前沿
Kubernetes Meetup 中国 2017——【上海站2.12】圆满结束,才云发布自研平台 TensorFlow as a Service(TaaS)v1.0.0 版本。
该版本包括支持 CPU 和 GPU 的分布式 TensorFlow 模型训练平台和 TensorFlow 模型托管平台。通过将 TensorFlow 与谷歌开源的容器云平台管理工具 Kubernetes 结合, Caicloud 提供的 TaaS 服务解决了 TensorFlow 在使用中学习成本高、管理难、监控难、上线难等问题,旨在帮助企业更快、更容易地体验和应用最新深度学习技术。
现场,参会人员对才云 TensorFlow 平台支持 GPU 表现出了强烈的兴趣。小编在这里为大家准备了一篇在 Kubernetes 上 DIY 裸机集群的教程帖,有兴趣的小伙伴可以点击原文查看具体步骤,自己动手进行搭建:)
GPU 应用领域
一开始,GPU 相关的应用仅仅停留在图形的相关应用,比如游戏中 3D 图形等图像处理应用。而现在,GPU 的应用已经非常广泛,在游戏、娱乐、科研、医疗、互联网等大规模计算的领域都有 GPU 的应用。比如高性能计算应用、机器学习应用、人工智能应用、自动驾驶应用、虚拟现实应用、自然语言处理应用等等。
Kubernetes 支持 GPU 调度功能
Kubernetes 支持 GPU 调度功能。众所周知,GPU 功能的强大之处,所以 IT 专业人士想要实现帮助创建支持 Kubernetes 的最佳 GPU 功能。
教程|在 Kubernetes 上 DIY 裸机集群
下文由 Samuel Cozannet(文末有具体简介) 撰写,是一篇实用的在裸机上安装GPU集群的教程帖,非常细致地描写了步骤中所需的各类组件(还附加亚马逊购物链接),有兴趣的读者可以先拿去练练手。由于文章原文图文内容较多,所以编者对代码部分进行了省略,想要手动进行部署的读者可以点击原文查看详情,建议在电脑端查看:)
在 Canonical,有很多下图中出现的橙色的盒子。

有的机器包括 10 个 Intel NUC,外加一个用于管理的 Intel NUC。它们作为演示工具,被用于一些大的软件堆栈,例如 OpenStack,Hadoop 等,当然还有 Kubernetes。
TranquiPC 免费提供以上这些服务,所以如果你是 R&D 团队的一员,或者对自己动手创建集群十分感兴趣,可以考虑看看这篇文章。
然而,除了他们的高品质,他们还缺乏一个深度学习技术咖们都喜欢的关键设备:GPU!
本文将阐述如何使用相似的架构来创建、安装以及配置 DIY GPU 集群。我们先从挑选硬件和实验开始着手,然后再讨论 MAAS(Metal as a Service),它是一个裸机管理系统。最终,我们还是决定查看 Juju 在 Ubuntu 上部署 Kubernetes,添加 CUDA 支持,并且在集群中启用。
硬件:将完全成熟的 GPU 添加到 NUC?
当面对一堆 GPU 和 NUC 的时候,会不知所措,因为不知道如何将普通的 GPU 嵌入小型 Intel NUC。但是,他们有一个 M.2 NGFF 端口。它本质上是一个 PCI-e 4x 端口,只是个不同形式的因素。
以及,这是将 M.2 转化为 PCI-e 4x,而that则将 PCI-e 4x 转化到了 16x。
所以,理论上来说,我们是能够将 GPU 连接到 NUC 的,我们来试试吧!
POC:第一个节点
我们先简单地从单个节点 Intel NUC 开始,来看看我们是否可以给它添加上 GPU 与之协同工作。
眼下(NUC5i7SYH),我们已经有一个 NUC,一个旧的 Radeon7870,我只要卖好以下东西即可:
启动 GPU 所需的 PSU:为了这个,我发现 Corsair AX1500i 是市面上性价比较高的选项,它最多可以启动10个GPU!这样我就可以启动更多的节点。
适配器
-M.2 to PCI-e 4x
-Riser 4x-> 16x
在不连接底板的情况下,连接启动PSU。
显示器,键盘和网线
太好了,它运行起来了!来自额外 GPU 的 Ubuntu 脚本以 4x 的速率在运行。在这一点上,我们证明要做的事情是可行的!是时候开始创建集群了。
物料单
对于每个 worker 来说,你需要:
Intel NUC6i5RYH 是性价比很高的选择,但是它没有 Intel AMT,所以你无法启动全自动运维。想要使用全自动重启来接近 Orange Box 的话,就需要购买 NUC5i5MYHE,这也是唯一引用 vPro 的地方(除了 board 本身)。
RAM:Corsair 32GB DDR4
SSD:500GB Sandisk Ultra II
Video Card:nVidia GTX1060 6GB
适配器:跟之前的一样,也是 4x
为了管理节点,需要两个上述 NUC,和一个更小的 SSD,但是不需要 GPU。
目前所需的组件:
PSU:Corsair AX 1500i
Switch Net gear GS108PE。
执行
如果它跟 box 不契合,那就删掉 box。所以首先,NUC 的主板必须要提取。使用 3mm 的 PVC 纸板和间隔器,我们就可以做一个很棒的布局。
GPU 角度

