




(本文仅供学习交流使用,不做商业用途)
序
最近看了一些分布式相关的算法,由于Raft的资料比较多,所以感觉理解起来就容易了许多。看到有一些资料还不错,我就当了一回搬运工,翻译了一下。各位随便看看,欢迎留言交流~
什么是Raft
(以下翻译自https://raft.github.io/)
Raft是一种设计得易于理解的共识算法。它在容错和性能上等同于Paxos。不同之处在于它将实际系统分解成了相对独立的子问题,并且它清晰地表述了其中的主要部分。我们希望Raft能帮更多受众了解共识consensus,并且这部分受众能够开发出更加高质量的基于共识consensus-based的算法。
什么是共识consensus
共识是容错的分布式系统中的一个基本问题。共识涉及到多个服务器就某个值达成一致。一旦它们就某个值做出了决定,这个决定就是最终决定。
典型的共识算法是:当大多数服务器可用时,它就能工作。举个例子,包含5台服务器的集群即使2台挂了也可以继续运行。如果更多的服务器挂了的话它们就没法继续工作了(但是绝对不会返回错误的结果)。
共识通常出现在复制状态机的背景下,这是一种构建容错系统的通用方法。
每个服务器都有一个状态机和一个日志。状态机是我们想使其容错的组件,比如说哈希表。在客户端看来,它在与一个可靠的状态机交互,即便集群中的少部分节点挂了。每个状态机都从它的日志中读取命令。
