拥有着数百万的粉丝,但这些大V是极少数的人,而绝大多数用户只拥有几十个甚至更少的粉丝。在淘宝上只有少数的商品销量惊人,但多数商品业绩平庸甚至无人问津。互联网上少数的网页访问量极高链入页面非常多,而大多数的网页链入数量少的可怜甚至为零。
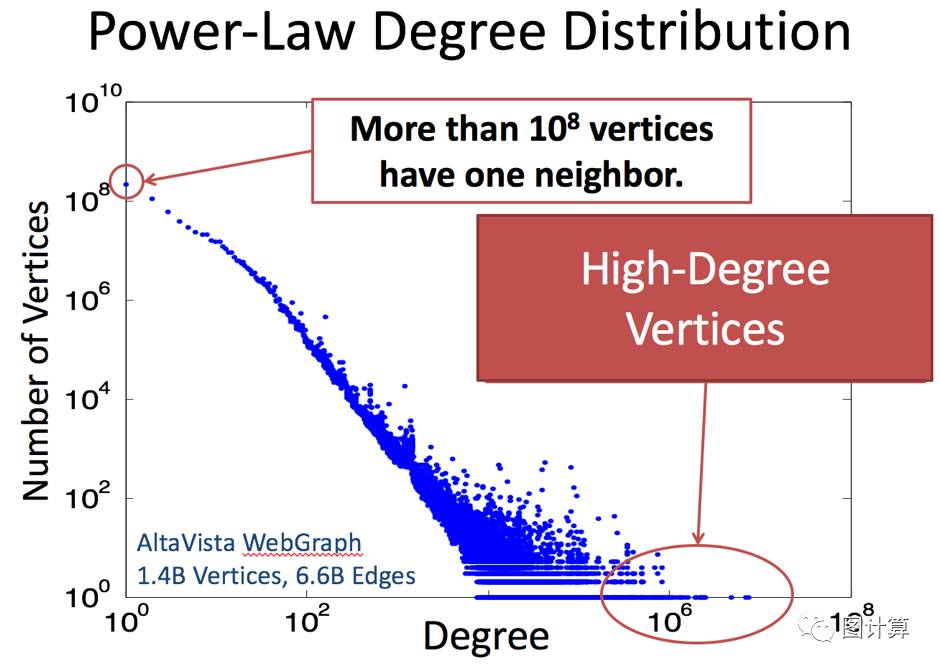
这种特性影响了图计算研究的很多方面,同时也带来了极大的挑战,而更详细完整的理论分析,将在讲解PowerGraph[4]时具体展开。
本文内容仅个人观点,如有错误和不足之处还望大家雅正,如果对您有所帮助则是我的荣幸!
[1] https://www.tuicool.com/articles/3MjURj.关于图计算和GraphX的一些思考. 淘宝技术部.
[2] http://www.csdn.net/article/1970-01-01/2825748 . 如何利用“图计算”实现大规模实时预测分析. 王绪刚
[3] FALOUTSOS, M., FALOUTSOS, P., ANDFALOUTSOS, C. On power-law relationships of the internet topology. In ACMSIGCOMM Computer Communication Review (1999), vol. 29, ACM, pp. 251–262.
[4] J. Gonzalez, Y. Low, H. Gu, D. Bickson,and C. Guestrin. PowerGraph: Distributed graph-parallel computation on naturalgraphs. In OSDI, 2012.
