




本文主要介绍“什么是Raft?“、“我们在什么场景下适合使用Raft?”、“业界使用Raft的一些项目”以及“Raft的局限性”。阅读时间 5 min。

1. 什么是Raft
Raft是一种共识算法(一致性算法),共识算法主要应用在分布式领域,字面意思就是让分布式集群中的各个节点对某些信息或状态达成共识。如果我们在单机环境,是不会存在这个问题的,实际上共识算法也主要应用在分布式系统的高可用方面,即使发生了节点异常,共识算法也可以做到对分布式集群中各个有状态的节点进行状态同步,进而提高系统的整体可用性,让系统中的节点可以给外部上下游服务请求提供一致的反馈。
目前业界大部分共识算法都是基于Quorum机制的,也就是冗余副本选举机制,这个机制是发源于数学中的鸽巢理论,Raft协议、Paxos协议、Zookeeper使用的ZAB协议、Hadoop使用的QJM协议等等,都是基于Quorum机制对不同的场景做出一些取舍而产生的变种,其中Lamport提出的Paxos被认为是分布式一致性复制协议的根本。
Raft协议是由斯坦福大学的Diego Ongaro和John Ousterhout提出,作为RAMCloud项目中的中心协调组件。Raft是一种Leader-Based的Multi-Paxos变种,相比Paxos、Zab、View Stamped Replication等协议提供了更完整更清晰的协议描述,并提供了清晰的节点增删描述,也号称最容易理解的共识算法。
1.1 Raft的前提
Raft其实是基于Paxos协议的一个简化版本,Raft算法的正确性也是基于以下几个前提的:
Strong Leader:原来的leader挂掉后,必须选出一个新的leader,日志复制的顺序也是确定的,必须从Leader流向Follower
日志复制:只接受Leader从客户端接收日志,并复制到整个集群中
安全性:在非拜占庭问题下(网络延时,网络分区,丢包,重复发包以及包乱序等),结果是正确的
1.2 Raft节点以及状态机介绍
Follower:集群中的冗余节点,会对状态机进行冗余
Candidate:准备竞选Leader的节点,希望成为状态机的主理人
Leader:竞选成功的节点,状态机的主理人,处理会改变状态机的Client的请求,在每个时刻只允许存在一个Leader
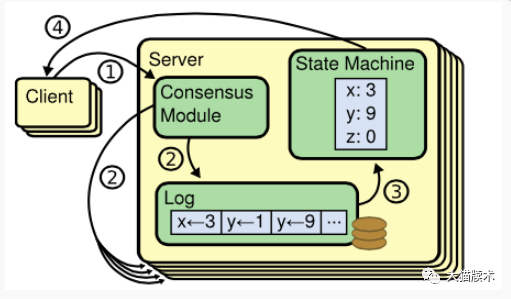
(图片来自Sofa-jraft)
在Raft协议中主要由Leader对状态机进行管理,并把状态机的信息通过日志复制的方式同步给冗余的Follower节点
1.3 Raft选举过程
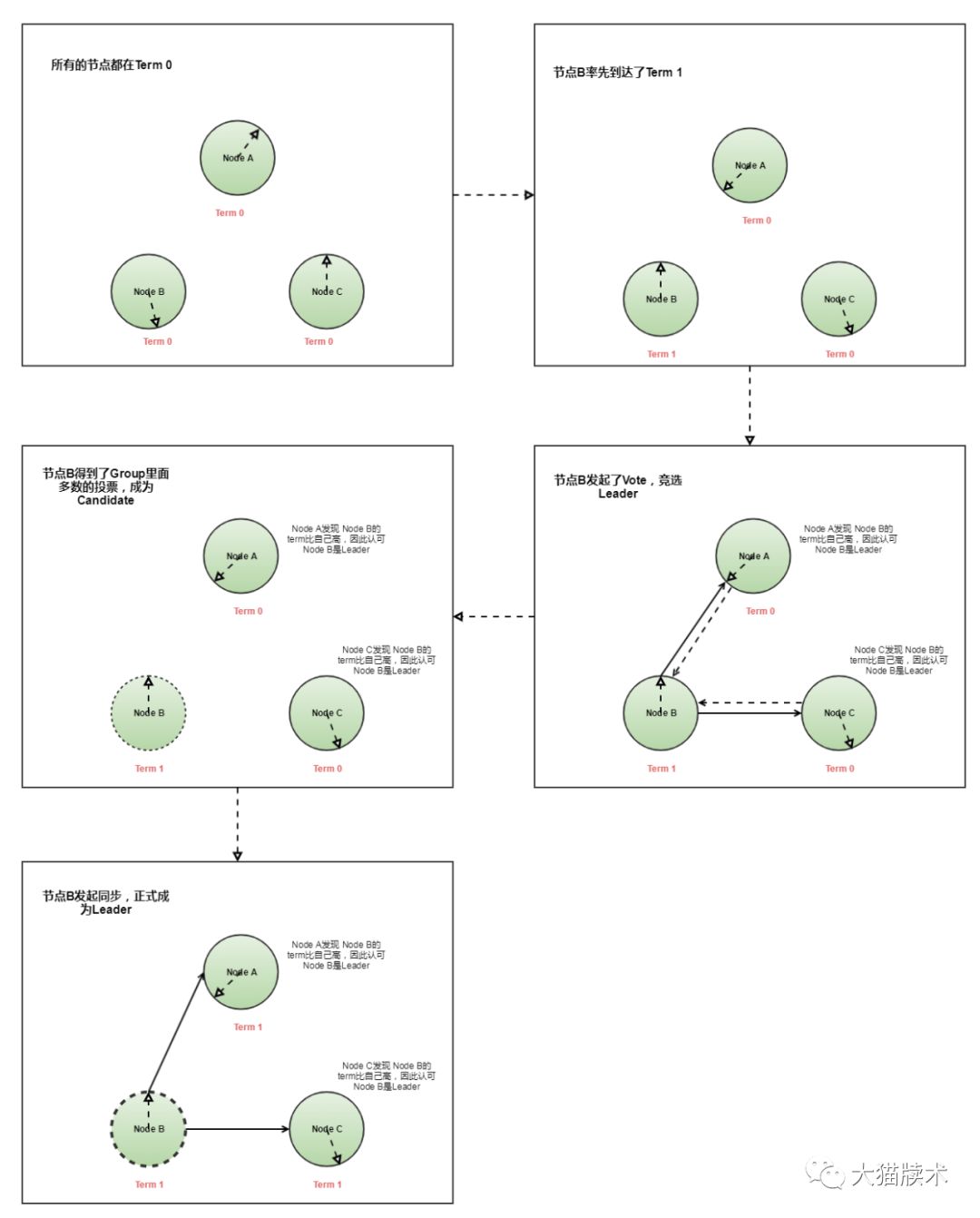
1.4 Raft可以做什么
Raft可以解决分布式理论中的CP,即一致性和分区容忍性,并不能解决Available的问题。但是如果我们在设计中对于做些Consistency的折衷,提供多副本读取来实现高可用,我们可以很容易实现一个BASE模型,通过Raft提供的复制状态机,我们可以实现最终一致性,最终做到整个系统的高可用。Raft可以解决复制、修复、节点管理等问题,极大的简化当前分布式系统的设计与实现,让开发者只关注于业务逻辑,将其抽象实现成对应的状态机即可。基于复制状态机,可以构建很多分布式应用:
分布式锁服务,比如Zookeeper
分布式存储系统,比如分布式消息队列、分布式块系统、分布式文件系统、分布式表格系统等
高可靠元信息管理,比如各类Master模块的HA
解决系统单点问题,通过高效复制来实现单点节点的状态备份
2. Raft在业界的发展
Raft推出之后业界有非常多的企业和项目进行跟进:
CoreOS etcd
hashicorp consul
Facebook Apollo
Facebook hydrabase
Tokutek mongodb
RethinkDB
InfluxDB
cockroachdb
PingCap tidb
3. Raft的弱点
从Raft提出到现在还没有人出来质疑Raft的正确性,但是不可否认Raft是有一些局限的。Raft的局限主要出现在他的几个前提上,这里引用OceanBase为什么在一致性协议的选型中放弃Raft的例子来做描述:
Raft有一个很强的前提就是主(leader)和备(follower)都按顺序投票,为了便于阐述,以数据库事务为例
主库按事务顺序发送事务日志
备库按事务顺序持久化事务和应答主库
主库按事务顺序提交事务
Raft的上述顺序投票策略,是Raft算法的基础之一,如果抛弃它,则Raft算法的正确性无法得到保证。对于数据库之外的场景,上述缺陷可能没有很大的影响,但对于高峰期每秒钟处理成千上万的事务的数据库,是一个无法忽视的潜在性能和稳定性风险。

