




什么是POD
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。Pod代表着集群中运行的进程。
Pod中封装着应用的容器(有的情况下是好几个容器),存储、独立的网络IP,管理容器如何运行的策略选项。Pod代表着部署的一个单位:kubernetes中应用的一个实例,可能由一个或者多个容器组合在一起共享资源。
在Kubernetes集群中Pod有如下两种使用方式:
一个Pod中运行一个容器。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
在一个Pod中同时运行多个容器。一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位——一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
每个Pod都是应用的一个实例。如果你想平行扩展应用的话(运行多个实例),你应该运行多个Pod,每个Pod都是一个应用实例。在Kubernetes中,这通常被称为replication。
Pod的工作方式
Pod中可以同时运行多个进程(作为容器运行)协同工作。同一个Pod中的容器会自动的分配到同一个 node 上。同一个Pod中的容器共享资源、网络环境和依赖,它们总是被同时调度。
注意在一个Pod中同时运行多个容器是一种比较高级的用法。只有当你的容器需要紧密配合协作的时候才考虑用这种模式。例如,你有一个容器作为web服务器运行,需要用到共享的volume,有另一个“sidecar”容器来从远端获取资源更新这些文件,如下图所示:
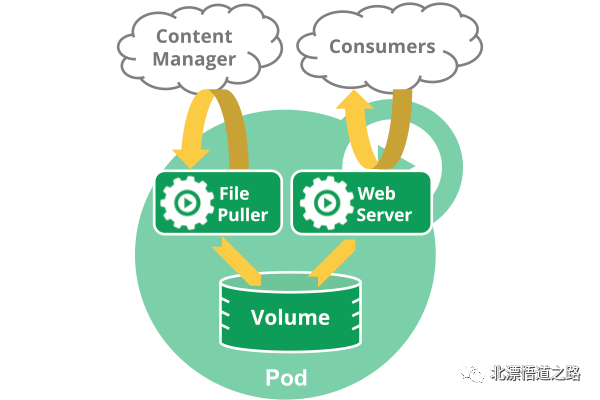
Pod中可以共享两种资源:网络和存储。
网络
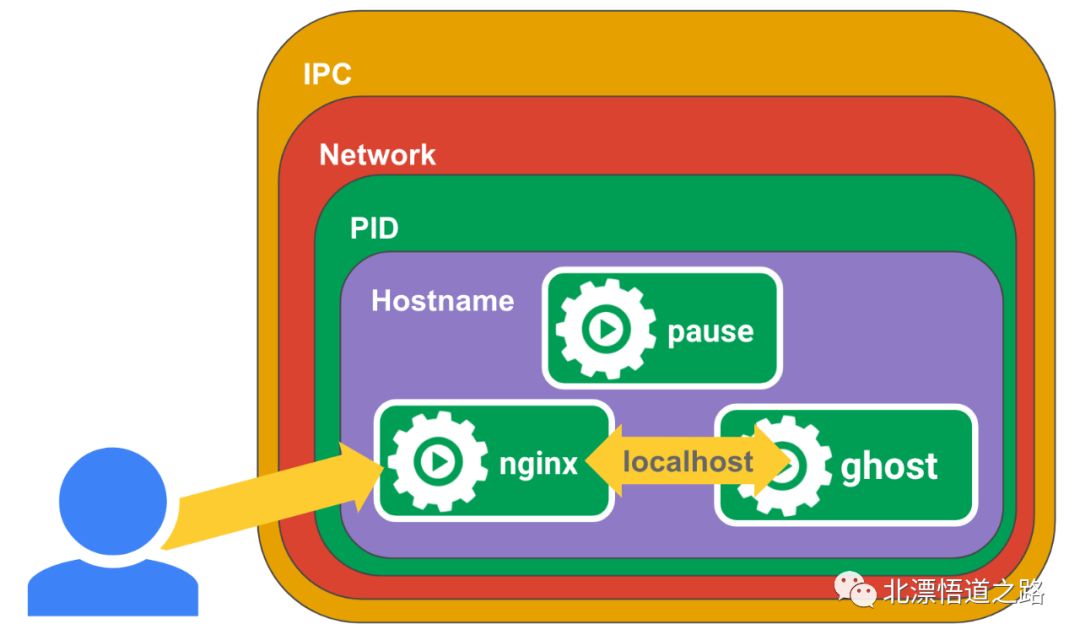
每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。
存储
可以为一个Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
管理
Pod是一个服务的多个进程的聚合单位,pod提供这种模型能够简化应用部署管理,通过提供一个更高级别的抽象的方式。Pod作为一个独立的部署单位,支持横向扩展和复制。共生(协同调度),命运共同体(例如被终结),协同复制,资源共享,依赖管理,Pod都会自动的为容器处理这些问题。
资源共享和通信
Pod中的应用可以共享网络空间(IP地址和端口),因此可以通过localhost互相发现。因此,pod中的应用必须协调端口占用。每个pod都有一个唯一的IP地址,跟物理机和其他pod都处于一个扁平的网络空间中,它们之间可以直接连通。
Pod中应用容器的hostname被设置成Pod的名字。
Pod中的应用容器可以共享volume。Volume能够保证pod重启时使用的数据不丢失。
使用Pod
你很少会直接在kubernetes中创建单个Pod。因为Pod的生命周期是短暂的,用后即焚的实体。当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kubernetes调度到集群的Node上。直到Pod的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在那个Node上。注意:重启Pod中的容器跟重启Pod不是一回事。Pod只提供容器的运行环境并保持容器的运行状态,重启容器不会造成Pod重启。
Pod不会自愈。如果Pod运行的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node缺少资源或者Pod处于维护状态,Pod也会被驱逐。Kubernetes使用更高级的称为Controller的抽象层,来管理Pod实例。虽然可以直接使用Pod,但是在Kubernetes中通常是使用Controller来管理Pod的。
Pod的原理
Pod的持久性(或者说缺乏持久性)