在哈希表的例子中,日志会包含类似这样的命令“将x设为3”。共识算法就是用来就服务器的日志达成一致的。共识算法必须确保是否所有的状态机都将第n个命令应用为“将x设为3”,没有其他的状态机应用不同的n号命令。结果每个状态机处理的都是相同序列的命令,由此也会产生一系列相同的结果并最终达到一系列相同的状态。
举个🌰
假设有一个单节点系统。这里假设是一个只储存一个值x的数据库服务器。

与此同时有一个客户端可以将一个值发送给服务器。

一个节点的情况下很容易就这一个值达成共识。

但是如果有多个节点的话,怎么达成共识呢?
这就是“分布式共识“问题。
Raft就是一种是用来实现分布式共识的协议。
首先我们来看一看它的工作原理。
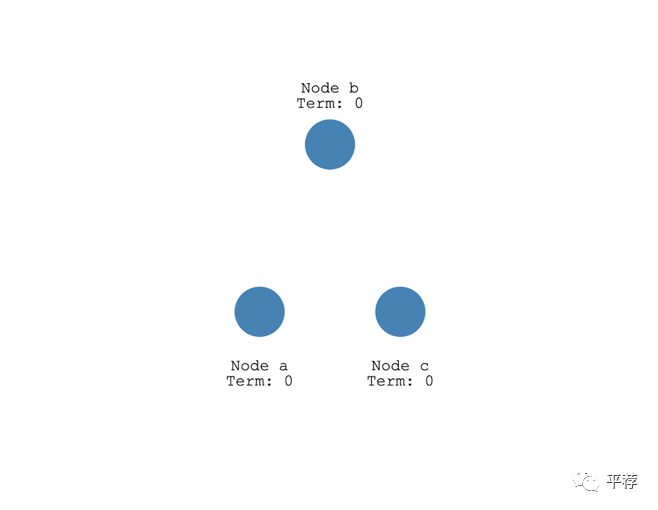
一个节点可以处于以下三种状态之一:
跟随者Follower、候选人Candidate、领导者Leader
所有节点的初始状态都是跟随者。
如果一个跟随者没有收到领导者的信息,它就可以变成候选人。
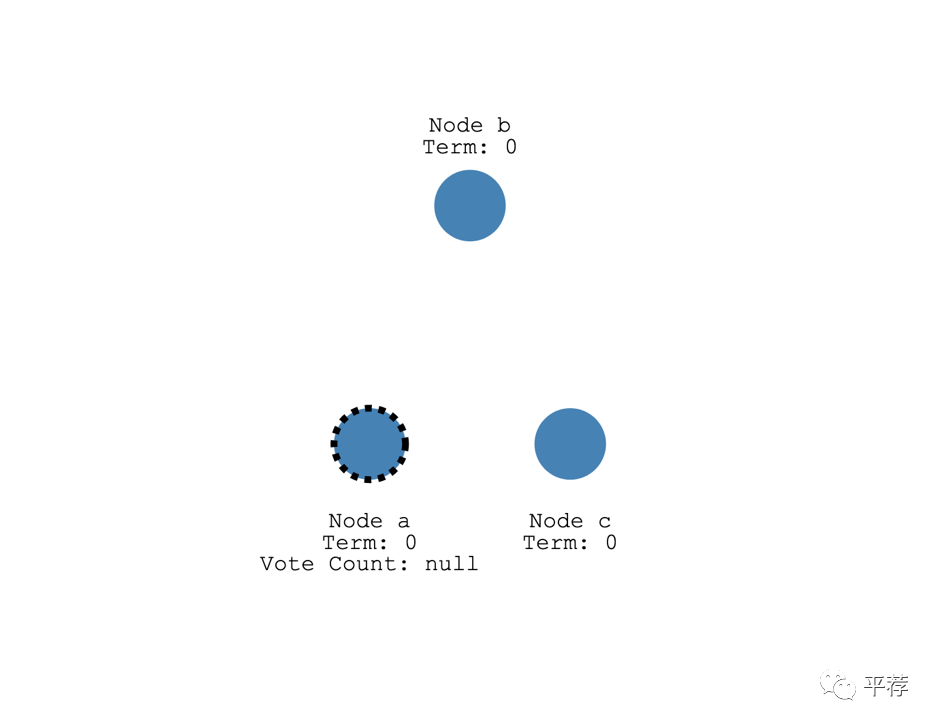
然后候选人就会从其他节点处请求投票。
其他节点就会投票表决。
如果候选人收到了大多数节点的选票,他将成为领导者。
这个过程叫做领导者选举Leader Election。
