




区分风险等级是运维工作中十分重要的工作,老白年轻时候在各种场合参加过护航工作,什么奥运保障、C网割接、银行核心系统迁移、总理视察、新系统上线等等,基本上各种类型的护航都参加全了。护航的主要工作是定期看看系统是否正常,是否存在较大的风险。其实每个有经验的运维人员对自己所运维的系统软硬件平台都会有一个风险模型。当某些条件出现时,心里会有所警觉,通过查询一些指标、等待事件的情况,就能够确认该风险确实存在还是可以忽略。有时候某一现象出现并不一定意味着某种风险确实存在,但是持续几个现象的出现就大体上可以定位某个风险是否存在了。通过这样的一些分析,老白在这十多年的护航生涯中也确实帮助用户解决了一些系统问题,发挥了保障护航的作用。
如果依靠某个高水平的专家,这种风险分析确实还是比较靠谱的,不过对于普通的运维人员,风险分析还是十分困难的,当前系统的风险等级是高是低,其实很难一概而论。做过ORACLE DBA的一些资深人士一般都会通过V$SESSION视图中的等待事件来确定风险等级,通过一些运维经验的积累,可以固化系统正常状态的等待事件,当出现一些非正常等待事件的时候,就会提出预警,并通过一些辅助分析去进行分析确认。IT健康管理中的风险等级预警也是通过类似的手段实现的。当然对于不同的系统软硬件平台,其风险等级评定的模型是不同的,甚至在不同的应用系统上,这些模型都存在个性化调整的可能。
D-SMART初期的风险等级还是不够完善的,需要根据一些其他的指标来综合评定,比如健康模型、性能模型、负载模型。通过健康模型、性能模型、负载模型与风险等级评估综合分析,再辅助以运维经验分析工具,就可以进行故障预警与问题溯源了。
下面这个案例是2019年9月份的真实案例。是一个某系统因为应用BUG导致的行锁冲突及时消缺的典型案例。由于应用软件BUG导致某会话持有某个行锁不释放。导致大量会话因为等待行锁而被阻塞。如果该问题不能及时得到处置,则很可能出现大规模会话阻塞,甚至导致数据库会话达到参数极限,引起严重的系统故障。由于健康管理工具及时报警,现场人员快速定位,找到了未释放行锁的会话,及时杀掉该会话,恢复系统运行。故障处置完成时,业务部门还未感知。
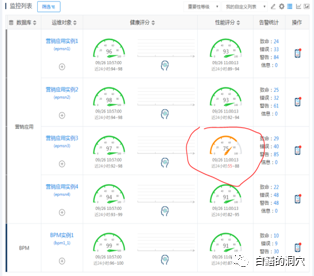
运维人员发现系统的性能模型丢分十分严重,于是立即查看风险等级评估工具的结果,获得的评估结果是风险等级“高”,同时,从等待事件上看,系统中存在大量的行锁。
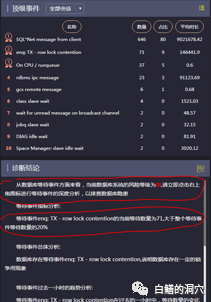
于是根据系统提示的诊断路径,通过blocking_session工具发现了阻塞者。
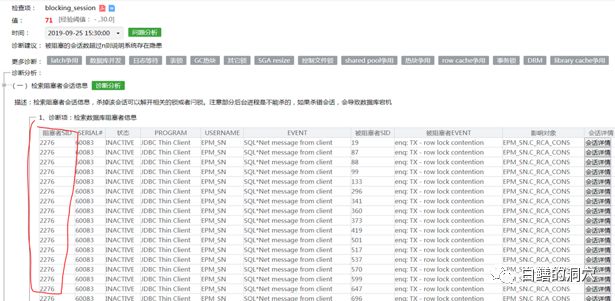
点击会话详情工具,可以查看到该会话的情况,以及执行的SQL语句,定位了引起问题的原因:
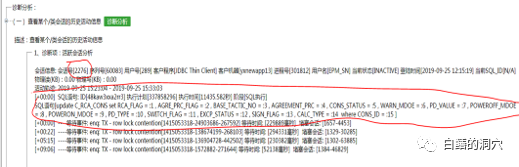
通过会话详情,运维人员可以明确该会话可以杀掉,于是第一时间杀掉了该会话(杀掉会话的语句脚本在工具中给出了提示,运维人员只需要拷贝该语句去执行就可以)。
目前这一系列的动作还是手工执行的,随着风险模型与处置工具的完善,以及企业运维管理流程的优化,这些工作完全是可以自动化的。其实目前完成自动处置的壁垒不是技术,而是管理。

关注老白,关注基石数据
