





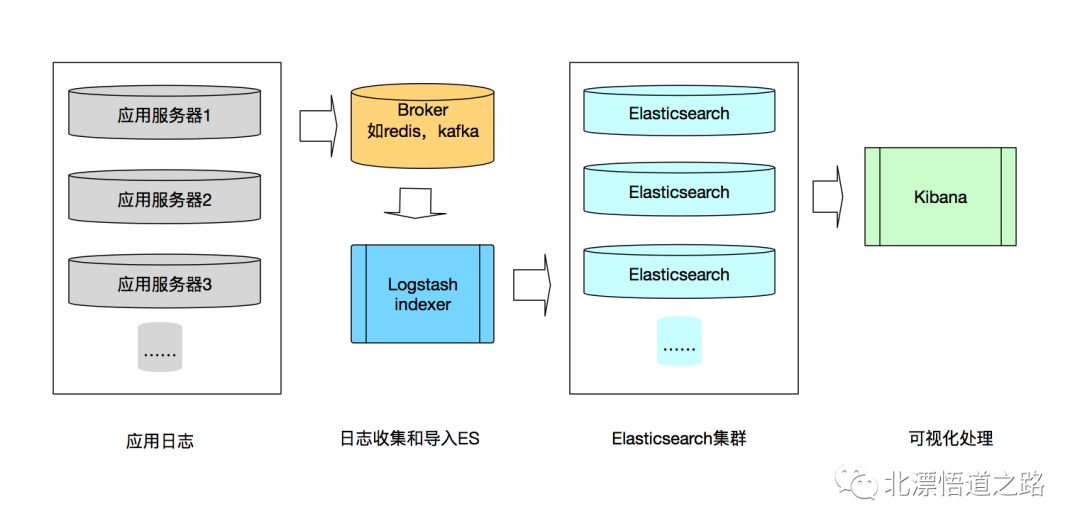
数据也是有流向的,有种模型叫固定的计算,移动的数据。

本系列连载日志系统的相关文章均以日志到kafka再到持久化插件为架构模型作为前提,首先按照上图,应该有一个数据的流向。
在之前的章节讲过日志收集的原理,那么收集起来的日志,是如何传输的呢?
对流式处理有概念的同学应该首先想到的是消息队列,没错,是消息队列(Message Queue)。
常见的消息队列(Message Queue)有哪几种呢?
主要有ctiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ等。
本篇主讲分别从kafka和两种实现讲起。

讲kafka之前,先介绍什么是消息队列。
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环境下的分布式应用提供有效的通信手段。为了管理需要共享的信息,对应用提供公共的信息交换机制是重要的。
常用的消息队列技术是 Message Queue。

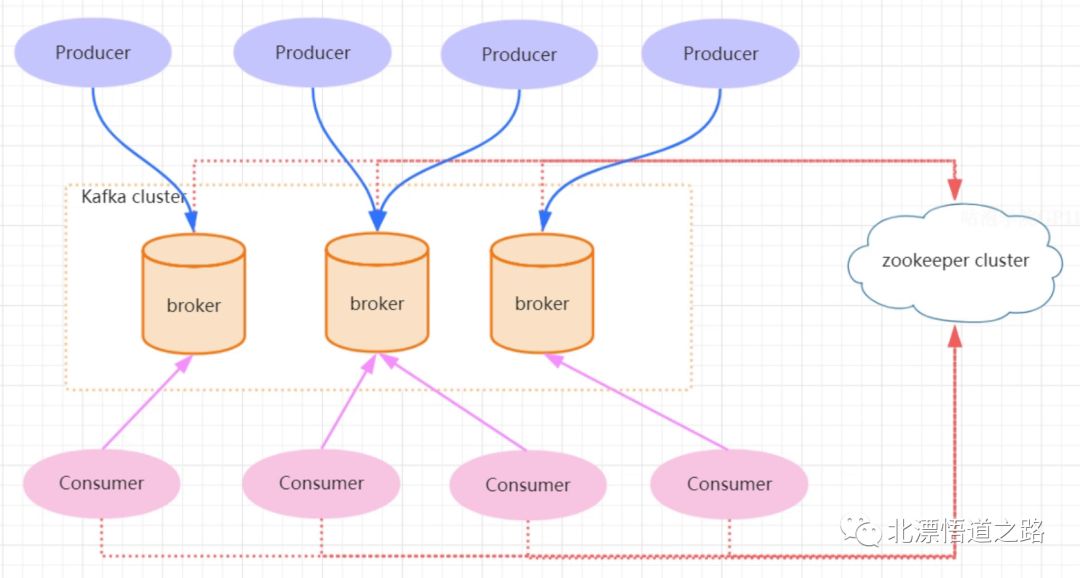
kafka的专业术语
Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。
Producer:负责发布消息到 Kafka broker。
Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。

kafka的交互流程
Kafka 是一个基于分布式的消息发布-订阅系统,它被设计成快速、可扩展的、持久的。与其他消息发布-订阅系统类似,Kafka 在主题当中保存消息的信息。生产者向主题写入数据,消费者从主题读取数据。由于 Kafka 的特性是支持分布式,同时也是基于分布式的,所以主题也是可以在多个节点上被分区和覆盖的。
信息是一个字节数组,程序员可以在这些字节数组中存储任何对象,支持的数据格式包括 String、JSON、Avro。
Kafka 设计中将每一个主题分区当作一个具有顺序排列的日志。

从下图中可以看到数据传输到kafka是produer的事情,基于这个前提,目前存在两种方式实现数据到kafka的发布(推送)。
基于开源软件实现数据灌入kafka(跟第三方API的映射关系难以对应,只是实现数据的推送)。
自研,基于重要关键字可以实现跟第三方API的对接,性能跟开发者水平有关。
在python中通过pykafka.client 的KafkaClient,实现将收集的日志实时的推向kafka的topic,其中可以设置指定的格式,可以是list,可以是json.

推送逻辑代码
1while True:
2 yesteday = (datetime.date.today() - datetime.timedelta(days=1)).strftime("%Y%m%d")
3 if yesteday == today:
4 lc.cleansession(yesteday=yesteday, today=today)
5 today = datetime.datetime.now().strftime('%Y%m%d')
6
7 exit_flag > 0 and signalHander(1, None)
8 file_list = []
9 # Returns a list of files, with absolute path
10 for inputpath in config["basic_conf"]["inputpath"].split(';'):
11 if inputpath is None:
12 continue
13 one_file_list = gfl.getfilelist(inputpath=inputpath, regex=regex)
14 if one_file_list:
15 file_list = file_list + one_file_list
16
17 if not file_list:
18 logging.info("filename list is null")
19 time.sleep(int(config["basic_conf"]["interval"]))
20 continue
21 all_context = ""
22 for filename in file_list:
23 # The incremental information
24 all_context = lc.logcollection(filename=filename,mod='r+',encode='UTF-8')
25 if len(all_context) <= _kf_max_sent_message_length:
26 sendMessage = str_message(filename,all_context)
27 lkp.kfkproducer(sendMessage)
28 else:
29 context = ""
30 list_context = all_context.split('\n')
31 fileline = 1
32 for line in list_context:
33 if line != "" :
34 context += line + "\n"
35 if len(context) > _kf_max_sent_message_length:
36 sendMessage = str_message(filename,context)
37 lkp.kfkproducer(sendMessage)
38 context = ""
39 if len(list_context) == fileline:
40 sendMessage = str_message(filename,context)
41 lkp.kfkproducer(sendMessage)
42 fileline += 1
43
44 exit_flag > 0 and signalHander(1, None)
45 time.sleep(int(config["basic_conf"]["interval"]))