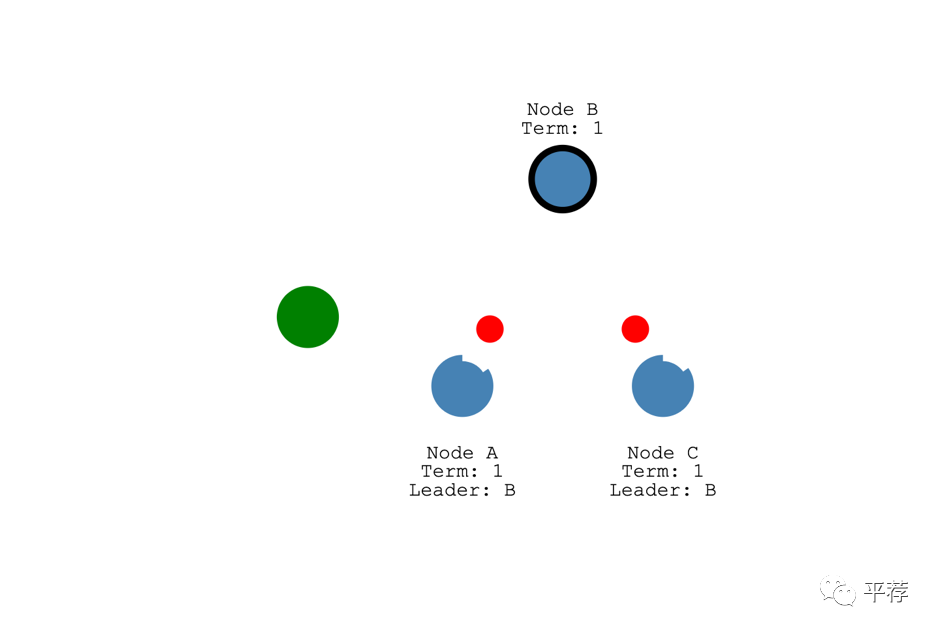
对系统的所有更改都要经过领导者。
每次改变都会被添加为一个节点日志中的条目。
下图这个日志条目还没提交,因此该节点的值不会更新。
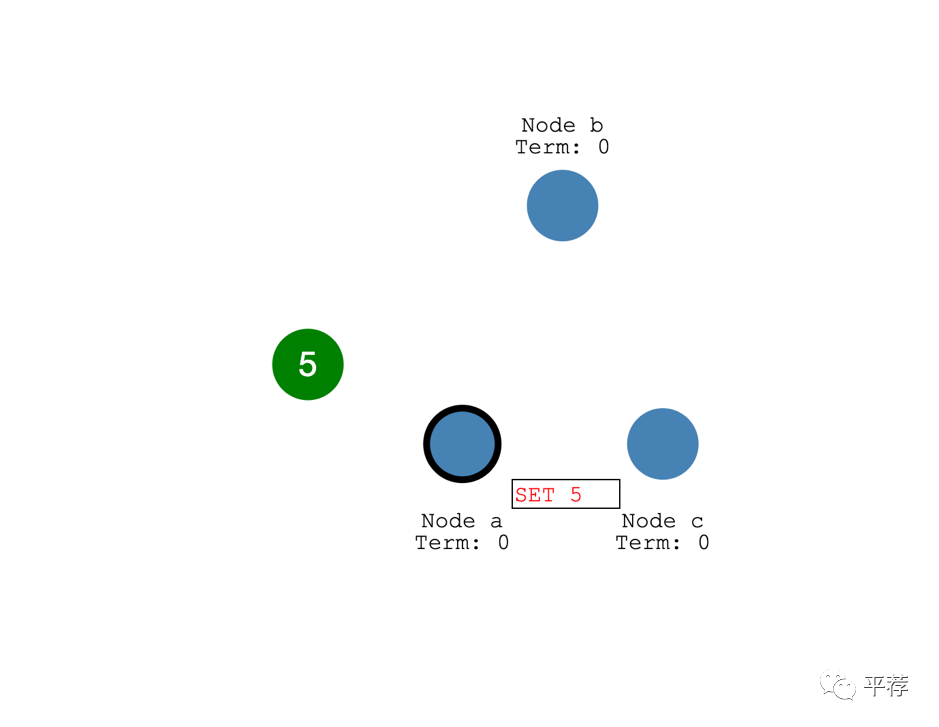
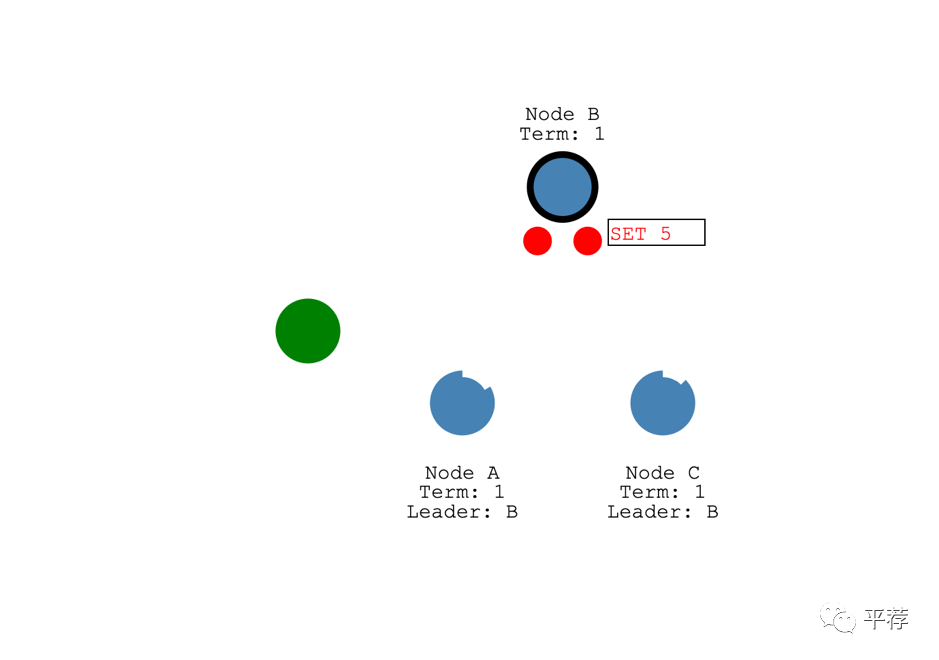
为了提交这个日志条目,这个节点需要先将其复制到其他跟随者节点。
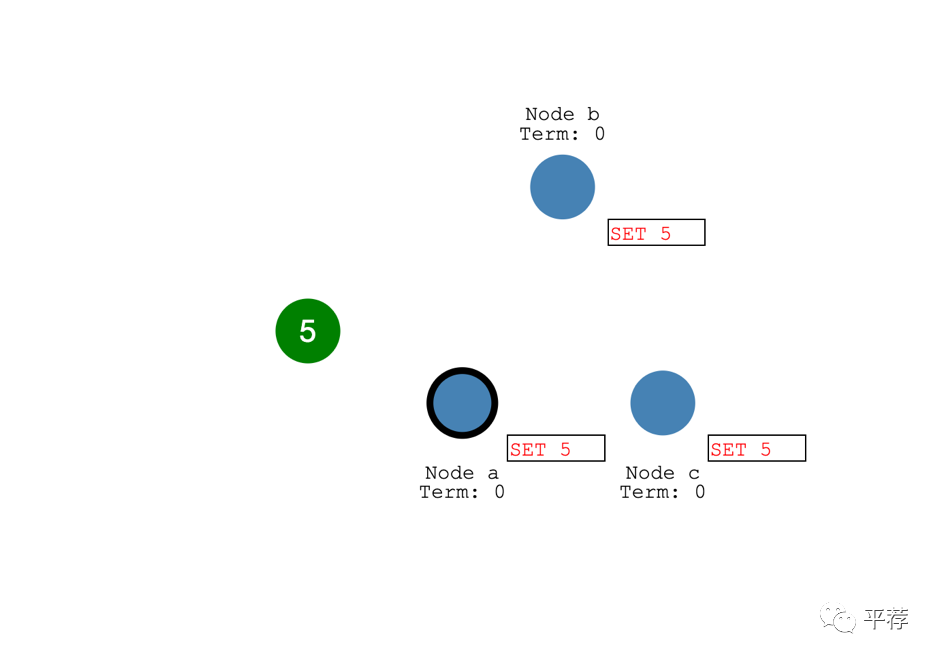
然后领导者会一直等着,直到大多数节点都将这个日志条目写入。
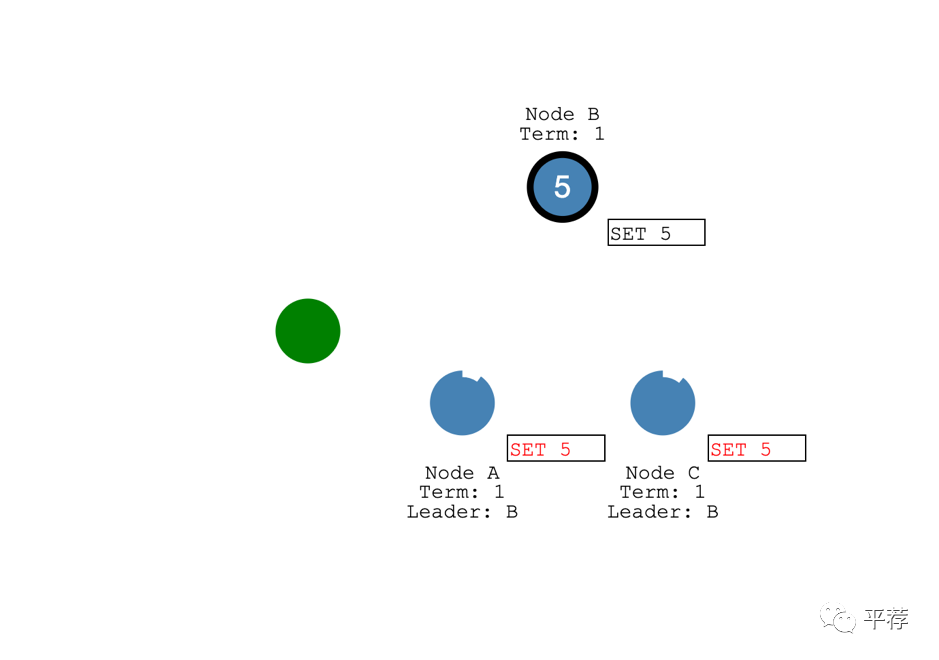
之后领导者节点提交这个日志条目。节点的值变成5。
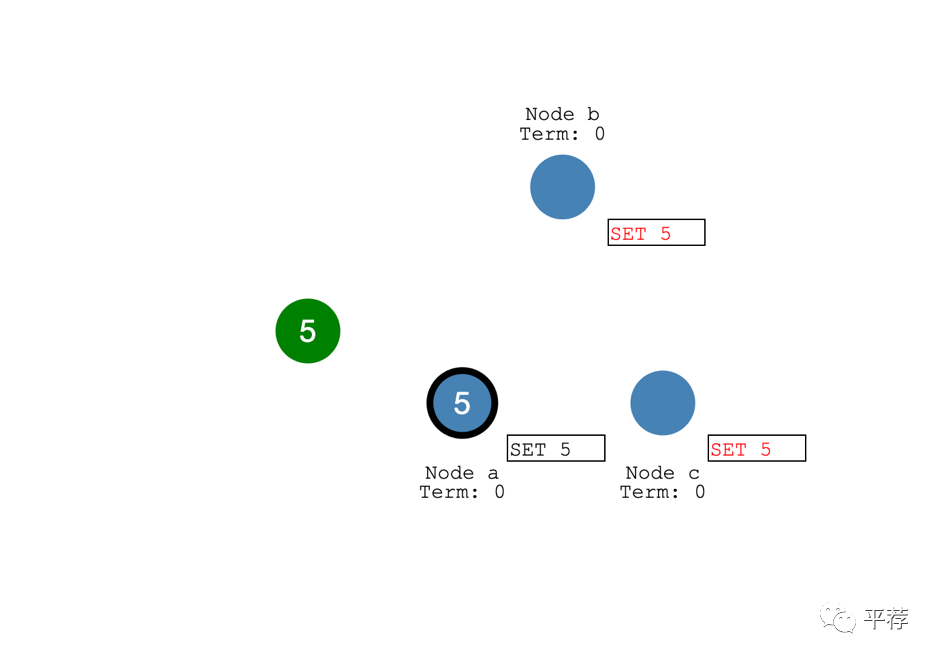
然后领导者通知跟随者该日志条目已提交。
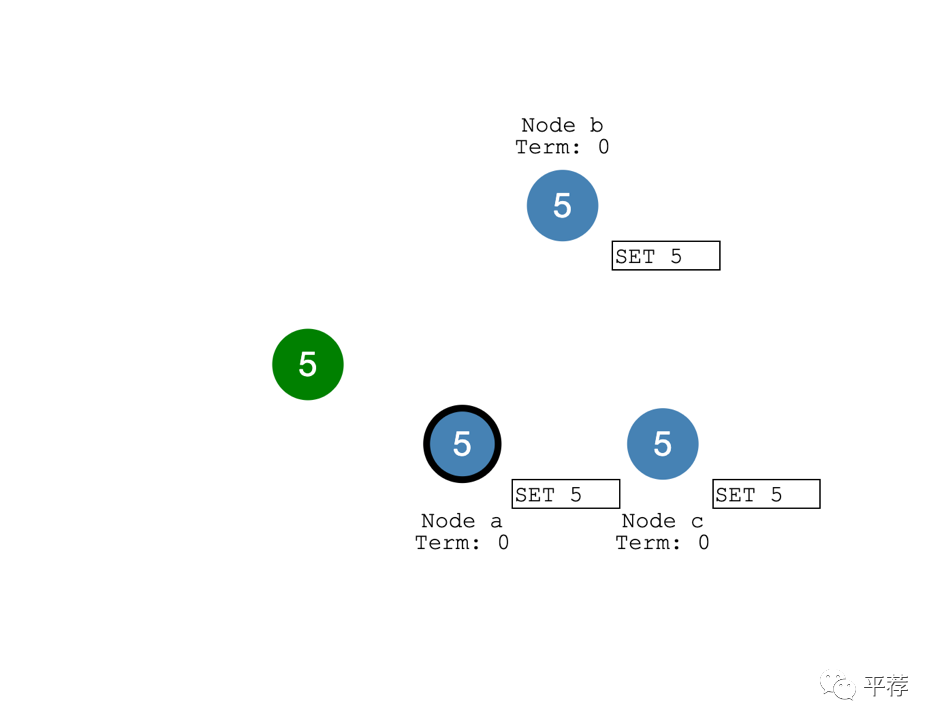
集群目前就系统状态达成了共识consensus。
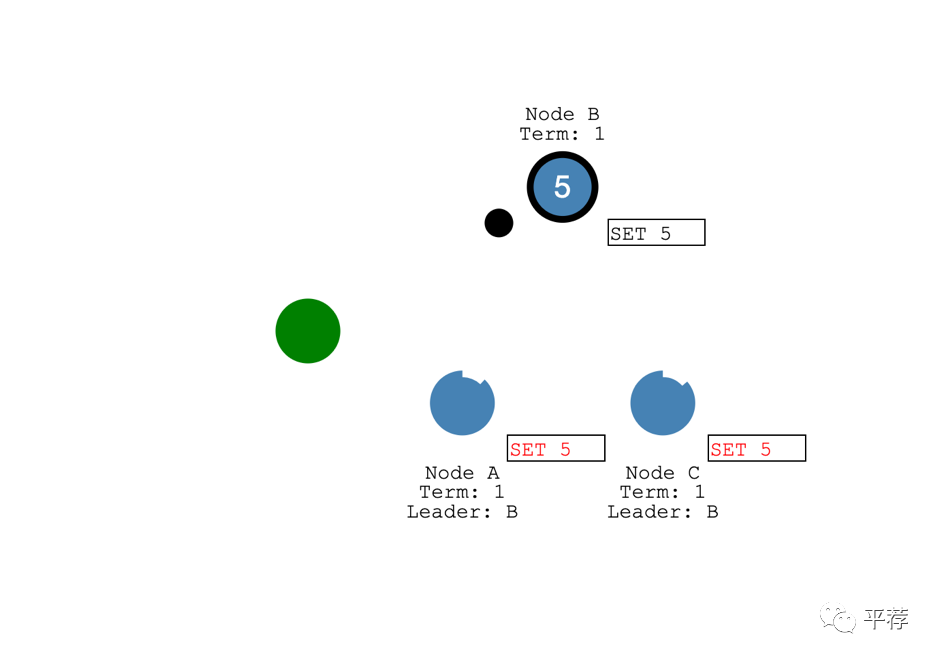
这个过程叫做日志复制Log Replication。
领导者选举的一些细节
Raft中有两种控制选举的超时设置。
第一种是选举超时election timeout.