Pod在设计支持就不是作为持久化实体的。在调度失败、节点故障、缺少资源或者节点维护的状态下都会死掉会被驱逐。通常,用户不需要手动直接创建Pod,而是应该使用controller,即使是在创建单个Pod的情况下。Controller可以提供集群级别的自愈功能、复制和升级管理。使用集合API作为主要的面向用户的原语在集群调度系统中相对常见,包括Borg、Marathon、Aurora和Tupperware。
Pod 原语:
调度程序和控制器可插拔性
支持pod级操作,无需通过控制器API“代理”它们
将pod生命周期与控制器生命周期分离,例如用于自举(bootstrap)
控制器和服务的分离——端点控制器只是监视pod
将集群级功能与Kubelet级功能的清晰组合——Kubelet实际上是“pod控制器”
高可用性应用程序,它们可以在终止之前及在删除之前更换pod,例如在计划驱逐、镜像预拉取或实时pod迁移的情况下
StatefulSet控制器支持有状态的Pod。在1.4版本中被称为PetSet。在kubernetes之前的版本中创建有状态pod的最佳方式是创建一个replica为1的replication controller。
Pod的终止
因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够发起一个删除 Pod 的请求,并且知道它们何时会被终止,是否被正确的删除。用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。
示例流程如下:
用户发送删除pod的命令,默认宽限期是30秒;
在Pod超过该宽限期后API server就会更新Pod的状态为“dead”;
在客户端命令行上显示的Pod状态为“terminating”;
跟第三步同时,当kubelet发现pod被标记为“terminating”状态时,开始停止pod进程;
跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
Kubelet会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
删除宽限期默认是30秒。 kubectl delete命令支持 —grace-period=<seconds> 选项,允许用户设置自己的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使用 --force 和 --grace-period=0 来强制删除pod。 在 yaml 文件中可以通过 {{ .spec.spec.terminationGracePeriodSeconds }} 来修改此值。
强制删除Pod
Pod的强制删除是通过在集群和etcd中将其定义为删除状态。当执行强制删除命令时,API server不会等待该pod所运行在节点上的kubelet确认,就会立即将该pod从API server中移除,这时就可以创建跟原pod同名的pod了。这时,在节点上的pod会被立即设置为terminating状态,不过在被强制删除之前依然有一小段优雅删除周期。
强制删除对于某些pod具有潜在危险性,请谨慎使用。
Init镜像
Pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下两点:
Init 容器总是运行到成功完成为止。
每个 Init 容器都必须在下一个 Init 容器启动之前成功完成。
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 为 Never,它不会重新启动。
指定容器为 Init 容器,在 PodSpec 中添加 initContainers 字段,以 v1.Container 类型对象的 JSON 数组的形式,还有 app 的 containers 数组。 Init 容器的状态在 status.initContainerStatuses 字段中以容器状态数组的格式返回(类似 status.containerStatuses 字段)。
Pause容器
Pause容器,又叫Infra容器,本文将探究该容器的作用与原理。
