




Impala
Impala 是Cloudera开源的一款用来进行大数据实时查询分析的开源工具,它能够实现通过SQL语句来操作大数据,数据可以是存储到HDFS、HBase或者是Kudu中的。
1. 简介
Impala 是由Cloudera受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,它以C++实现,整体采用跟GP一样的MPP(Massive Parallel Processing)架构,Impala在发出了paper 《Impala: A Modern, Open-Source SQL Engine for Hadoop》。Impala是一个内存计算模型,在计算时会把计算尽可能的放入内存中,Impala官方建议内存要至少128G以上,并且把80%内存分配给Impala。
在实际各种生产环境实践中,Impala也被认为不能完全替代Hive,Hive适合于长时间大数据量的查询分析,而Impala适合于实时Ad-Hoc SQL查询(跟GP场景高度重合,详见Cloudera宣传页,CDH自己也是对标GP的。Tuning Impala_ The top five performance optimizations for the best BI and SQL analytics on Hadoop Presentation.pdf)。
2. Benchmark
MR3(韩国浦项大学推出的一个调优后的MR框架)用TPC-DS跑了一个10TB数据量大小的Benchmark,对比了Hive、Presto以及Impala
Impala on CDH 5.15.2 | Hive 3.1.1 on MR3 0.6 | Presto 0.217 | |
|---|---|---|---|
| Time | 7026.18 | 12249.714 | 24467.39 |
| Succeed | 59 | 99 | 95 |
表格中飘红的单元格表示查询失败了
Query ID | Impala on CDH 5.15.2 | Hive 3.1.1 on MR3 0.6 | Presto 0.217 |
|---|---|---|---|
| query 1 | 31.86 | 22.269 | 34.817 |
| query 2 | 34.52 | 27.405 | 287.385 |
| query 3 | 2.62 | 8.482 | 38.384 |
| query 4 | 375.65 | 796.016 | 488.678 |
| query 5 | 0 | 51.178 | 287.52 |
| query 6 | 0 | 14.1 | 29.708 |
| query 7 | 5.44 | 21.009 | 168.616 |
| query 8 | 0 | 10.371 | 67.999 |
| query 9 | 0 | 68.563 | 255.255 |
| query 10 | 0 | 41.841 | 45.519 |
| query 11 | 351.23 | 477.092 | 321.133 |
| query 12 | 0 | 10.724 | 12.603 |
| query 13 | 107.44 | 25.366 | 122.245 |
| query 14 | 0 | 359.036 | 1999.51 |
| query 15 | 26.31 | 15.091 | 20.471 |
| query 16 | 0 | 58.347 | 122.453 |
| query 17 | 87.72 | 74.318 | 280.14 |
| query 18 | 0 | 39.109 | 45.935 |
| query 19 | 4.26 | 13.168 | 72.181 |
| query 20 | 0 | 12.195 | 15.832 |
| query 21 | 0 | 8.682 | 5.3 |
| query 22 | 0 | 23.681 | 9.354 |
| query 23 | 0 | 1896.566 | 2591.82 |
| query 24 | 0 | 1369.523 | 801.727 |
| query25 | 29.58 | 68.046 | 279.394 |
| query 26 | 4.05 | 13.975 | 177.605 |
| query 27 | 0 | 20.408 | 61.978 |
| query 28 | 28.14 | 63.874 | 324.3 |
| query 29 | 31.22 | 110.31 | 323.403 |
| query 30 | 19.93 | 34.665 | 15.671 |
| query 31 | 33.45 | 48.445 | 142.144 |
| query 32 | 0 | 9.154 | 40.555 |
| query 33 | 8.27 | 14.386 | 98.467 |
| query 34 | 69.6 | 19.671 | 61.18 |
| query 35 | 0 | 69.541 | 50.54 |
| query 36 | 0 | 24.434 | 63.94 |
| query 37 | 0 | 14.685 | 16.686 |
| query 38 | 0 | 140.744 | 177.3 |
| query 39 | 18.23 | 50.05 | 37.977 |
| query 40 | 0 | 13.535 | 144.947 |
| query 41 | 1.22 | 2.092 | 2.265 |
| query 42 | 1.1 | 4.964 | 112.64 |
| query 43 | 27.32 | 17.415 | 38.844 |
| query 44 | 0 | 71.211 | 252.321 |
| query 45 | 0 | 15.078 | 16.112 |