上图表示提交给数据库的一些事务,
#1-#3为已经持久化和应答的事务日志
#5-#9为已经收到但却不能持久化和应答的事务日志
#4为未收到的事务日志。
由于不同的事务可能被不同工作线程处理,事务日志可能被不同的网络线程发送和接收,因为网络抖动和Linux线程调度等原因,一个备库可能会出现接收到了事务日志#5-#9,但没有接收到事务#4,因此#5-#9的所有事务都需要hold住(在内存),不能持久化,也不能应答主库。出于性能提升的原因,数据库的多版本并发控制(MVCC)使得不存在相互关联的事务得以并发处理,但上述顺序投票策略使得事务#5-#9可能被毫不相干的事务#4阻塞,且必须hold在内存。
另外顺序投票策略也会对数据库的多表事务、故障恢复产生很大影响:
设想一个事务涉及到三张表A,B,C,其中一个事务被顺序投票策略阻塞了,那么表A、B、C上的其他单表和多表事务都会被阻塞,假如A又跟表C、表D有多表事务,B和表E、表F有多表事务,C和表D、表G有多表事务,那么很多表上的事务,包括单表和多表的事务,都会被阻塞,形成一个链式反应,不仅增加事务延迟,甚至可能导致内存耗尽。
由于分布式一致性协议必须有多数派才能正常工作,所以一个参与者故障后,系统应该需要补上一个参与者,确保系统不会因为下一个参与者故障致使多数派协议被破坏,从而导致已经应答了客户的事务数据的丢失等非常严重的问题。由于单台服务器通常服务成千上万的表格,对每个表格分别写事务日志(redo log)会导致很低的性能,而从混合在一起的事务日志中提取部分表格的日志有不小的工作量,从而导致新的参与者的延迟。