选举超时是指跟随者在成为候选人之前等待的时间。
这是个随机数。一般在150ms~300ms之间。
选举超时之后某个跟随者就会成为候选人,然后开始一轮新的选举任期election term。
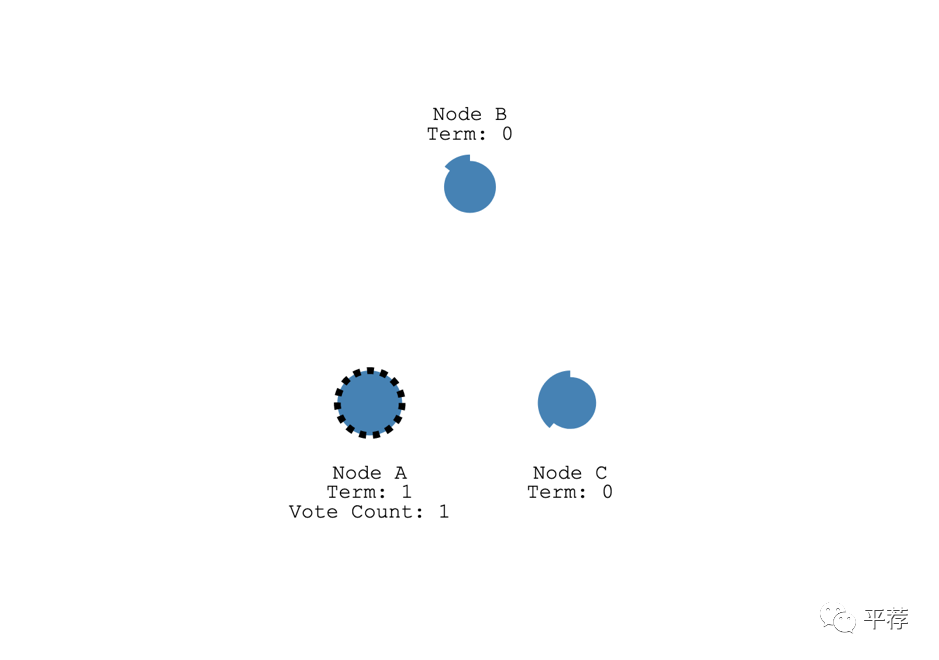
候选人先为自己投票,然后将请求投票的消息发送给其他的节点。
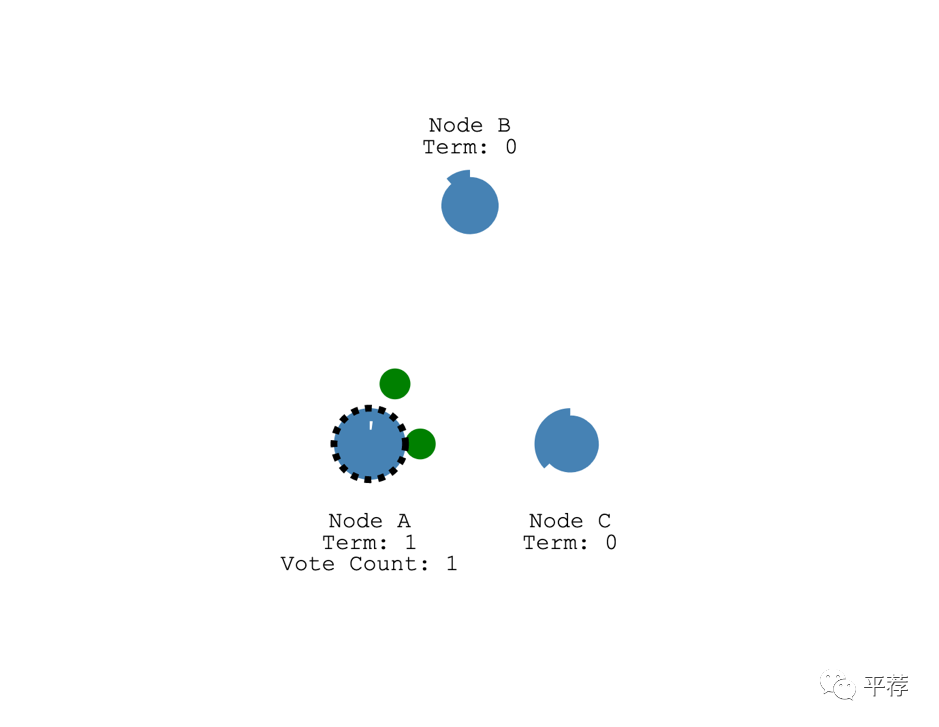
如果接收信息的节点在这一轮任期内还没投票,它就会投票给候选人并重置自己的选举超时。
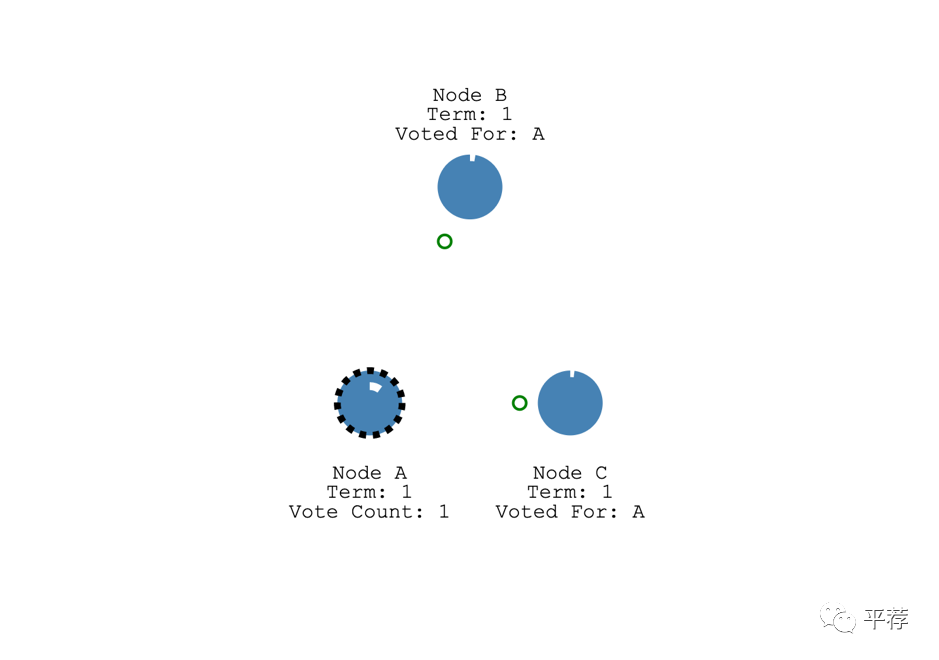
一旦候选人获得了大多数选票,它就成为了领导者。
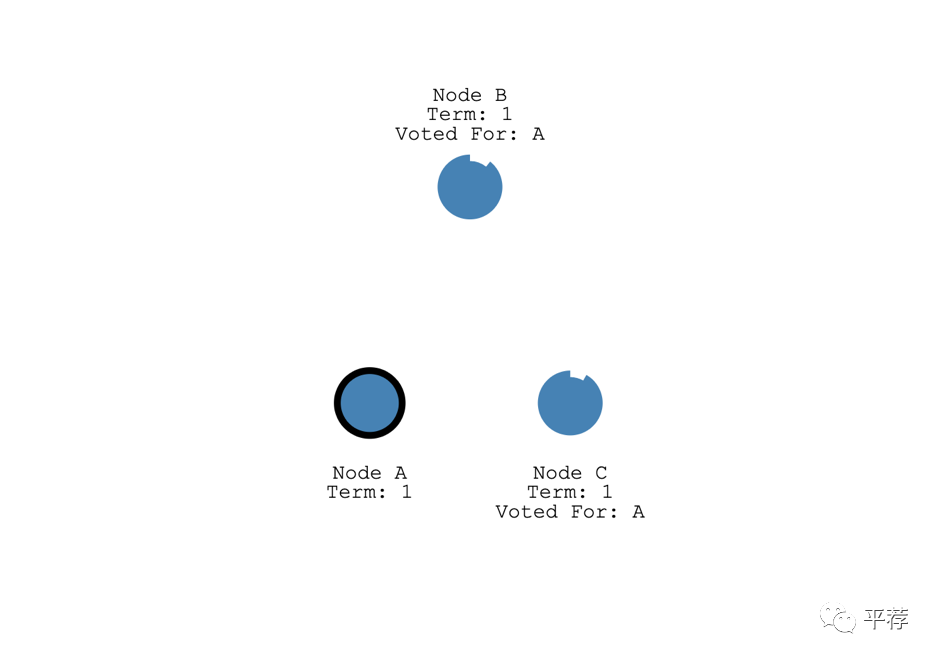
