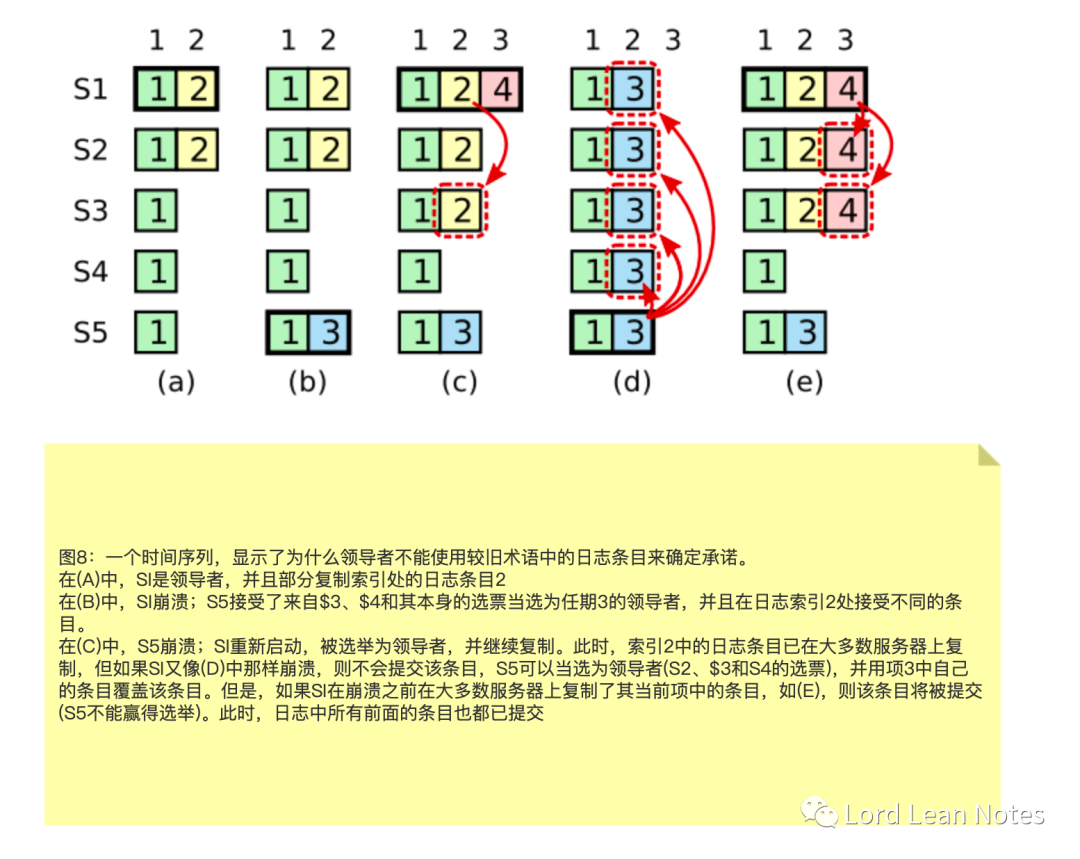
将日志记录复制到两个配置中的所有服务器
任何一种配置的服务器都可以作为领导者
关于选举和加入承诺的协议要求新旧组合的多数票分开
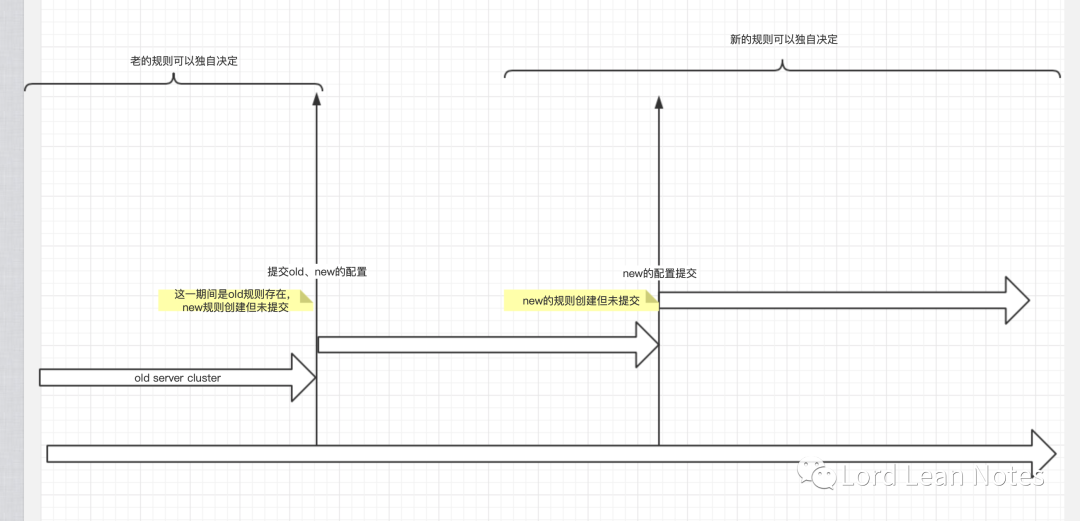
图2:新旧集群配置的更迭
文章转载自Lord Lean Notes,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





将日志记录复制到两个配置中的所有服务器
任何一种配置的服务器都可以作为领导者
关于选举和加入承诺的协议要求新旧组合的多数票分开
图2:新旧集群配置的更迭
