




eygle对Oracle 18c、19c和20c十大新特性做了介绍,
https://www.eygle.com/archives/2019/10/oracle_database_20c_new_features.html
历史文章,
Oracle Database 20c的10大新特性一览
1. 原生的区块链支持 - Native Blockchain Tables
随着区块链技术的不断成熟和发展,Oracle在其多模的数据库支持中,引入了原生的区块链表支持。
在20c中数据库中可以通过blockchain关键字来创建区块链表:
CREATE Blockchain TABLE <blockchain_table_name>;

很多客户希望在不涉及多个组织的情况下利用区块链的防篡改和不可否认属性,区块链表使客户可以在需要高度防篡改的数据管理,而又无需在多个组织中分布分类帐或依靠分散的信任模型时使用Oracle数据库。
为了遵循区块链的可信和安全机制,区块链表只能INSERT记录,而不能修改,同时链可以被多方参与者验证。
区块链表,可以和其他常规表进行关联,进行事务处理或者查询。
2. 持久化内存存储支持 - Persistent Memory Store
自Oracle 19c开始,Oracle就已经开始修改程序以更好的配合持久化内存,提升数据库性能。
在20c中,Oracle明确支持了持久化内存 - Persistent Memory,虽然目前发布的信息是在Exadata中支持,但是软件的提升是通过的,在各类一体机中,或者是传统架构中使用持久化内存是毫无障碍的,

持久化内存的引入,让Oracle的存储多达6级:SATA、SAS、SSD、Flash、PMEM、RAM,冷热数据分离,分层存储,可以进行更加精细化的架构设计。整体架构提供小于19个微秒的IO延时。
在Oracle新发布的Exadata X8M一体机中,100Gb的以太网和RoCE获得支持,这是第一次在Oracle一体机中引入了基于RoCE的架构;
存储服务器上,通过PMEM在Flash之前进行加速,RoCE和PMEM提供了极速性能;
3. SQL的宏支持 - SQL Macro
宏的作用在于让SQL获得进一步的概括和抽象能力,允许开发者将复杂的处理逻辑通过宏进行定义,然后在后续程序处理中可以反复引用这一定义。
在20c中引入的SQL Macro支持两种宏类型,Scalar和Table类型。
SCALR表达式可以用于SELECT列表、WHERE/HAVING、GROUP BY/ORDER BY子句;
TABLE表达式可以用于FROM语句,

4. SQL新特性和函数扩展 - Extensions
在Oracle 20c中,关于SQL的函数扩展很多,包括对于ANSI 2011标准的部分支持,进一步的提升了SQL的处理能力。
在分析计算中,20c提供了两种新的分布聚类算法,偏态-SKEWNESS、峰度 - KURTOSIS,通过这两个算法,可以对给定数据进行更丰富的分布计算,新特性支持物化视图,遵循和方差(VARIANCE)相同的语义,

在20c中,Oracle还增加了CHECKSUM函数,用于检测数据的完整性,这个函数可以用于替代DBMS_SQLHASH.GETHASH函数,DBA不必再为此进行单独授权。
新的位运算符也被引入,20c中支持的新的位运算包括:BIT_AND_AGG、BIT_OR_AGG、BIT_XOR_AGG 。
对于分析函数,Oracle 20c扩展了窗口边界,通过GROUPS关键字可以进行特定分组数据的计数。
关键字GROUPS强调与分组查询的关系,使用GROUPS关键字,我们可以回答诸如,每个交易帐号执行"购买"的最后五个交易日中,花费的金额和以及 购买的不同股票代码的数量等。
5. 自动化的In-Memory 管理 - Self-Managing In-Memory
In-Memory技术引入之后,为Oracle数据库带来了基于内存的列式存储能力,支持OLTP和OLAP混合的计算。
在20c中,Oracle支持了自主的In-Memory管理,通过一个简单的初始化参数inmemory_automatic_level设置,DBA将不再需要人工指定将哪些数据表放置在内存中,数据库将自动判断需要将哪些对象加入或驱逐出In-Memory的列式存储中,

内存对象的管理,是通过数据库内置的机器学习算法自动实现的,并且数据库可以进一步的自动压缩较少访问的内存列数据。
inmemory_automatic_level = HIGH设置,可以用于指定高度的自动的内存管理级别。
6. 广泛的机器学习算法和AutoML支持
在Oracle 20c中,更多的机器学习算法被加入进来,实现了更广泛的机器学习算法支持。
极限梯度助推树 - eXtreme Gradient Boosting Trees(XGBoost)的数据库实现,以及各种算法,如分类(Classification)、回归(regression)、排行(ranking)、生存分析(survial analysitic)等;
MSET-SPRT支持传感器、物联网数据源的异常检测等,非线性、非参数异常检测ML技术,

此外,Oracle机器学习算法支持各种语言,例如OML4SQL、OML4Py、OML4R,其中AutoML针对Python提供了全面支持。
7. 多租户细粒度资源模型 - New Resource Modeling Scheme
在20c之前,多租户的数据库管理是服务驱动的,通过服务来决定PDB的资源放置,PDB的开启也是通过服务来进行隐式驱动的。
在集群环境中,这就存在一个问题,PDB可能被放置在某个资源紧张的服务器上,服务驱动的模型并不完善。
在20c中,Oracle引入了细粒度的资源模型,将负载和PDB的重要性等引入管理视角。例如,用户可以通过Cardinality和Rank定义,改变PDB的优先级,在数据库启动时,优先打开优先级别高的PDB,