领导者随后发送“日志复制”Append Entries的信息给他的跟随者们。这些信息以心跳超时Heart Timeout的时间间隔发送。
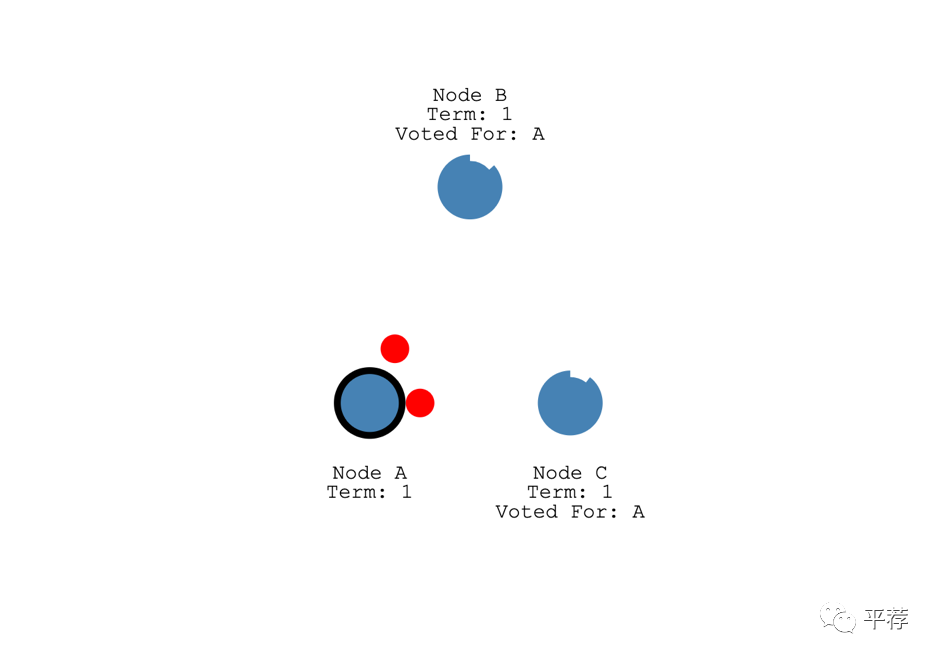
跟随者随后会响应每条“日志复制”Append Entries信息。
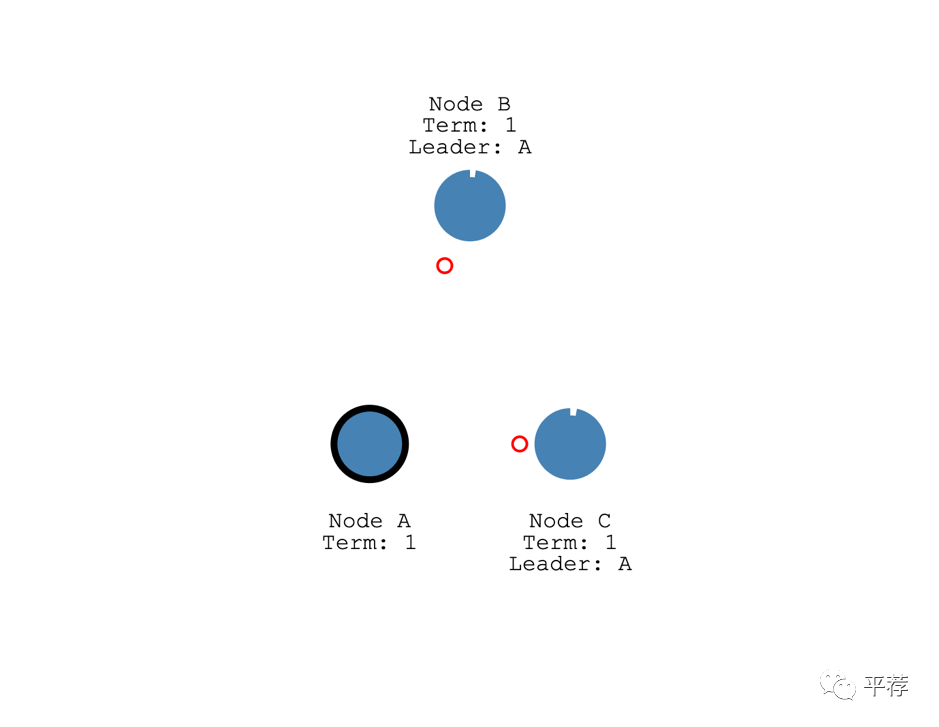
这一轮选举任期会一直持续到跟随者停止接收心跳并成为候选人为止。
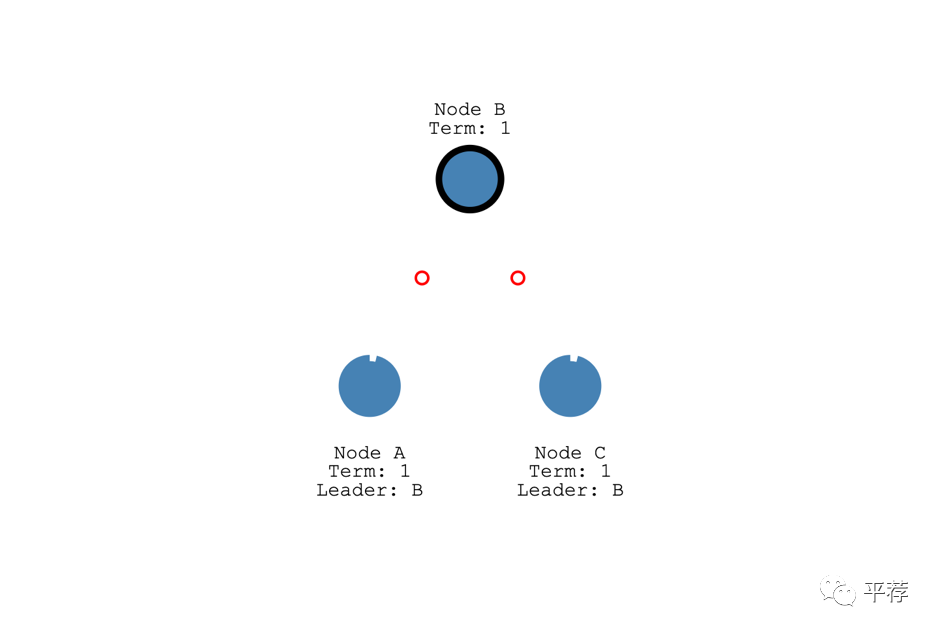
比如说领导者挂了。
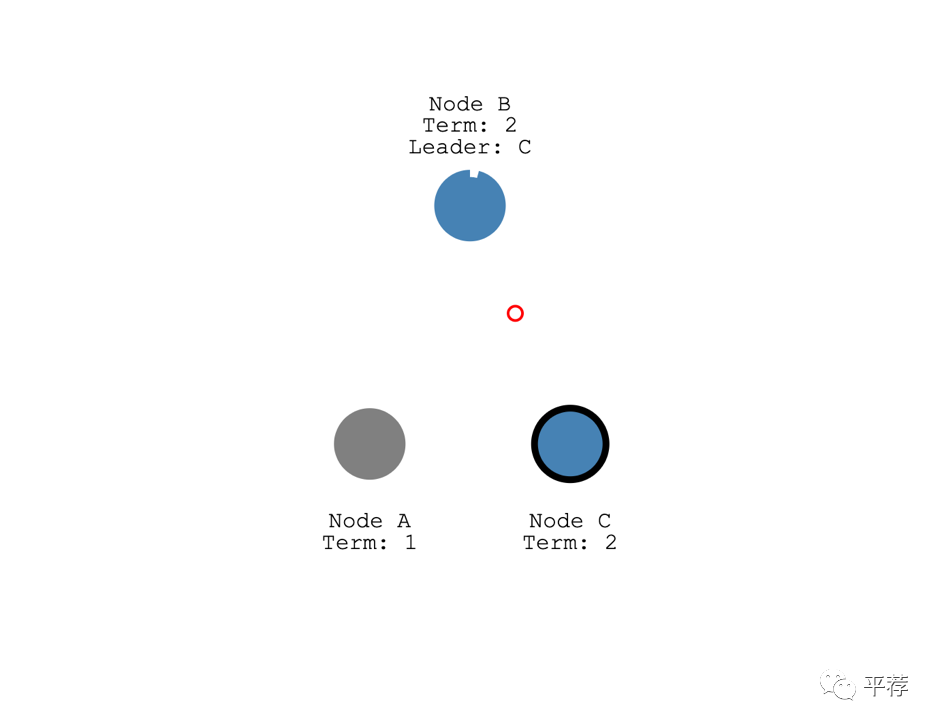
然后第二任选举任期中节点C成为了领导者。
“要求获得大多数选票”保证了每一届只能选举一个领导者。