从 POC 的角度来看,我们跟 GPU 产生联系,这样电源连接器在底部就是可见的,PCI-e 端口只是上升掠过边缘。整个洞口大概 2.8mm 宽,这样 M3 垫片就可以通过,但是需要拧紧一些确保他们已经固定。
Intel NUC 角度

另一方面,我们从 SSD 和 Intel NUC 钻取固定孔,这样 PCI-e 吊索就跟 GPU 的 PCI-e 端口前面对齐了。同时,你也需要钻取 SSD 金属来固定支持。
就如同你在图片上看到的那样,我们将 PEC 和 NUC 之间的立管替换掉了,这样它看起来好一些。
我们对每个节点进行第四步操作。然后使用 50mm M3 hexa,我们在每个“叶片”中间用 3 个螺丝连接,将所有东西预定到网络。。。duang!
从 NUC 角度来看

从 GPU 角度看

软件:集群的安装
让集群富有生命会需要在软件方面做一些工作。
除了手册进程,我们需要利用一些强有力的工具。这就给予我们未来重复使用集群的能力。
管理metal自身的工具叫做 MAAS(Metal As A Service),是由 Canonical 开发,用于管理裸机服务器,而且已经启动 Ubuntu Orange Box。
然后进行部署,我们选择使用 Juju,Canonical 的模型工具,这也就意味着需要捆绑在一起来部署 Canonical 分布式 Kubernetes。
裸机规定:安装 MAAS
首先,我们需要在 Raspberry Pi2 上面安装 MAAS。
接下来,在你一切都准备就绪的前提下:
用 Ubuntu Server 16.04 安装 Raspberry Pi 2 或者 3
板载以太网端口连接到网络,然后进行配置
额外的 USB 连接到以太网桥适配器,连接到我们的集群切换机
网络设置
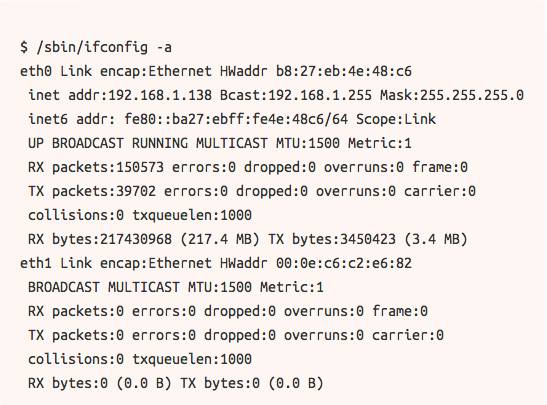
默认的 Ubuntu 镜像并不会自动安装 USB 适配器。首先,我们要查询 iconfig 来查看网桥1(也可以叫其它名字)添加到我们到网桥0接口:
我们不能用以下代码来编辑/etc/network/interfaces.d/eth1.cfg
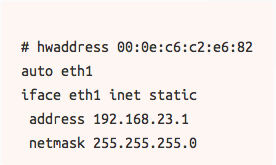
然后用以下代码来开启网桥1