| query 46 | 6.59 | 18.976 | 62.357 |
| query 47 | 275.97 | 63.088 | 372.109 |
| query 48 | 5.21 | 17.79 | 58.134 |
| query 49 | 0 | 49.885 | 611.262 |
| query 50 | 53.53 | 273.198 | 72.74 |
| query 51 | 134.55 | 63.315 | 74.938 |
| query 52 | 1.32 | 4.53 | 115.632 |
| query 53 | 3.02 | 12.013 | 41.308 |
| query 54 | 0 | 42.095 | 211.264 |
| query 55 | 1.22 | 4.398 | 31.707 |
| query 56 | 2.47 | 7.764 | 70.353 |
| query 57 | 161.66 | 43.622 | 217.402 |
| query 58 | 0 | 13.789 | 224.299 |
| query 59 | 52.95 | 40.451 | 187.184 |
| query 60 | 8.1 | 20.745 | 174.798 |
| query 61 | 54.4 | 15.137 | 216.556 |
| query 62 | 32.81 | 23.737 | 30.303 |
| query 63 | 2.93 | 11.987 | 169.94 |
| query 64 | 682.73 | 349.591 | -199.823 |
| query 65 | 252.7 | 341.844 | 395.3 |
| query 66 | 0 | 20.301 | 47.811 |
| query 67 | 0 | 976.214 | 5152.285 |
| query 68 | 10.15 | 11.844 | 64.817 |
| query 69 | 20.08 | 35.902 | 41.848 |
| query 70 | 0 | 47.491 | 176.812 |
| query 71 | 85.03 | 19.919 | 82.468 |
| query 72 | 0 | 71.645 | -210.708 |
| query 73 | 5.4 | 6.973 | 39.726 |
| query 74 | 210.93 | 370.221 | 527.808 |
| query 75 | 329.79 | 176.646 | 760.535 |
| query 76 | 25.04 | 60.291 | 124.438 |
| query 77 | 0 | 15.6 | 165.814 |
| query 78 | 2107.93 | 1308.21 | -192.269 |
| query 79 | 46.46 | 24.463 | 162.553 |
| query 80 | 0 | 30.929 | -157.228 |
| query 81 | 14.39 | 35.906 | 58.801 |
| query 82 | 0 | 21.97 | 23.48 |
| query 83 | 36.13 | 10.275 | 25.714 |
| query 84 | 0 | 8.941 | 5.699 |
| query 85 | 79.54 | 22.706 | 282.752 |
| query 86 | 0 | 13.588 | 18.946 |
| query 87 | 0 | 153.491 | 122.58 |
| query 88 | 43.26 | 44.965 | 220.993 |
| query 89 | 12.29 | 14.815 | 43.95 |
| query 90 | 3.44 | 16.667 | 19.72 |
| query 91 | 1.98 | 4.942 | 4.712 |
| query 92 | 0 | 8.2 | 65.499 |
| query 93 | 486.99 | 483.914 | 351.724 |
| query 94 | 0 | 58.492 | 203.566 |
| query 95 | 0 | 111.842 | 507.821 |
| query 96 | 5.72 | 27.919 | 26.341 |
| query 97 | 399.93 | 292.527 | 378.682 |
| query 98 | 0 | 14.901 | 49.851 |
| query 99 | 70.38 | 38.234 | 49.176 |
https://mr3.postech.ac.kr/blog/2019/03/22/performance-evaluation-0.6/
通过这个Benchmark我们可以看到Impala在一些场景下会比Hive快很多,但是在大数据量情况下表现不是很稳定(这也跟基于内存计算有关),维护门槛和使用门槛都比较高。
| Pros | Cons |
|---|---|
|
|
3. 架构要点
Impala的架构设计视图,如图所示:
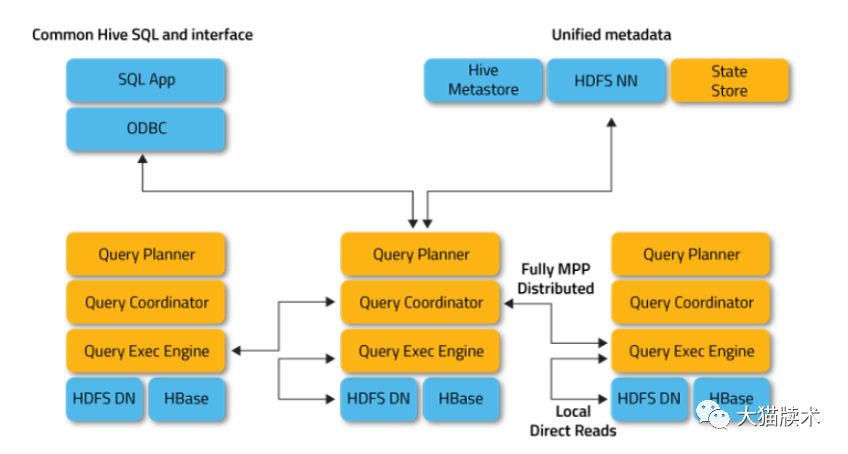
上面可以看出,位于Datanode上的每个impalad进程,都具有Query Planner、Query Coordinator、Query Exec Engine这几个组件,每个Impala节点在功能集合上是对等的,也就是说,任何一个节点都能接收外部查询请求。当有一个节点发生故障后,其他节点仍然能够接管,这还要得益于,在HDFS上,数据的副本是冗余的,只要数据能够取到,某些挂掉的impalad进程所在节点的数据,在整个HDFS中只要还存在副本(impalad进程正常的节点),还是可以提供计算的。除非,当多个impalad进程挂掉了,恰好此时的查询请求要操作的数据所在的节点,都没有存在impalad进程,这次Query就会失败。