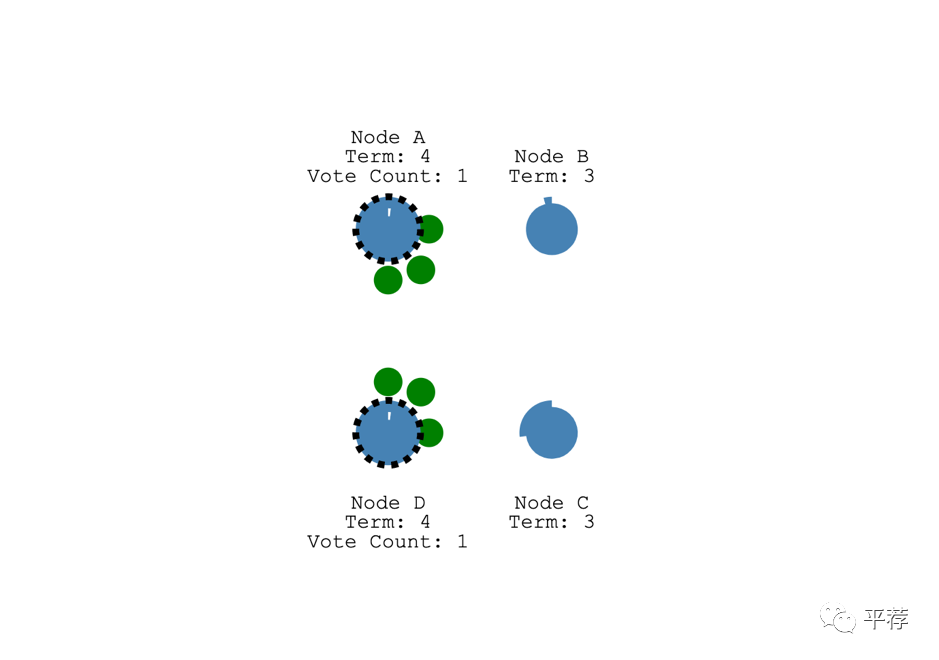
如果两个节点同时成为了候选人,那么就会发生拆分表决split vote。
举个例子。
两个节点为同一个任期同时开始选举并且每一个节点都先于另一个到达一个跟随者节点。这样每个候选人都有两票并且这一轮不会再收到更多选票了。
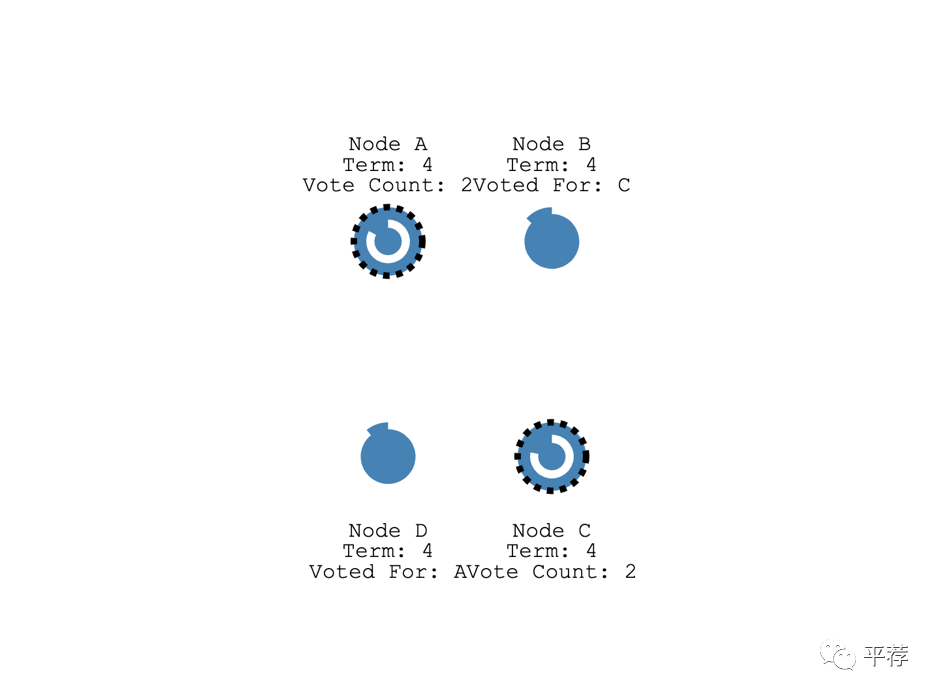
那么他们就会发起新一轮选举。
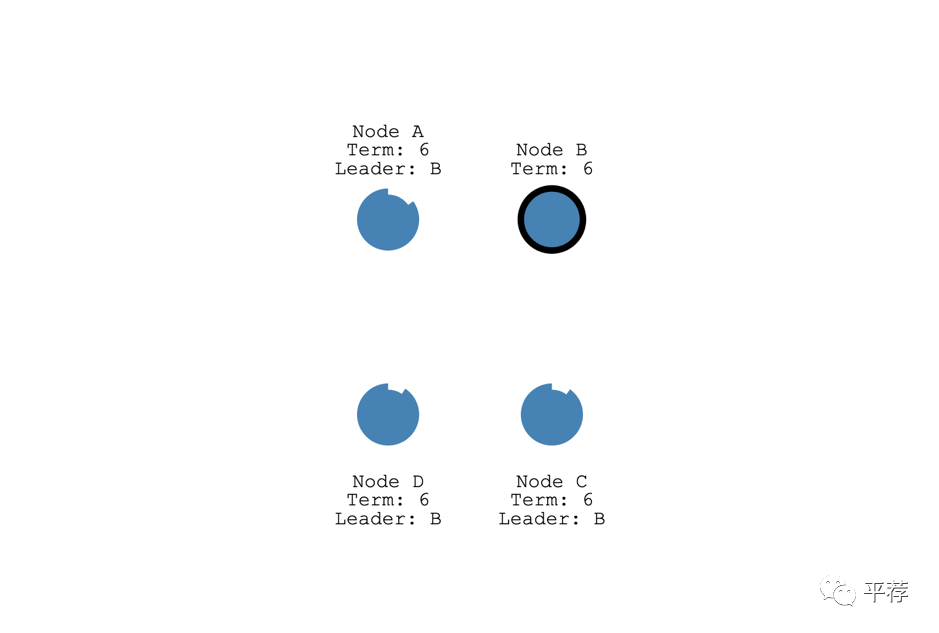
节点B收到了大多数选票,所以它成为了领导者。
日志复制的一些细节
一旦选出了一位领导者,就需要将系统的所有变更复制到所有的节点。这可以通过使用与心跳相同的“日志复制” Append Entries信息来完成。
举个例子。
