




read(file, tmp_buf, len);write(socket, tmp_buf, len);
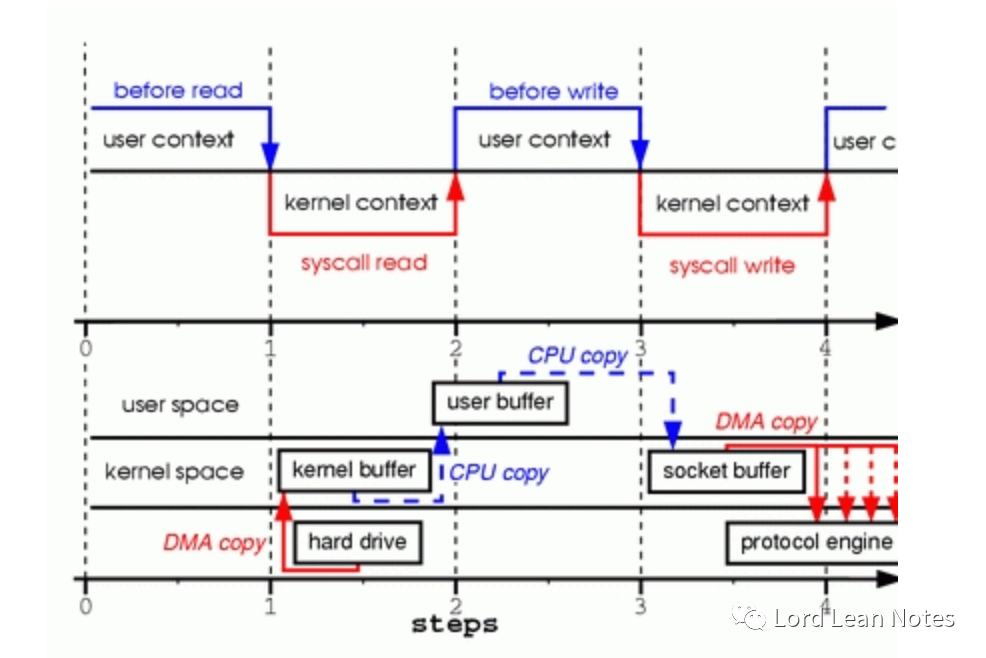
图1
read函数的调用导致线程从用户态切换到内核态,接下来由DMA引擎从磁盘中读取文件内容,并将其保存到内核态的缓冲区中。
数据从内核缓冲区复制用户缓冲区,read系统调用返回。这时又发生了一次上下文的切换和数据复制
write函数的调用导致再次从用户态切换到内核态,并将数据从用户缓冲区复制到专门与套接字关联的缓冲区
write函数的系统调用返回时,发生了上下文的第四次切换。这时DMA引擎将数据同步或者异步的的方式将数据复制到协议引擎
tmp_buf = mmap(file, len);write(socket, tmp_buf, len);
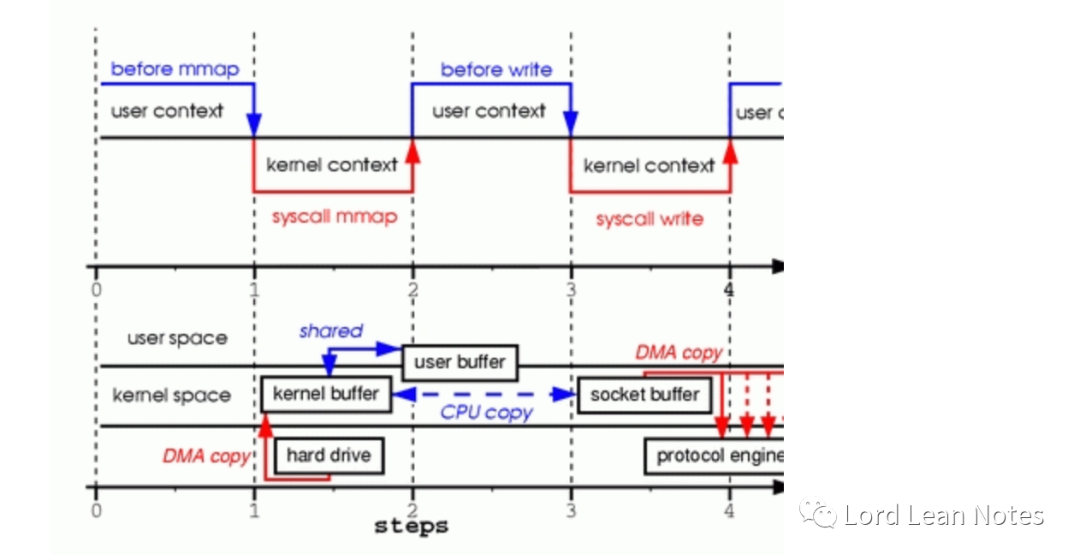
mmap函数的调用使文件从DMA引擎复制到内核缓冲区,而且该缓冲区与用户缓冲区共享,不会在内核态和用户态之间发生复制。
write函数的调用使内核将数据从内核缓冲区复制到与套接字关联的缓冲区
DMA引擎将数据复制到协议引擎时,发生第三次复制
sendfile(socket, file, len);
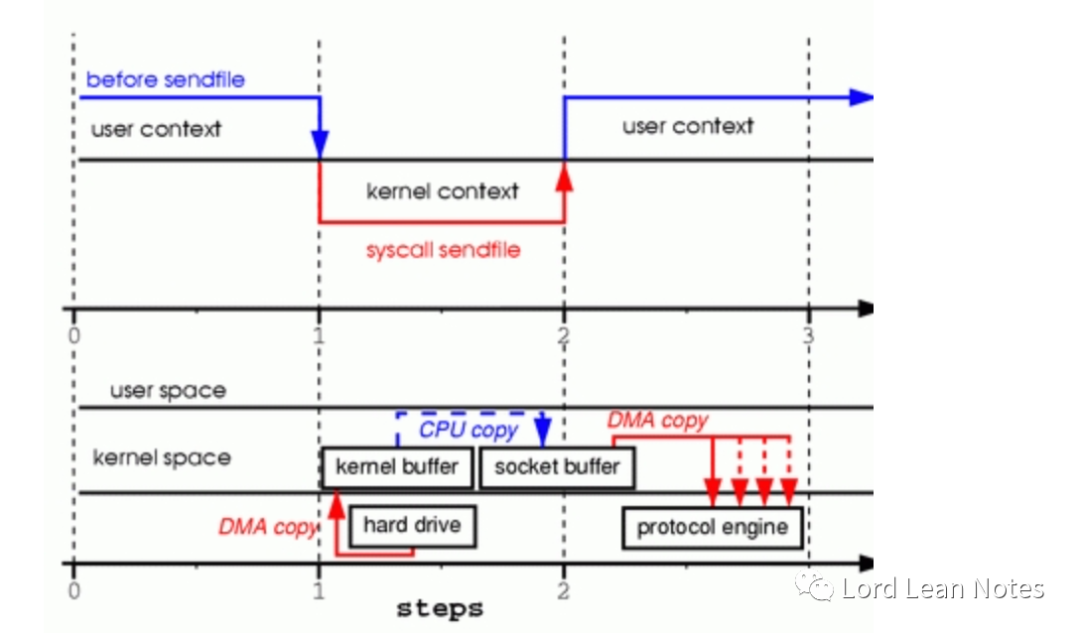
sendFile系统调用使文件内容被DMA引擎复制到内核缓冲区,然后内核将数据复制到与套接字相关的缓冲区