现在我们就要进行二级接口设置
基础安装
我们接下来先来安装必需品:
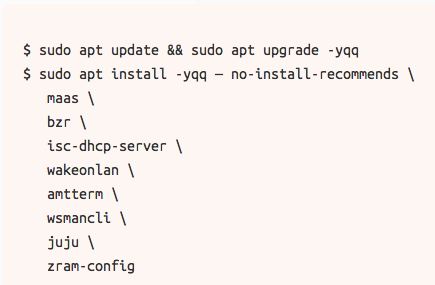
同样使用这个场景,我们来修复 Perl Locales bug,这个 bug 会对 Rapsberry Pi 有很大的影响:

DHCP 配置
MAAS 可以直接对 DHCP 进行处理,所以我们不需要特地对它进行处理。然而默认设置的安装方法简单粗暴,所以你可能需要稍微进行调整。以下是一个 etc/dhcp/dhcpd.conf 文件,可以运行得更加顺畅。
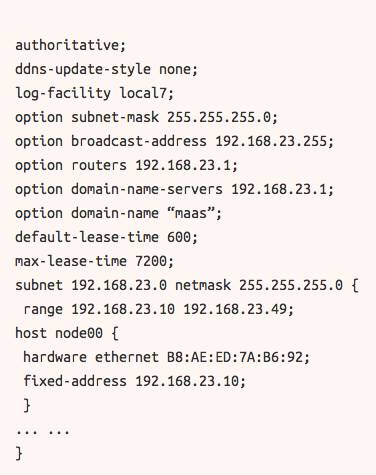
简单的路由器安装
在我们进行的设置中,Raspberry Pi 是网络内容的重点。MAAS 默认设置下虽然提供 DNS 和 DHCP,但是它并没有起到网关的作用。
所以我们先要在sysctl中启动IP转发:
安装 MAAS
必需品:

然后我们获取API key,从CLI登入:

运行以上命令之后,再运行下列命令:

用 Juju 进行部署
Bootstrapping环境
首先,我们需要做的就是将Juju连接到MAAS。我们为MAAS创建了一个配置文件作为提供商,maas-juju.yaml,使用以下代码行:
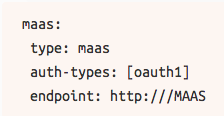
要知道,MaaS_IP,Juju与MAAS互相影响,包括已经部署好的节点。所以在我们的设置中,你可以使用网桥1(192.168.23.1)。
我们需要告知Juju如何使用MAAS:
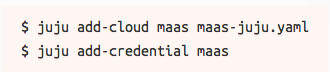
结论
现在来看看我们完成了什么。Kubernetes 真是容器管理系统中的多面手。它一定程度上也支持 TensorFolw 运行。
通过大规模添加 GPU,可以固定深度学习工作负载。以上 GPU 集群就是一个例子,很好地证明了,当一个 R&D 团队想要进行多节点的可伸缩性,总会做到的。
还有一个优点,大家可以注意到 K8S 的部署在这里是完全自动的(除了 GPU 以外),感谢 Juju 和 CDK 背后的团队。Juju 背后的社区创建了很多 charms,也有很多范围较大,大规模部署的应用程序,例如 Hadoop,Kafka,Spark 以及 Elasticsearch 等等。
最后,以上部署仅仅是作为 MaaS 以及一些命令行。Juju 在 R&D 里面的 ROI 还需要一些时日才能够完成。
由于文章原文图文内容较多,所以编者对代码部分进行了省略,想要手动进行部署的读者可以点击原文查看详情,建议在电脑端查看:)
作者简介:
Samuel Cozannet 是 Canonical 公司的战略项目经理。他热衷于探索 DevOps,坚信科技改变世界。只要一有时间,他不是在 Barcelona 晃悠,就是在乐此不疲地鼓捣新 Ubuntu 时髦设备。想要更了解他吗?复制打开网址:https://insights.ubuntu.com/author/samuel-cozannet/ 查看更多他的文章。
文章由才云科技编译,如若转载,必须注明转载自“才云 Caicloud”。查看原文请点击“阅读原文”。