除此之外,在PDB打开之前,数据库会检查主机运行负载、可用性、CPU数量和CPU速度等信息,以科学判定应该在什么节点以什么顺序启动PDB。
关于多租户的另外一个改变是:在20c中,Non-CDB模式将不再被支持(可以使用非多租户环境,但是没有官方支持),这将强制推动用户使用多租户特性。
在Oracle 19c的授权文件中,有这样的描述:你可以使用3个PDB的多租户环境而不需要License,超过3个PDB则需要额外的授权,
"For all offerings, if you are not licensed for Oracle Multitenant, then you may have up to 3 PDBs in a given container database at any time."
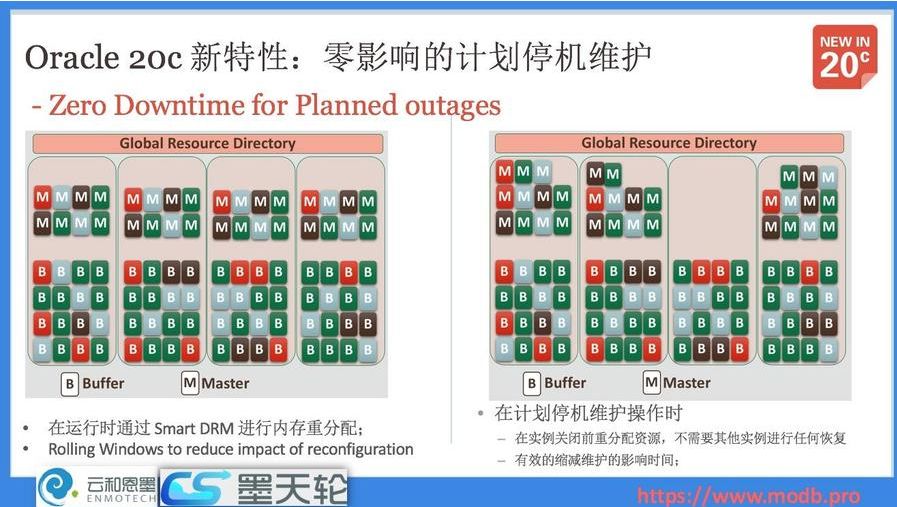
8. 零影响的计划停机维护 - Zero Downtime for Planned Outages
在Oracle不同版本的不断演进中,一直在加强数据库的可用性能力。在20c中,对于计划停机维护或者滚动升级等,Oracle通过Smart DRM等特性以实现对应用的零影响。
对于维护操作,数据库可以在实例关闭前进行动态的资源重分配,这一特性被称为Smart DRM,通过GRD的动态资源重组织,重新选出的Master节点不需要进行任何的恢复和维护,对于应用做到了完全无感知、无影响,
9. In-Memory的Spatial和Text支持
针对Oracle数据库内置的多模特性,地理信息-Spatial和全文检索-Text组件,在20c中,通过In-Memory的内存特性,获得了进一步的支持。
对于空间数据,Oracle在内存中为空间列增加空间摘要信息(仅限于内存中,无需外部存储),通过SIMD矢量快速过滤、替换R-Tree索引等手段,以加速空间数据查询检索,可以将查询速度提升10倍,
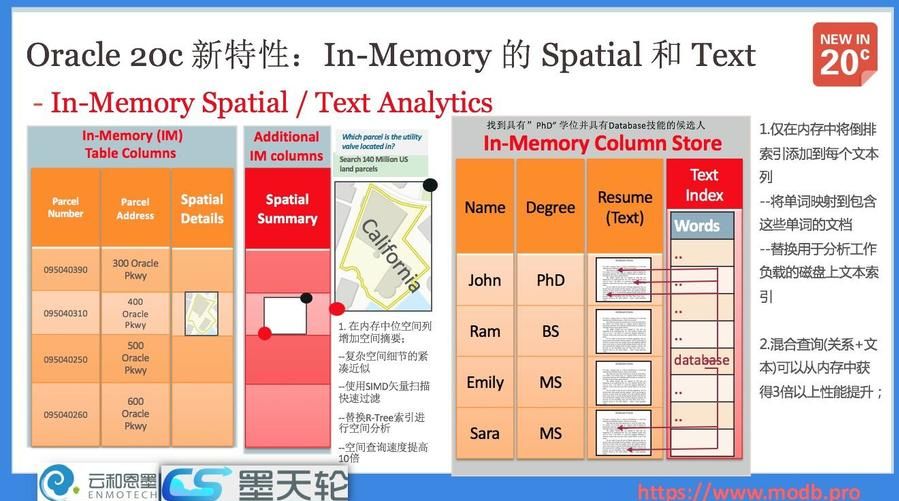
针对全文检索(Text,在内存中将倒排索引添加到每个文本列,同时通过将单词映射到包含单词的文档,以内存替换原来的磁盘索引,从而加速全文检索的性能。通过结合关系数据和文本的混合查询,全文检索可以获得3倍以上的性能提升。
10. 备库的Result Cache支持 - Standby Result Cache
在Oracle12.2和18c中,已经实现了ADG的会话连接保持和Buffer Cache保持,在20c中,Result Cache在备库上进一步得以保留,以确保这个细节特性的主备性能通过。
Result Cache特性是指,对于特定查询(例如结果集不变化的),将查询结果保留在内存中,对于反复查询(尤其是大规模聚合)的语句,其成本几乎降低为 0,

其实无论是18c、19c还是20c,还是要根据场景,选择合适的版本,合适的特性,适合自己的,才是最好。