我们知道在kubelet的配置中有这样一个参数:KUBELET_POD_INFRA_CONTAINER=--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest
上面是openshift中的配置参数,kubernetes中默认的配置参数是:KUBELET_POD_INFRA_CONTAINER=--pod-infra-container-image=gcr.io/google_containers/pause-amd64:3.0
Pause容器,是可以自己来定义,官方使用的gcr.io/google_containers/pause-amd64:3.0容器的代码见Github,使用C语言编写。
Pod的生命周期
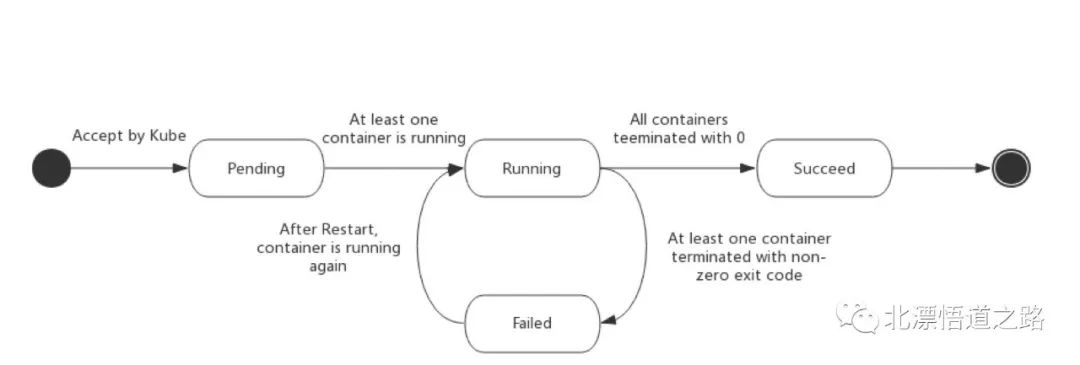
Pod 的 status 字段是一个 PodStatus 对象,PodStatus中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
Pod 相位的数量和含义是严格指定的。除了本文档中列举的状态外,不应该再假定 Pod 有其他的 phase值。
下面是 phase 可能的值:
挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
Pod hook
Pod hook(钩子)是由Kubernetes管理的kubelet发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。可以同时为Pod中的所有容器都配置hook。
Hook的类型包括两种:
exec:执行一段命令
HTTP:发送HTTP请求。
Pod Preset
Pod Preset 是用来在 Pod 被创建的时候向其中注入额外的运行时需求的 API 资源。
您可以使用 label selector来指定为哪些 Pod 应用 Pod Preset。
使用 Pod Preset 使得 pod 模板的作者可以不必为每个 Pod 明确提供所有信息。这样一来,pod 模板的作者就不需要知道关于该服务的所有细节。
自愿中断和非自愿中断
Pod 不会消失,直到有人(人类或控制器)将其销毁,或者当出现不可避免的硬件或系统软件错误。
我们把这些不可避免的情况称为应用的非自愿性中断。例如:
后端节点物理机的硬件故障
集群管理员错误地删除虚拟机(实例)
云提供商或管理程序故障使虚拟机消失
内核恐慌(kernel panic)
节点由于集群网络分区而从集群中消失
由于节点资源不足而将容器逐出
除资源不足的情况外,大多数用户应该都熟悉以下这些情况;它们不是特定于 Kubernetes 的。
我们称这些情况为”自愿中断“。包括由应用程序所有者发起的操作和由集群管理员发起的操作。典型的应用程序所有者操作包括:删除管理该 pod 的 Deployment 或其他控制器
更新了 Deployment 的 pod 模板导致 pod 重启
直接删除 pod(意外删除)
集群管理员操作包括:排空(drain)节点进行修复或升级。
从集群中排空节点以缩小集群(了解集群自动调节)。
从节点中移除一个 pod,以允许其他 pod 使用该节点。
这些操作可能由集群管理员直接执行,也可能由集群管理员或集群托管提供商自动执行。
询问您的集群管理员或咨询您的云提供商或发行文档,以确定是否为您的集群启用了任何自动中断源。如果没有启用,您可以跳过创建 Pod Disruption Budget(Pod 中断预算)。
任职拉勾网,是运维开发部的负责人,长期从事运维开发工作,有多年的运维技能培训经验,培训了多批运维同学,至今大致有300人左右;
发现一问题,好多内容好多年都在重复得讲,没有一个产物直接输出给大家。计划利用空闲时间将多年的知识(分享的内容,包括技能,心得,管理和爱好)沉淀到我的公众号: 北漂悟道之路

感兴趣的同学可以关注一下我的公众号。
技能:擅长python开发,django框架开发,Kubernetes架构、运维开发架构,Linux运维,Hadoop运维和流行监控;了解golang开发和C++开发。
爱好:美食,自驾和旅游
希望了解作者的同学可以加我微信号:XiaoJiaQingShi