首先客户端将变更发送给领导者。这个变更会添加到领导者的日志中,并在下一次心跳时发送给跟随者。
一旦大多数跟随者承认了它,这个日志条目就会被提交,并将响应发送给客户端。
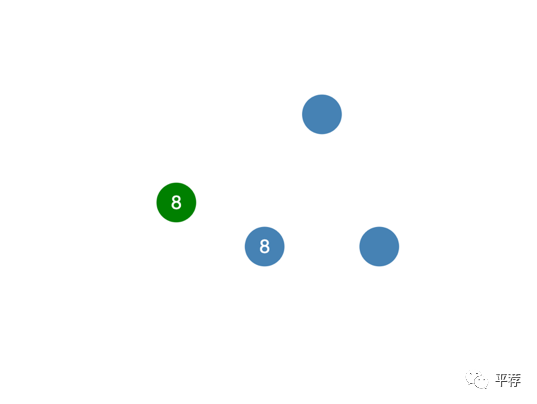
打比方说我们发送了一个命令“将值增加2”,系统就会更新为7。
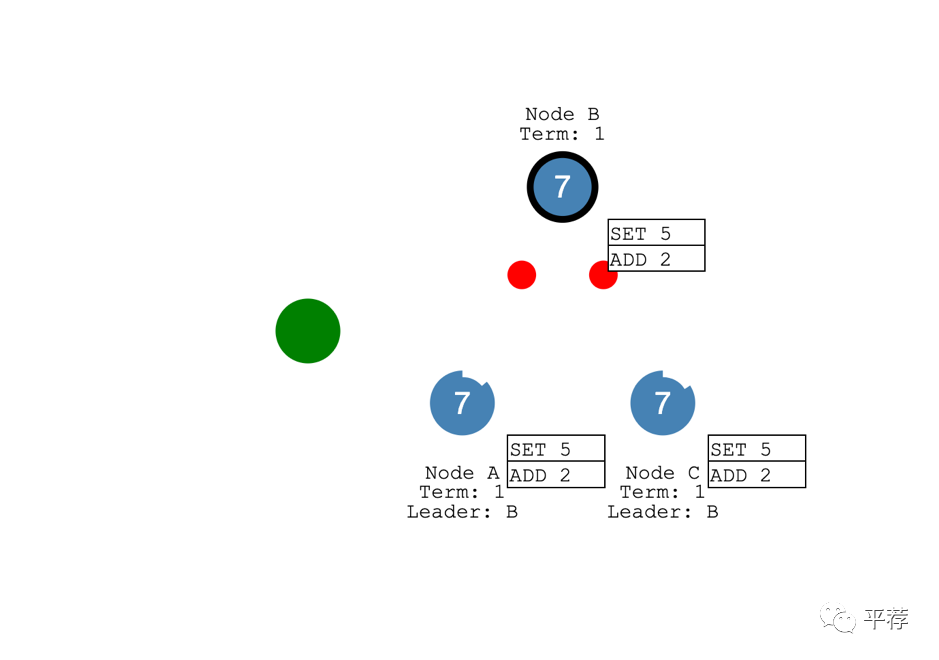
面对网络分区时Raft也能保持一致。
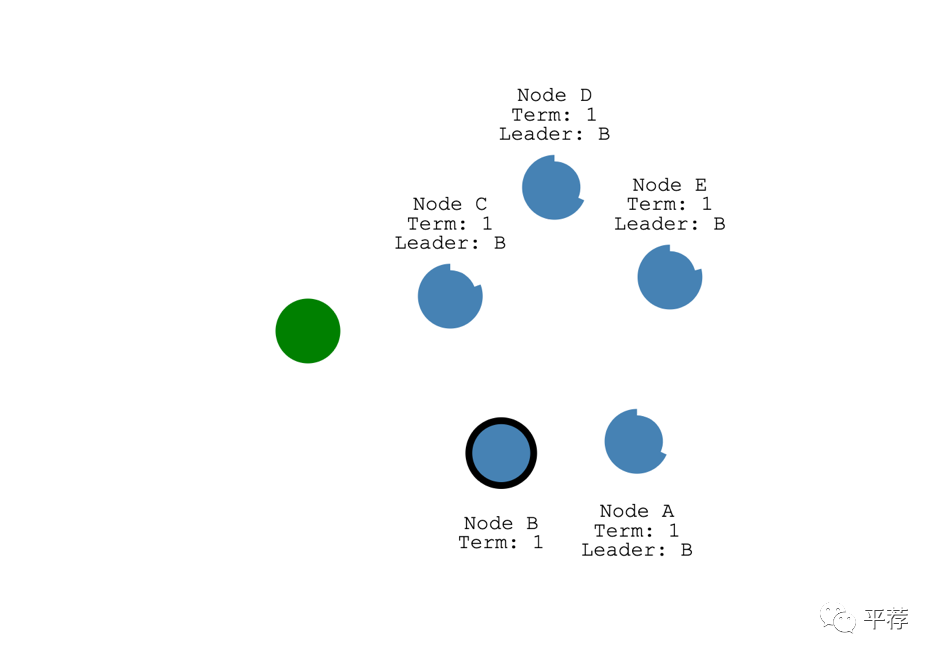
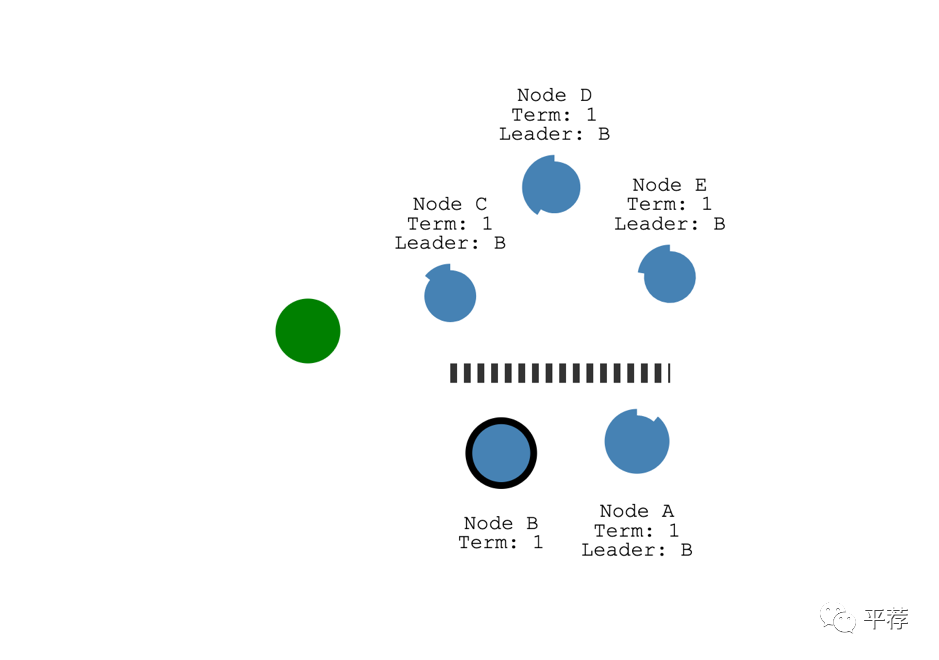
比如说我们添加一个分区将AB和CDE分开。由于分区的缘故,现在在不同的任期有了两个领导者。