DMA引擎将数据从套接字缓冲区传递到协议引擎,发生第三次复制
sendfile(socket, file, len);
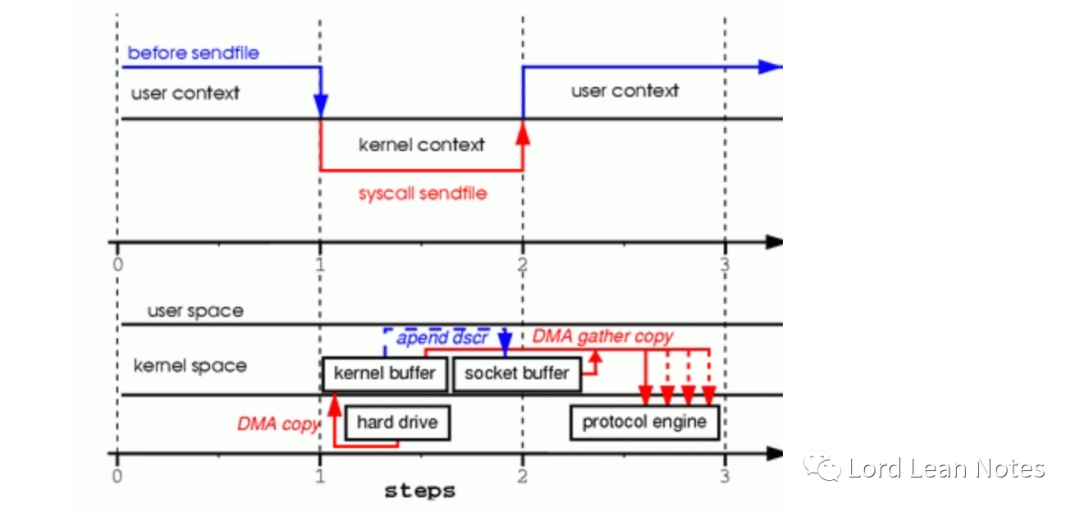
在图4中通过支持收集的硬件从多个内存位置搜集数据,消除了另一个副本。
sendFile系统调用使文件内容被DMA引擎复制到内核缓冲区 没有数据被复制到套接字缓冲区。只有具有有关数据的位置和长度的信息描述符才能附加到套接字缓冲区。DMA引擎将数据直接从内核缓冲区传递到协议引擎。
零拷贝中是将数据从磁盘复制到内存以及从内存复制到线路,但是从操作系统来看这确实是零拷贝,因为数据在缓冲区中并没有发生复制。零拷贝不仅避免了复制,同时减少了上下文切换、CPU的数据校验和计算以及CPU缓存数据的污染。
前段时间一起在讨论为什么Kafka的生产者发送消息时采用的是mmap的方式,而消费者消费消息时却采用的是sendFile的方式?
结合上面的资料,mmap天生适用于小数据传输,这是因为mmap在传输时如果传输的内容发生了修改,则会中断操作。虽说有方法可以解决,但是在生产者传输消息的这种场景下,文件是会经常被修改的,如果传输大的文件,则会经常发生中断的情况。而传输小的文件则尽量可以避免这种情况的发生。
在生产者写入消息的场景中,mmap特有的用户态和内核态共享的方式,可以使中间件做一些更多的事情。
消费者采用sendFile的方式,首先消息可以直接在网络中传输,而且这时消息已经固定,几乎不会发生变化,可以减去对数据的校验和计算的步骤,来提升数据传输性能。