假设添加了另一个客户端,并尝试更新这两个领导者。一个客户端想将节点B的值设为3。节点B无法将日志条目复制给大多数节点,所以它的日志条目一直处于未提交状态。
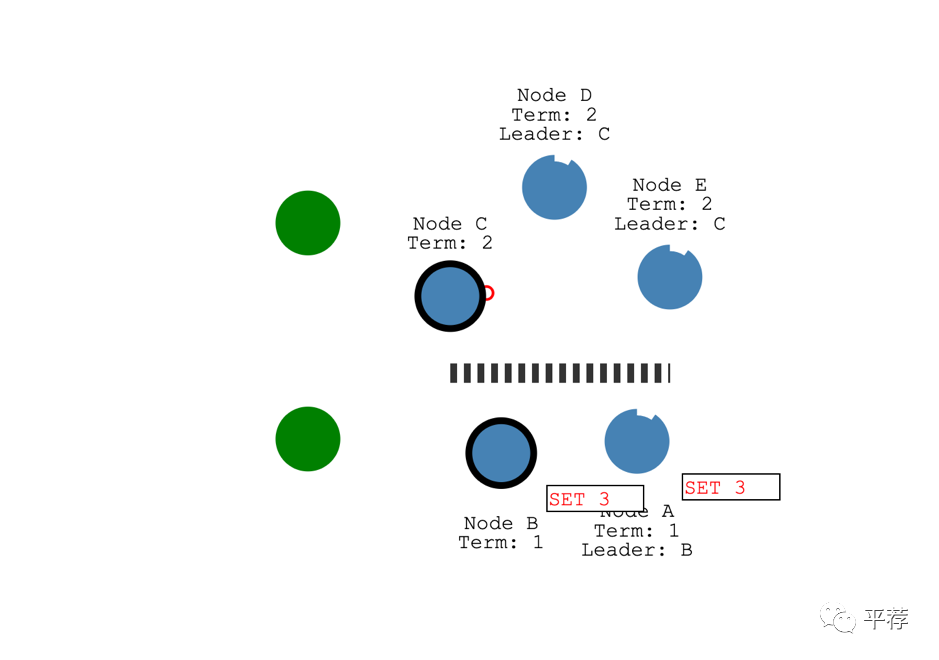
另一个客户端尝试将节点C的值设为8。这是可以做到的,因为它可以复制给大多数节点。
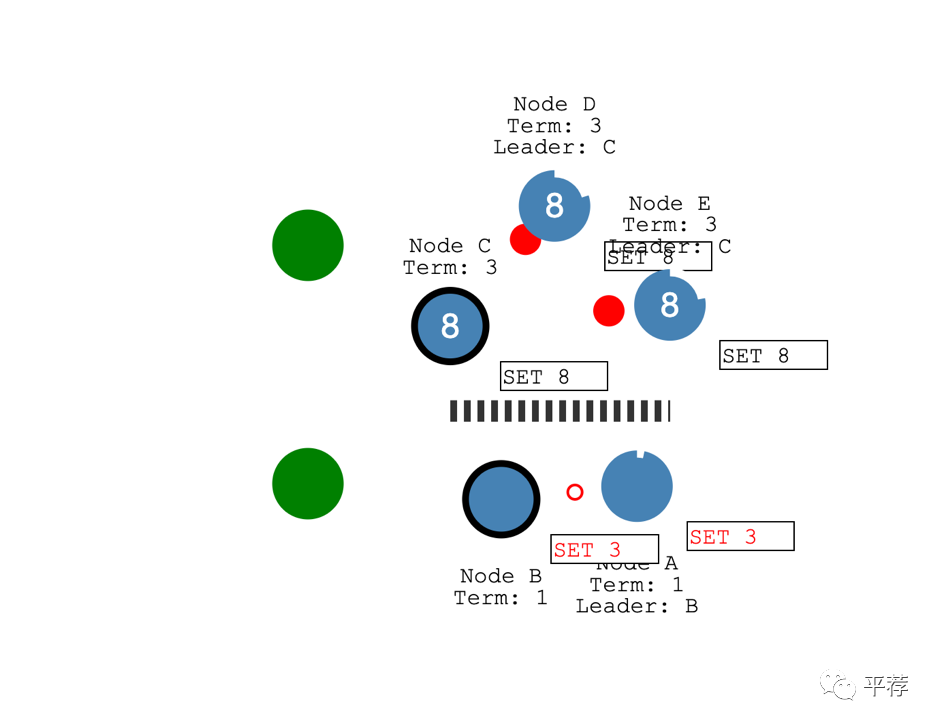
不久之后分区修复了。
节点发现了一个更高的选举期限,它就退出了。节点A和B都将回滚它们未提交的日志条目并匹配领导者的日志。
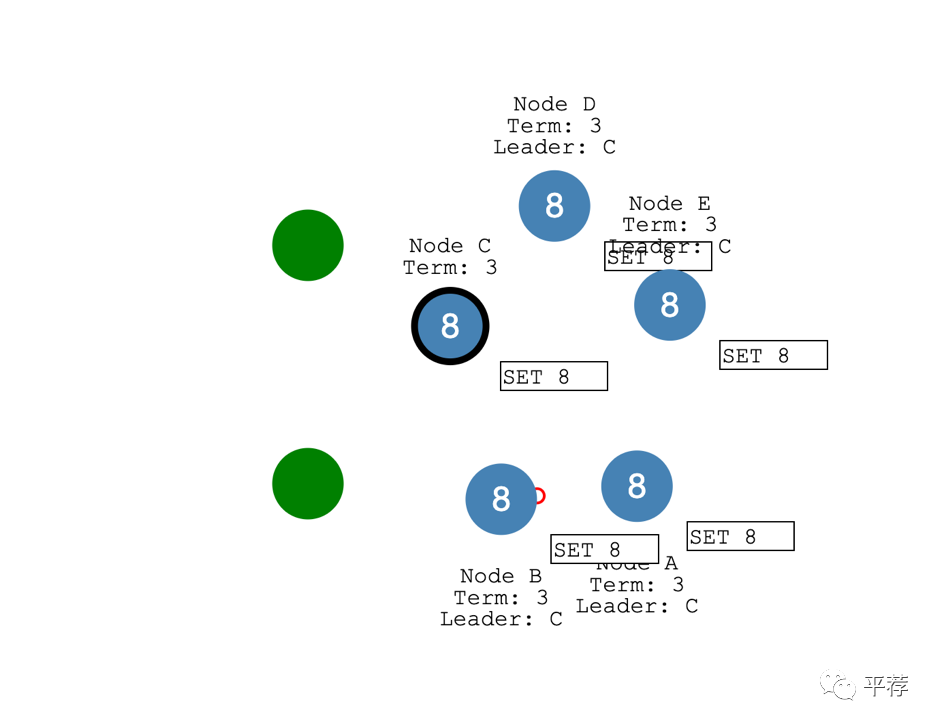
至此日志在整个集群中就是一致的。
最后想说的
好久没更新了,最近工作上有一些变动,所以有时间静下心来整理一下自己的知识图谱~翻译得不好的地方欢迎随时指出来~
